Department of Biostatistics, School of Public Health, Shandong University, 44 Wen Hua Xi Road, Jinan, 250012, China.
Department of Breast Surgery, the Second Hospital of Shandong University, Jinan, 250033, China.
BMC Cancer. 2019 Feb 7;19(1):128. doi: 10.1186/s12885-019-5321-1.
Considering the lack of efficient breast cancer prediction models suitable for general population screening in China. We aimed to develop a risk prediction model to identify high-risk populations, to help with primary prevention of breast cancer among Han Chinese women.
A cause-specific competing risk model was used to develop the Han Chinese Breast Cancer Prediction model. Data from the Shandong Case-Control Study (328 cases and 656 controls) and Taixing Prospective Cohort Study (13,176 participants) were used to develop and validate the model. The expected/observed (E/O) ratio and C-statistic were calculated to evaluate calibration and discriminative accuracy of the model, respectively.
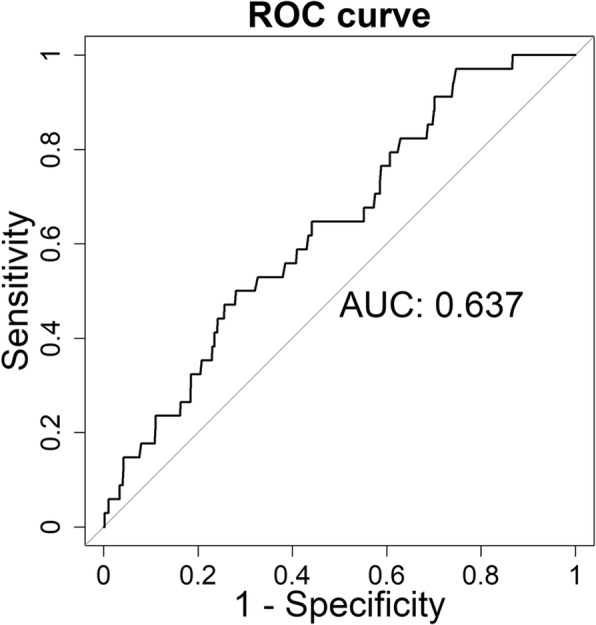
Compared with the reference level, the relative risks (RRs) for highest level of number of abortions, age at first live birth, history of benign breast disease, body mass index (BMI), family history of breast cancer, and life satisfaction scores were 6.3, 3.6, 4.3, 1.9, 3.3, 2.4, respectively. The model showed good calibration and discriminatory accuracy with an E/O ratio of 1.03 and C-statistic of 0.64.
We developed a risk prediction model including fertility status and relevant disease history, as well as other modifiable risk factors. The model demonstrated good calibration and discrimination ability.
考虑到缺乏适用于中国一般人群筛查的有效乳腺癌预测模型,我们旨在开发一种风险预测模型,以识别高危人群,帮助汉族妇女进行乳腺癌的一级预防。
采用特定原因竞争风险模型来开发汉族乳腺癌预测模型。该模型的数据来源于山东病例对照研究(328 例病例和 656 例对照)和泰兴前瞻性队列研究(13176 名参与者),用于模型的开发和验证。通过计算预期/观察(E/O)比值和 C 统计量来评估模型的校准度和区分度准确性。
与参考水平相比,堕胎次数最高水平、首次活产年龄、良性乳腺疾病史、体重指数(BMI)、乳腺癌家族史和生活满意度评分的相对风险(RR)分别为 6.3、3.6、4.3、1.9、3.3、2.4。该模型的 E/O 比值为 1.03,C 统计量为 0.64,具有良好的校准度和区分度准确性。
我们开发了一种包括生育状况和相关疾病史以及其他可改变的风险因素的风险预测模型。该模型具有良好的校准和区分能力。