Department of Physical Geography and Ecosystem Science, Lund University, Sölvegatan 12, SE-223 62, Lund, Sweden.
Department of Geosciences and Natural Resource Management, University of Copenhagen, 1350, Copenhagen, Denmark.
Sci Rep. 2019 Mar 4;9(1):3367. doi: 10.1038/s41598-019-38976-y.
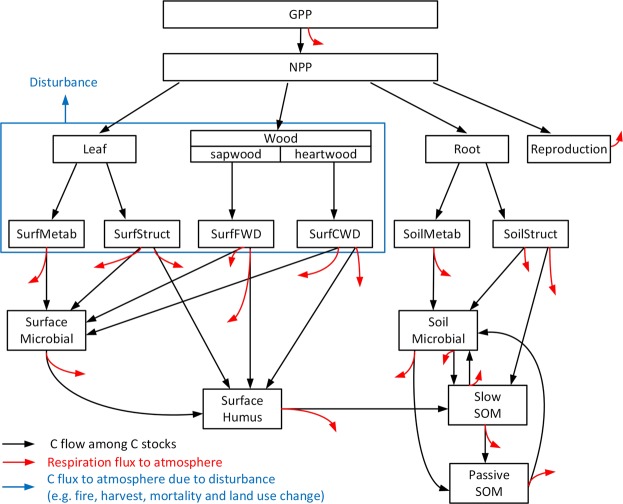
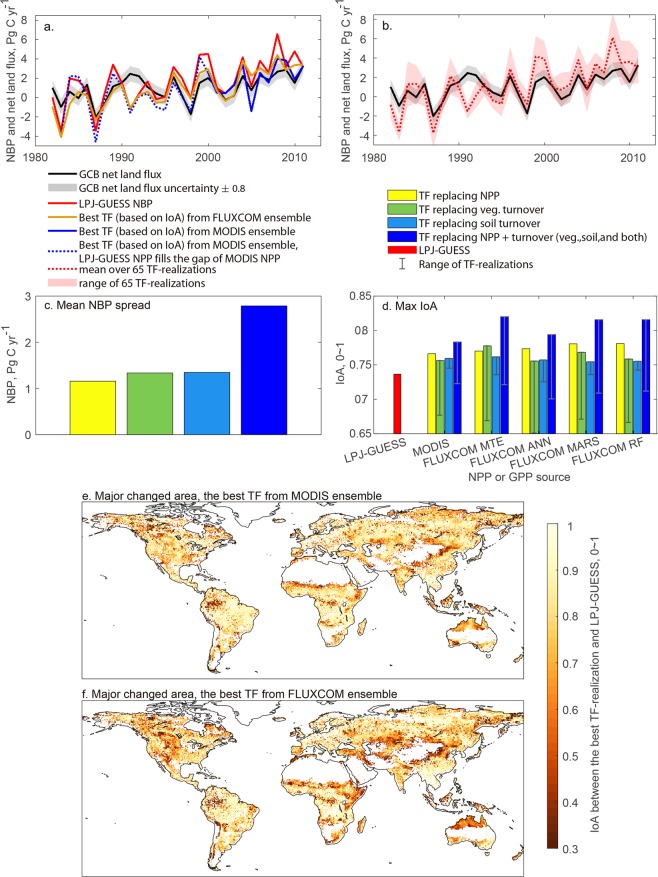
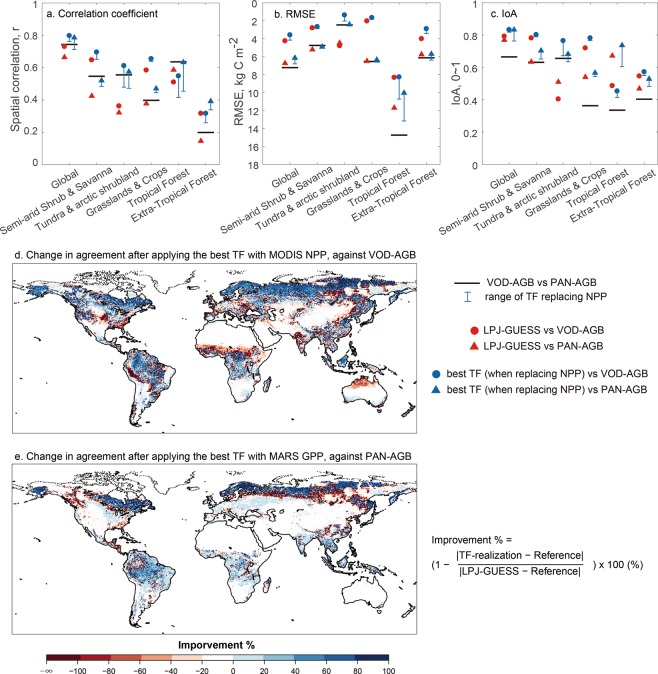
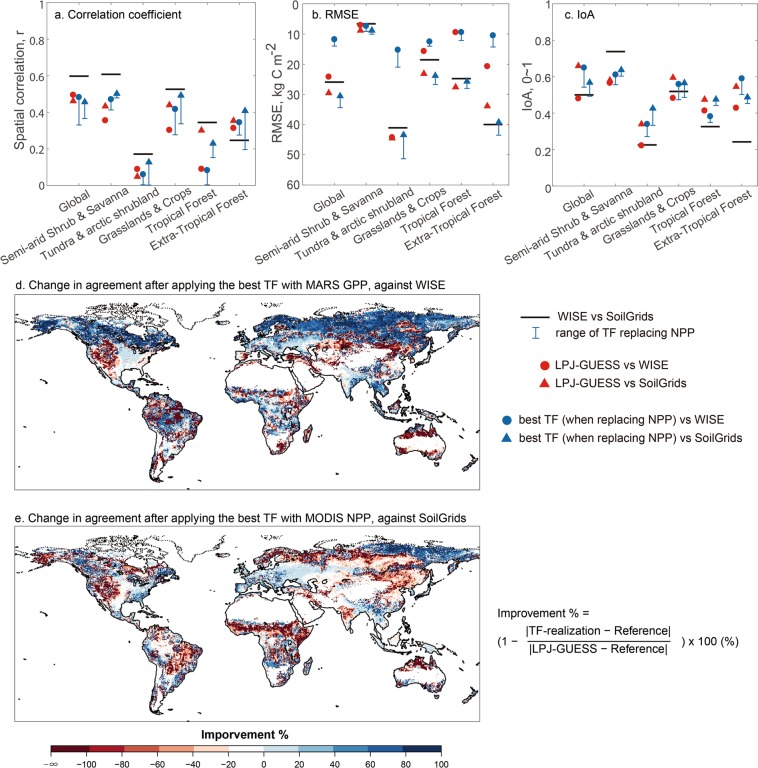
Carbon storage dynamics in vegetation and soil are determined by the balance of carbon influx and turnover. Estimates of these opposing fluxes differ markedly among different empirical datasets and models leading to uncertainty and divergent trends. To trace the origin of such discrepancies through time and across major biomes and climatic regions, we used a model-data fusion framework. The framework emulates carbon cycling and its component processes in a global dynamic ecosystem model, LPJ-GUESS, and preserves the model-simulated pools and fluxes in space and time. Thus, it allows us to replace simulated carbon influx and turnover with estimates derived from empirical data, bringing together the strength of the model in representing processes, with the richness of observational data informing the estimations. The resulting vegetation and soil carbon storage and global land carbon fluxes were compared to independent empirical datasets. Results show model-data agreement comparable to, or even better than, the agreement between independent empirical datasets. This suggests that only marginal improvement in land carbon cycle simulations can be gained from comparisons of models with current-generation datasets on vegetation and soil carbon. Consequently, we recommend that model skill should be assessed relative to reference data uncertainty in future model evaluation studies.
植被和土壤中的碳储存动态取决于碳流入和周转的平衡。这些相反通量的估计在不同的经验数据集和模型之间存在显著差异,导致不确定性和不同的趋势。为了追溯这些差异的起源,我们使用了模型-数据融合框架。该框架模拟了全球动态生态系统模型 LPJ-GUESS 中的碳循环及其组成过程,并在空间和时间上保存了模型模拟的碳库和通量。因此,它允许我们用来自经验数据的估计值来替代模拟的碳流入和周转,将模型在代表过程方面的优势与为估计提供信息的观测数据的丰富性结合起来。由此产生的植被和土壤碳储量以及全球陆地碳通量与独立的经验数据集进行了比较。结果表明,模型-数据的一致性与独立经验数据集之间的一致性相当,甚至更好。这表明,仅通过将模型与当前一代植被和土壤碳数据集进行比较,就可以对陆地碳循环模拟进行微小的改进。因此,我们建议在未来的模型评估研究中,应根据参考数据的不确定性来评估模型的性能。