Department of Pharmaceutical Biosciences, Uppsala University, Uppsala, Sweden.
Faculty of Medicine and University Hospital Cologne, Center for Pharmacology, Department I of Pharmacology, University of Cologne, Gleueler Str 24, 50931, Cologne, Germany.
J Pharmacokinet Pharmacodyn. 2019 Jun;46(3):241-250. doi: 10.1007/s10928-019-09632-9. Epub 2019 Apr 9.
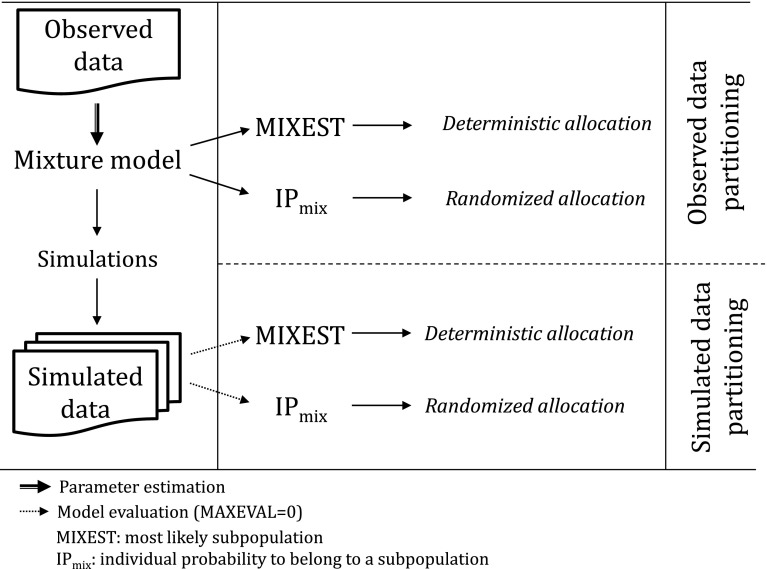
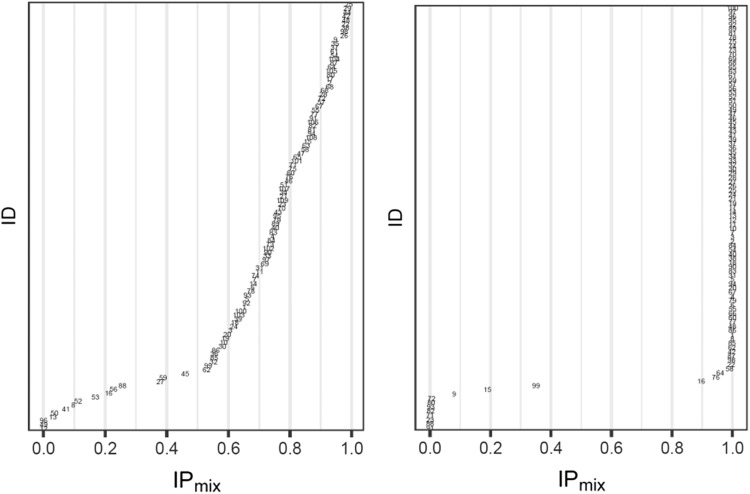
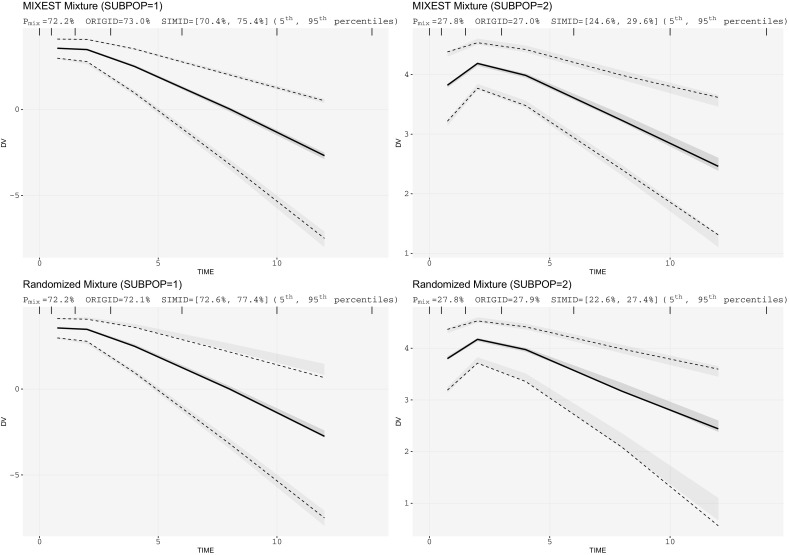
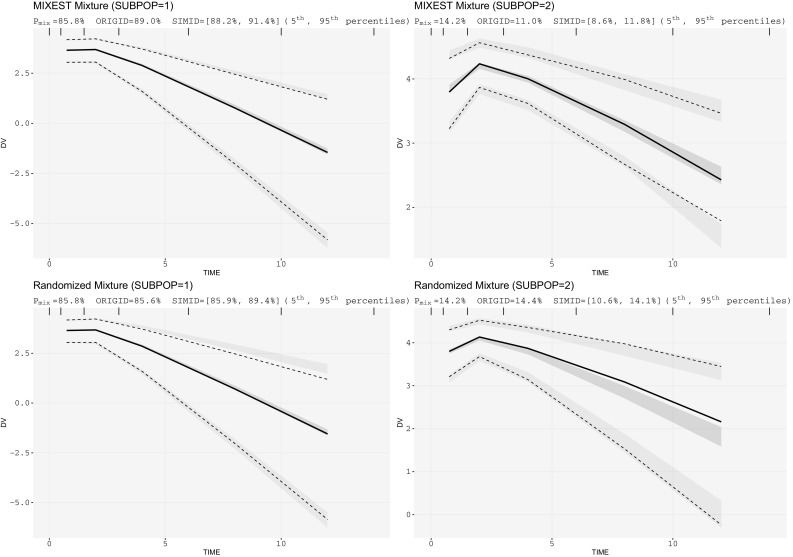
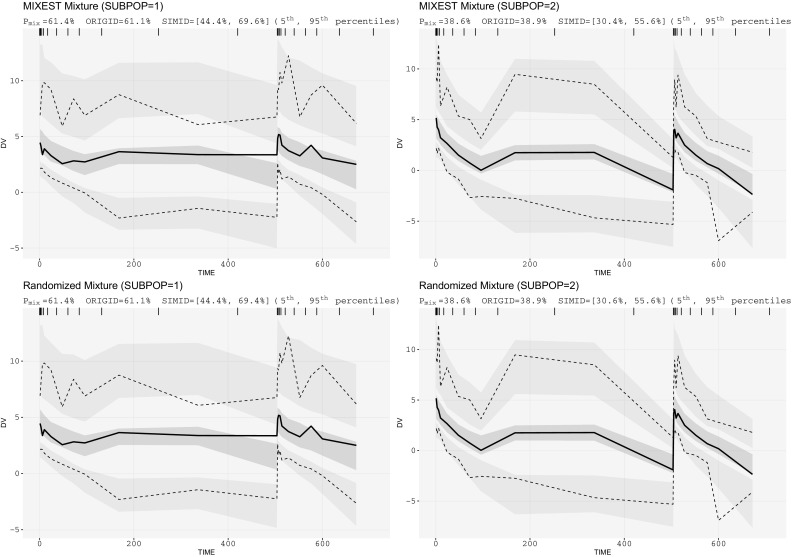
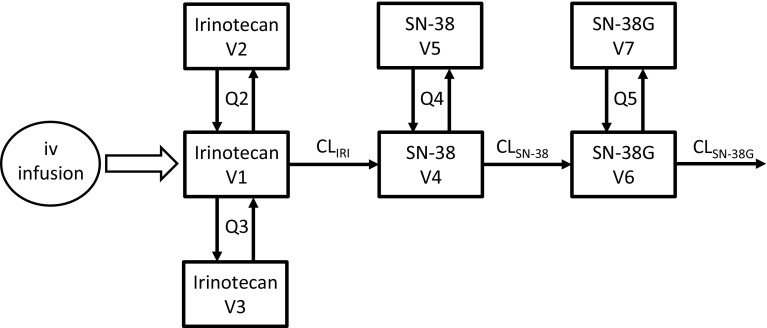
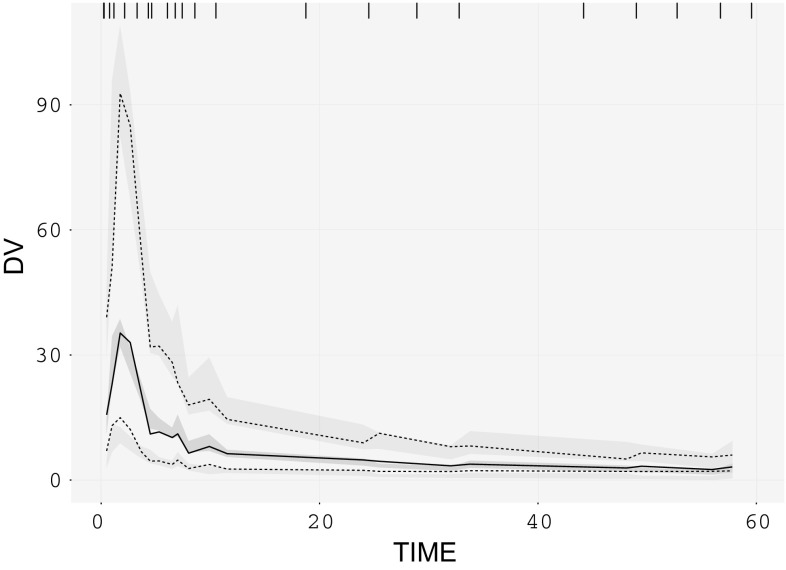
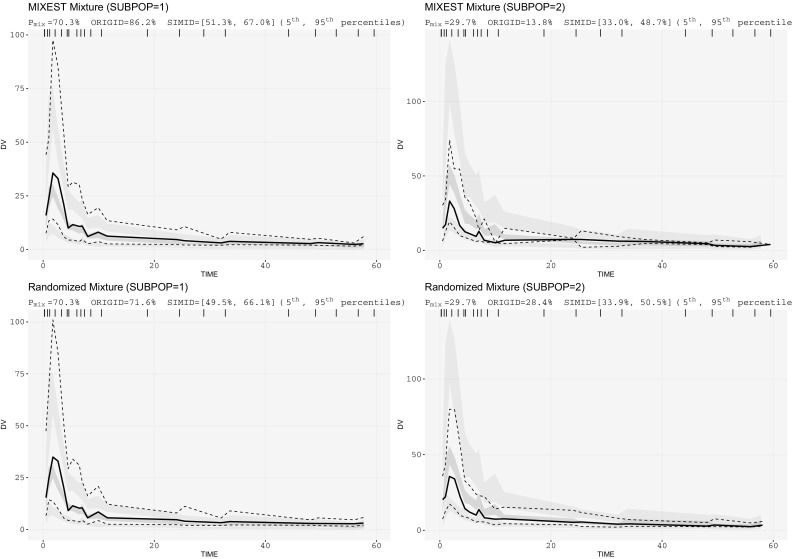
The assumption of interindividual variability being unimodally distributed in nonlinear mixed effects models does not hold when the population under study displays multimodal parameter distributions. Mixture models allow the identification of parameters characteristic to a subpopulation by describing these multimodalities. Visual predictive check (VPC) is a standard simulation based diagnostic tool, but not yet adapted to account for multimodal parameter distributions. Mixture model analysis provides the probability for an individual to belong to a subpopulation (IP) and the most likely subpopulation for an individual to belong to (MIXEST). Using simulated data examples, two implementation strategies were followed to split the data into subpopulations for the development of mixture model specific VPCs. The first strategy splits the observed and simulated data according to the MIXEST assignment. A shortcoming of the MIXEST-based allocation strategy was a biased allocation towards the dominating subpopulation. This shortcoming was avoided by splitting observed and simulated data according to the IP assignment. For illustration purpose, the approaches were also applied to an irinotecan mixture model demonstrating 36% lower clearance of irinotecan metabolite (SN-38) in individuals with UGT1A1 homo/heterozygote versus wild-type genotype. VPCs with segregated subpopulations were helpful in identifying model misspecifications which were not evident with standard VPCs. The new tool provides an enhanced power of evaluation of mixture models.
当研究人群的参数分布呈多峰时,非线性混合效应模型中个体间变异呈单峰分布的假设不成立。混合模型通过描述这些多峰性来识别与亚群相关的参数。可视化预测检查(VPC)是一种标准的基于模拟的诊断工具,但尚未适应于多峰参数分布。混合模型分析提供了个体属于亚群的概率(IP)和个体最有可能属于的亚群(MIXEST)。使用模拟数据示例,遵循了两种实施策略将数据分为亚群,以开发特定于混合模型的 VPC。第一种策略是根据 MIXEST 分配将观察数据和模拟数据分开。基于 MIXEST 的分配策略的一个缺点是偏向于主导亚群的分配。通过根据 IP 分配将观察数据和模拟数据分开,可以避免这种缺点。出于说明目的,这些方法也应用于伊立替康混合模型,该模型表明,UGT1A1 同/杂合子与野生型基因型个体中伊立替康代谢物(SN-38)的清除率低 36%。带有隔离亚群的 VPC 有助于识别标准 VPC 不明显的模型误定。该新工具提供了增强混合模型评估的能力。