Department of Integrative Biology and Evolution, Research Institute of Wildlife Ecology, Vetmeduni Vienna, Vienna, Austria.
Intelligent Systems Laboratory, University of Bristol, Bristol, UK.
Mol Ecol Resour. 2019 Jul;19(4):1015-1026. doi: 10.1111/1755-0998.13020. Epub 2019 May 17.
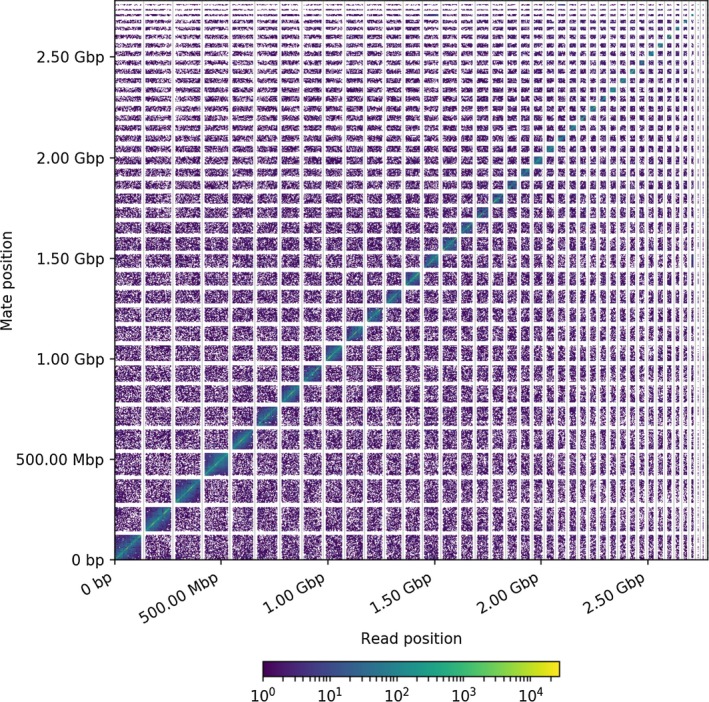
Researchers have assembled thousands of eukaryotic genomes using Illumina reads, but traditional mate-pair libraries cannot span all repetitive elements, resulting in highly fragmented assemblies. However, both chromosome conformation capture techniques, such as Hi-C and Dovetail Genomics Chicago libraries and long-read sequencing, such as Pacific Biosciences and Oxford Nanopore, help span and resolve repetitive regions and therefore improve genome assemblies. One important livestock species of arid regions that does not have a high-quality contiguous reference genome is the dromedary (Camelus dromedarius). Draft genomes exist but are highly fragmented, and a high-quality reference genome is needed to understand adaptation to desert environments and artificial selection during domestication. Dromedaries are among the last livestock species to have been domesticated, and together with wild and domestic Bactrian camels, they are the only representatives of the Camelini tribe, which highlights their evolutionary significance. Here we describe our efforts to improve the North African dromedary genome. We used Chicago and Hi-C sequencing libraries from Dovetail Genomics to resolve the order of previously assembled contigs, producing almost chromosome-level scaffolds. Remaining gaps were filled with Pacific Biosciences long reads, and then scaffolds were comparatively mapped to chromosomes. Long reads added 99.32 Mbp to the total length of the new assembly. Dovetail Chicago and Hi-C libraries increased the longest scaffold over 12-fold, from 9.71 Mbp to 124.99 Mbp and the scaffold N50 over 50-fold, from 1.48 Mbp to 75.02 Mbp. We demonstrate that Illumina de novo assemblies can be substantially upgraded by combining chromosome conformation capture and long-read sequencing.
研究人员已经使用 Illumina reads 组装了数千个真核生物基因组,但传统的 mate-pair 文库无法跨越所有重复元件,导致组装结果高度碎片化。然而,包括 Hi-C 和 Dovetail Genomics Chicago 文库在内的染色体构象捕获技术,以及 Pacific Biosciences 和 Oxford Nanopore 在内的长读测序技术,都有助于跨越和解决重复区域,从而改善基因组组装。干旱地区有一种重要的家畜物种——单峰驼(Camelus dromedarius),但它没有高质量的连续参考基因组。目前虽然有基因组草图,但它们高度碎片化,需要高质量的参考基因组来了解单峰驼对沙漠环境的适应以及在驯化过程中的人工选择。单峰驼是最后一批被驯化的家畜之一,与野生和家养双峰驼一起,它们是 Camelini 部落的唯一代表,这凸显了它们的进化意义。在这里,我们描述了我们改进北非单峰驼基因组的努力。我们使用 Dovetail Genomics 的 Chicago 和 Hi-C 测序文库来确定先前组装的 contigs 的顺序,生成了几乎染色体级别的支架。利用 Pacific Biosciences 的长读序列填补了剩余的缺口,然后将支架与染色体进行比较映射。长读序列为新组装体的总长度增加了 99.32 Mbp。Dovetail Chicago 和 Hi-C 文库将最长支架的长度增加了 12 倍以上,从 9.71 Mbp 增加到 124.99 Mbp,支架 N50 增加了 50 多倍,从 1.48 Mbp 增加到 75.02 Mbp。我们证明,通过结合染色体构象捕获和长读测序,可以显著升级 Illumina 从头组装。