Hartwell Micah L, Khojasteh Jam, Wetherill Marianna S, Croff Julie M, Wheeler Denna
School of Community Health Sciences, Counseling and Counseling Psychology, Oklahoma State University, Stillwater, OK.
School of Education Foundations, Leadership and Aviation, Oklahoma State University, Stillwater, OK.
Curr Dev Nutr. 2019 Feb 4;3(5):nzz010. doi: 10.1093/cdn/nzz010. eCollection 2019 May.
Structural equation modeling (SEM) is a multivariate analysis method for exploring relations between latent constructs and measured variables. As a theory-guided approach, SEM estimates directional pathways in complex models based on longitudinal or cross-sectional data where randomized control trials would either be unethical or cost prohibitive. However, this method is infrequently used in nutrition research, despite recommendations by epidemiologists for its increased use.
The aim of this study was to explore 3 key methodologic areas for consideration by researchers when conducting SEM with complex survey datasets: the use of sampling weights, treatment of missing data, and model estimation techniques.
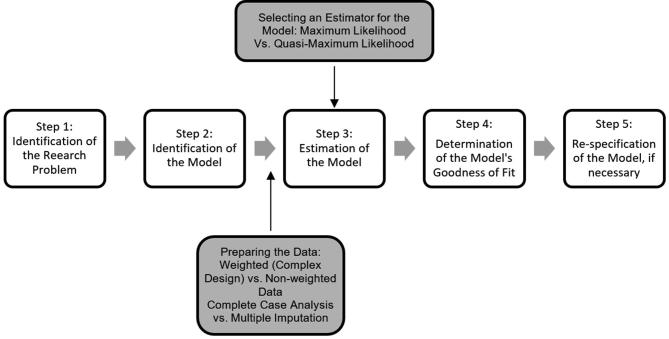
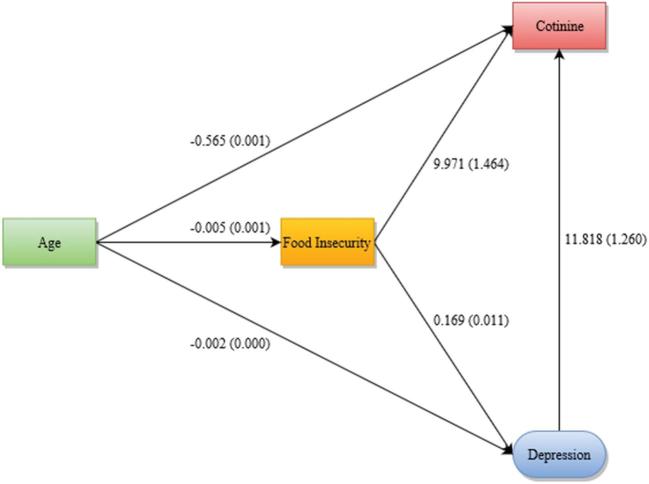
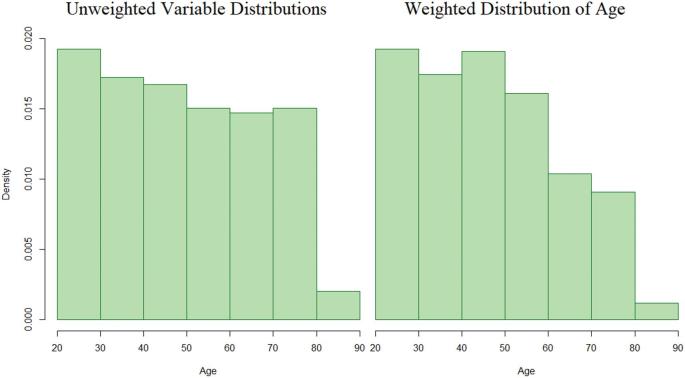
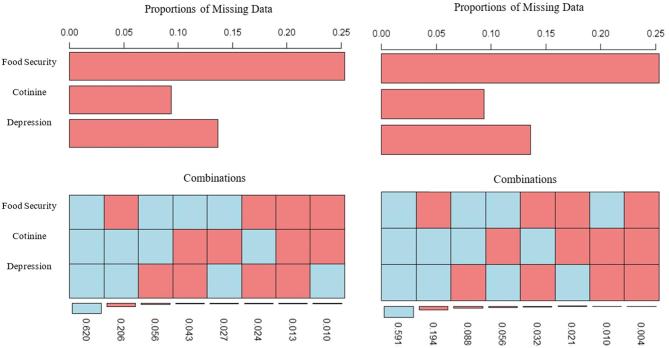
With the use of data from NHANES waves 2005-2010, we developed an SEM to estimate the relation between the latent construct of depression and measured variables of food security, tobacco use (serum cotinine), and age. We used a hierarchic approach to compare 5 SEM model iterations through the use of: and ) complete cases without and with the application of sampling weights; ) an applied missingness dataset to test the accuracy of multiple imputation (MI); 4) the full NHANES dataset with imputed data and sampling weights; and ) a final respecified model. Each iteration was conducted with maximum likelihood (ML) and quasimaximum likelihood with the Satorra-Bentler correction (QML) to compare path coefficients, standard errors, and model fit statistics.
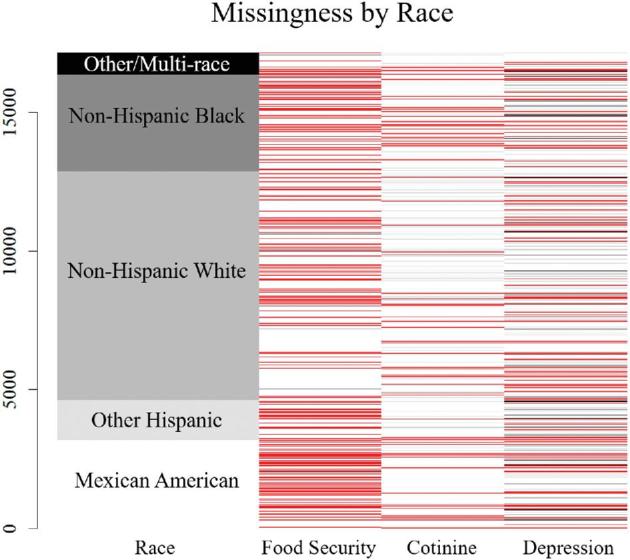
Path coefficients differed between 15.68% and 19.17% among model iterations. Nearly one-third of the cases had missing values, and MI reliably imputed values, allowing all cases to be represented in the final model iterations. QML provided better model fit statistics in all iterations.
Nutrition epidemiologists should use complex weights, MI, and QML as a best-practices approach to SEM when conducting analyses with complex design survey data.
结构方程模型(SEM)是一种多元分析方法,用于探索潜在结构与测量变量之间的关系。作为一种理论导向的方法,SEM基于纵向或横断面数据估计复杂模型中的定向路径,而在这些情况下进行随机对照试验可能不道德或成本过高。然而,尽管流行病学家建议增加其使用频率,但该方法在营养研究中却很少被使用。
本研究的目的是探讨研究人员在使用复杂调查数据集进行SEM时需要考虑的3个关键方法学领域:抽样权重的使用、缺失数据的处理和模型估计技术。
利用2005 - 2010年美国国家健康与营养检查调查(NHANES)的数据,我们开发了一个SEM来估计抑郁的潜在结构与粮食安全、烟草使用(血清可替宁)和年龄的测量变量之间的关系。我们采用分层方法,通过以下方式比较5个SEM模型迭代:1)不应用抽样权重和应用抽样权重的完整病例;2)一个应用缺失值数据集来测试多重填补(MI)的准确性;3)带有填补数据和抽样权重的完整NHANES数据集;4)一个最终重新指定的模型。每次迭代都使用最大似然法(ML)和带有萨托拉 - 本特勒校正的拟最大似然法(QML)来比较路径系数、标准误差和模型拟合统计量。
模型迭代之间的路径系数差异在15.68%至19.17%之间。近三分之一的病例有缺失值,MI可靠地填补了这些值,使得所有病例都能在最终模型迭代中得到体现。在所有迭代中,QML提供了更好的模型拟合统计量。
营养流行病学家在使用复杂设计调查数据进行分析时,应将复杂权重、MI和QML作为SEM的最佳实践方法。