Center for Multilingualism in Society Across the Lifespan, Department of Linguistics and Scandinavian Studies, University of Oslo, Oslo, Norway.
Department of Psychology, Åbo Akademi University, Turku, Finland.
Mem Cognit. 2019 Oct;47(7):1245-1269. doi: 10.3758/s13421-019-00931-7.
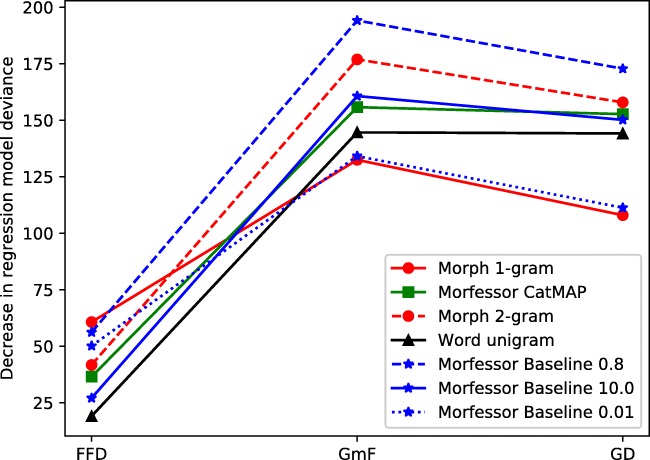
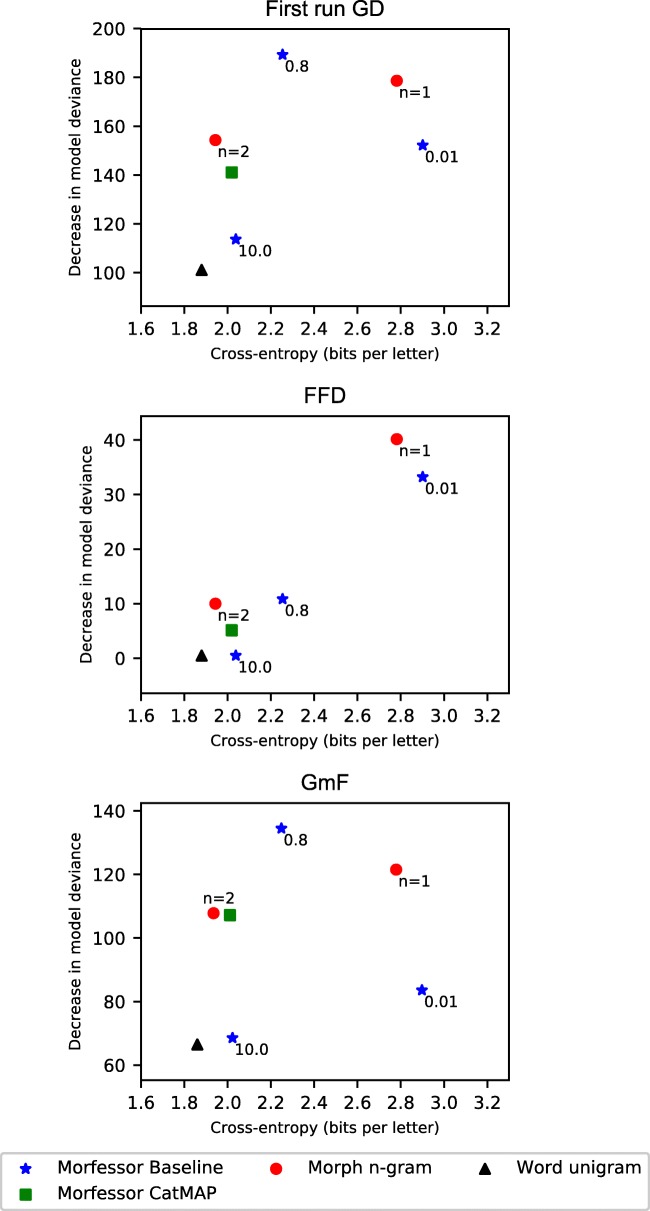
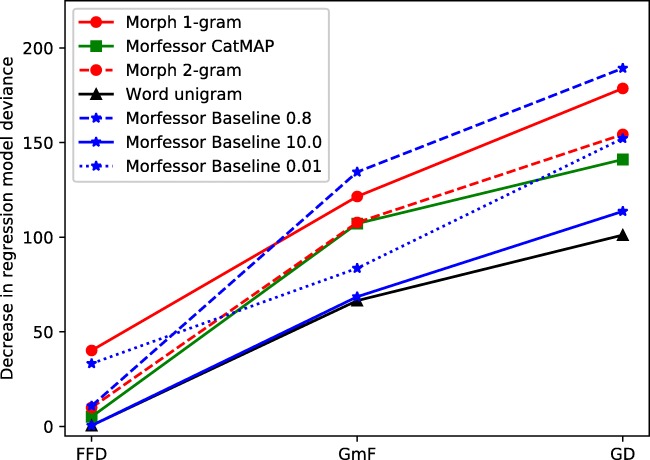
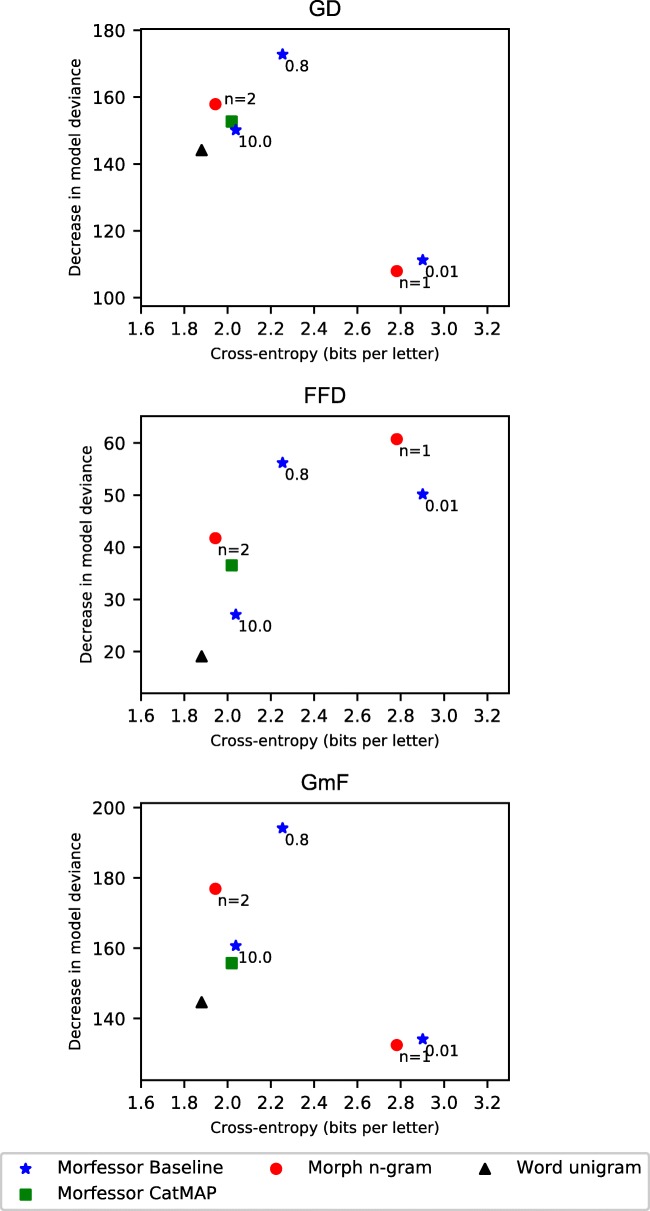
We studied how statistical models of morphology that are built on different kinds of representational units, i.e., models emphasizing either holistic units or decomposition, perform in predicting human word recognition. More specifically, we studied the predictive power of such models at early vs. late stages of word recognition by using eye-tracking during two tasks. The tasks included a standard lexical decision task and a word recognition task that assumedly places less emphasis on postlexical reanalysis and decision processes. The lexical decision results showed good performance of Morfessor models based on the Minimum Description Length optimization principle. Models which segment words at some morpheme boundaries and keep other boundaries unsegmented performed well both at early and late stages of word recognition, supporting dual- or multiple-route cognitive models of morphological processing. Statistical models based on full forms fared better in late than early measures. The results of the second, multi-word recognition task showed that early and late stages of processing often involve accessing morphological constituents, with the exception of short complex words. Late stages of word recognition additionally involve predicting upcoming morphemes on the basis of previous ones in multimorphemic words. The statistical models based fully on whole words did not fare well in this task. Thus, we assume that the good performance of such models in global measures such as gaze durations or reaction times in lexical decision largely stems from postlexical reanalysis or decision processes. This finding highlights the importance of considering task demands in the study of morphological processing.
我们研究了基于不同表示单位的形态学统计模型在预测人类单词识别方面的表现,这些模型强调整体单位或分解。更具体地说,我们通过在两个任务中使用眼动追踪来研究这些模型在单词识别的早期和晚期阶段的预测能力。这些任务包括标准的词汇判断任务和一个假设较少依赖词后再分析和决策过程的单词识别任务。词汇判断结果显示,基于最小描述长度优化原则的 Morfessor 模型表现良好。在一些词素边界上分段而在其他边界上不分段的模型在单词识别的早期和晚期阶段都表现良好,支持形态处理的双重或多重认知模型。基于完整形式的统计模型在晚期测量中表现优于早期测量。第二个多词识别任务的结果表明,处理的早期和晚期阶段通常涉及访问形态成分,除了短的复杂词。在多词素词中,单词识别的晚期阶段还涉及根据前一个词素预测即将到来的词素。完全基于整个词的统计模型在这项任务中表现不佳。因此,我们假设这些模型在词汇判断中的全局测量(如注视持续时间或反应时间)中的良好表现主要源于词后再分析或决策过程。这一发现强调了在形态处理研究中考虑任务需求的重要性。