Lavan Nadine, Domone Abigail, Fisher Betty, Kenigzstein Noa, Scott Sophie Kerttu, McGettigan Carolyn
1Department of Psychology, Royal Holloway, University of London, Egham Hill, Egham, TW20 0EX UK.
2Department of Speech, Hearing and Phonetic Sciences, University College London, London, UK.
J Nonverbal Behav. 2019;43(1):1-22. doi: 10.1007/s10919-018-0289-0. Epub 2018 Oct 20.
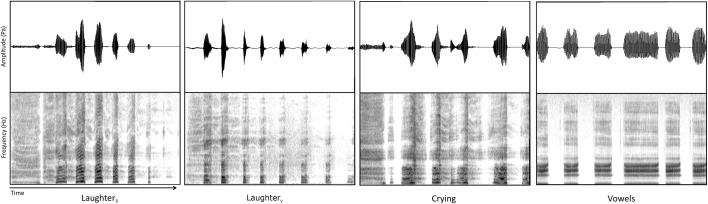
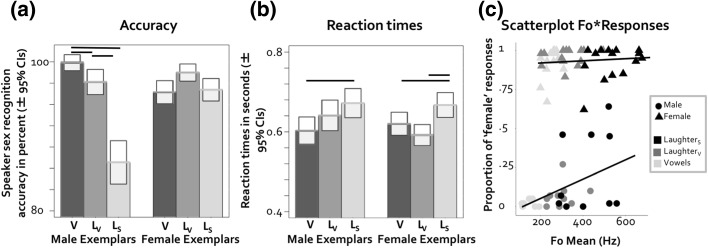
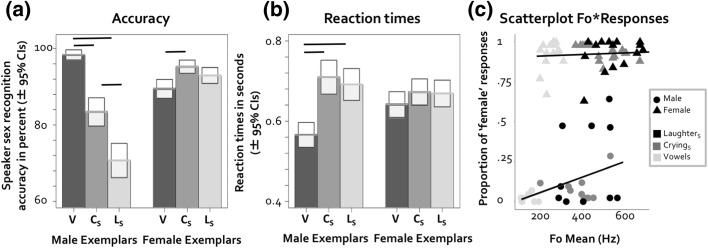
In two experiments, we explore how speaker sex recognition is affected by vocal flexibility, introduced by volitional and spontaneous vocalizations. In Experiment 1, participants judged speaker sex from two spontaneous vocalizations, laughter and crying, and volitionally produced vowels. Striking effects of speaker sex emerged: For male vocalizations, listeners' performance was significantly impaired for spontaneous vocalizations (laughter and crying) compared to a volitional baseline (repeated vowels), a pattern that was also reflected in longer reaction times for spontaneous vocalizations. Further, performance was less accurate for laughter than crying. For female vocalizations, a different pattern emerged. In Experiment 2, we largely replicated the findings of Experiment 1 using spontaneous laughter, volitional laughter and (volitional) vowels: here, performance for male vocalizations was impaired for spontaneous laughter compared to both volitional laughter and vowels, providing further evidence that differences in volitional control over vocal production may modulate our ability to accurately perceive speaker sex from vocal signals. For both experiments, acoustic analyses showed relationships between stimulus fundamental frequency (F0) and the participants' responses. The higher the F0 of a vocal signal, the more likely listeners were to perceive a vocalization as being produced by a female speaker, an effect that was more pronounced for vocalizations produced by males. We discuss the results in terms of the availability of salient acoustic cues across different vocalizations.
在两项实验中,我们探究了说话者性别识别是如何受到由自发发声和有意发声所引入的发声灵活性的影响。在实验1中,参与者从两种自发发声(笑声和哭声)以及有意发出的元音中判断说话者的性别。出现了显著的说话者性别效应:对于男性发声,与有意发声基线(重复元音)相比,听众对自发发声(笑声和哭声)的表现明显受损,这种模式也体现在自发发声的更长反应时间上。此外,对笑声的表现比对哭声的表现更不准确。对于女性发声,则出现了不同的模式。在实验2中,我们使用自发笑声、有意笑声和(有意)元音在很大程度上重复了实验1的结果:在这里,与有意笑声和元音相比,男性发声在自发笑声中的表现受损,这进一步证明了对发声产生的有意控制差异可能会调节我们从声音信号中准确感知说话者性别的能力。对于这两项实验,声学分析显示了刺激基频(F0)与参与者反应之间的关系。声音信号的F0越高,听众就越有可能将发声感知为由女性说话者发出,这种效应在男性发出的发声中更为明显。我们根据不同发声中显著声学线索的可用性来讨论结果。