School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, 699 S Mill Ave, Tempe, AZ, 85281, USA.
Precision NeuroTherapeutics (PNT) Lab, Mayo Clinic Arizona, 5777 E Mayo Blvd, Phoenix, Arizona, 85054, USA.
Sci Rep. 2019 Jul 11;9(1):10063. doi: 10.1038/s41598-019-46296-4.
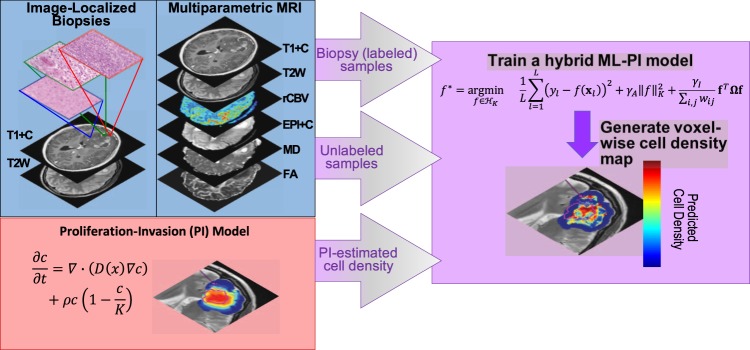
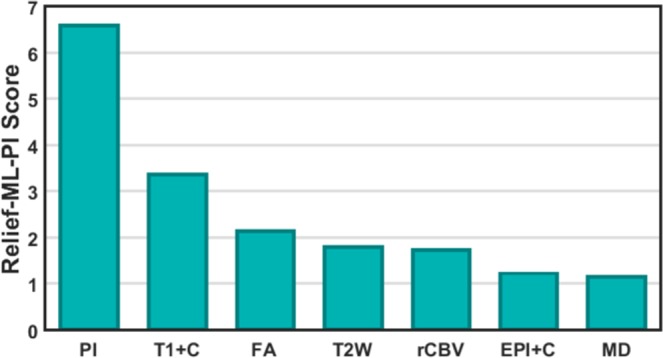
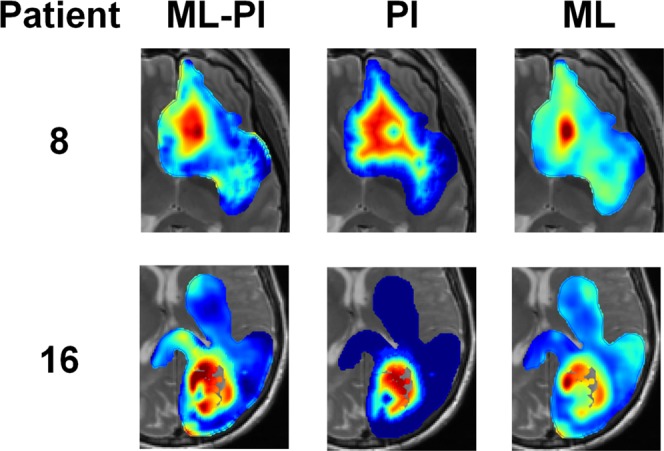
Glioblastoma (GBM) is a heterogeneous and lethal brain cancer. These tumors are followed using magnetic resonance imaging (MRI), which is unable to precisely identify tumor cell invasion, impairing effective surgery and radiation planning. We present a novel hybrid model, based on multiparametric intensities, which combines machine learning (ML) with a mechanistic model of tumor growth to provide spatially resolved tumor cell density predictions. The ML component is an imaging data-driven graph-based semi-supervised learning model and we use the Proliferation-Invasion (PI) mechanistic tumor growth model. We thus refer to the hybrid model as the ML-PI model. The hybrid model was trained using 82 image-localized biopsies from 18 primary GBM patients with pre-operative MRI using a leave-one-patient-out cross validation framework. A Relief algorithm was developed to quantify relative contributions from the data sources. The ML-PI model statistically significantly outperformed (p < 0.001) both individual models, ML and PI, achieving a mean absolute predicted error (MAPE) of 0.106 ± 0.125 versus 0.199 ± 0.186 (ML) and 0.227 ± 0.215 (PI), respectively. Associated Pearson correlation coefficients for ML-PI, ML, and PI were 0.838, 0.518, and 0.437, respectively. The Relief algorithm showed the PI model had the greatest contribution to the result, emphasizing the importance of the hybrid model in achieving the high accuracy.
胶质母细胞瘤(GBM)是一种异质性和致命的脑癌。这些肿瘤通过磁共振成像(MRI)进行监测,但 MRI 无法精确识别肿瘤细胞的侵袭,从而影响了有效的手术和放疗计划。我们提出了一种新的混合模型,该模型基于多参数强度,将机器学习(ML)与肿瘤生长的机制模型相结合,提供空间分辨的肿瘤细胞密度预测。ML 成分是一个基于图像的图半监督学习模型,我们使用增殖-侵袭(PI)机制肿瘤生长模型。因此,我们将混合模型称为 ML-PI 模型。使用来自 18 名原发性 GBM 患者的 82 个术前 MRI 图像局部活检,使用留一患者交叉验证框架对混合模型进行训练。开发了一种 Relief 算法来量化来自数据源的相对贡献。ML-PI 模型在统计学上显著优于(p<0.001)单独的 ML 和 PI 模型,平均绝对预测误差(MAPE)分别为 0.106±0.125、0.199±0.186(ML)和 0.227±0.215(PI)。ML-PI、ML 和 PI 的相关 Pearson 相关系数分别为 0.838、0.518 和 0.437。Relief 算法表明 PI 模型对结果的贡献最大,强调了混合模型在实现高精度方面的重要性。