Institute of Genetic Medicine, Newcastle University, Newcastle upon Tyne, NE1 4EP, Tyne and Wear, UK.
School of Health Sciences, Manchester University, Manchester, M13 9NT, UK.
Proteomics. 2019 Aug;19(15):e1900156. doi: 10.1002/pmic.201900156. Epub 2019 Jul 22.
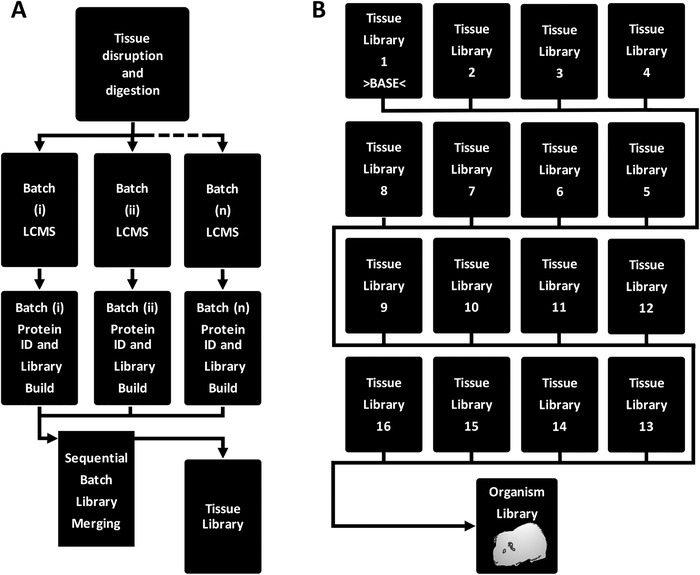
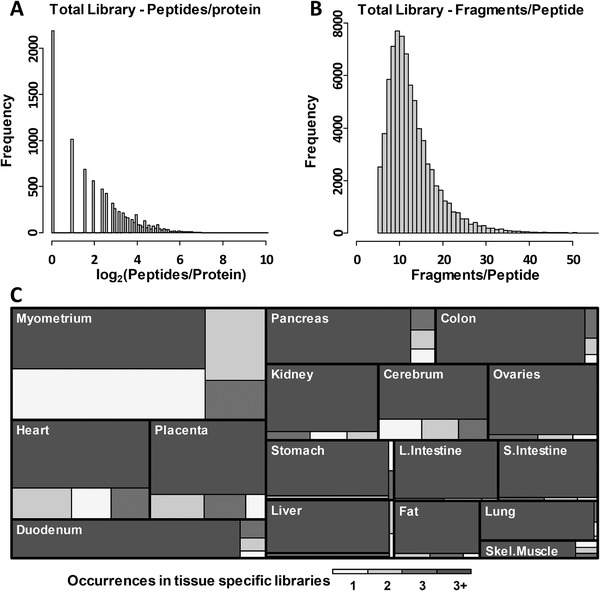
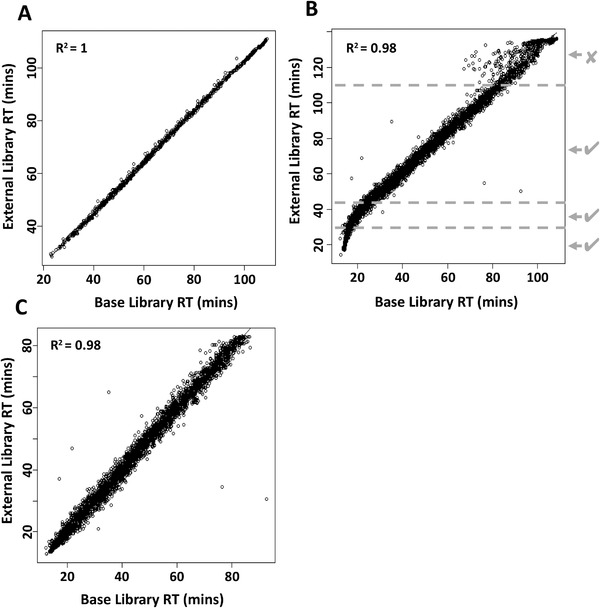
Advances in liquid chromatography-mass spectrometry have facilitated the incorporation of proteomic studies to many biology experimental workflows. Data-independent acquisition platforms, such as sequential window acquisition of all theoretical mass spectra (SWATH-MS), offer several advantages for label-free quantitative assessment of complex proteomes over data-dependent acquisition (DDA) approaches. However, SWATH data interpretation requires spectral libraries as a detailed reference resource. The guinea pig (Cavia porcellus) is an excellent experimental model for translation to many aspects of human physiology and disease, yet there is limited experimental information regarding its proteome. To overcome this knowledge gap, a comprehensive spectral library of the guinea pig proteome is generated. Homogenates and tryptic digests are prepared from 16 tissues and subjected to >200 DDA runs. Analysis of >250 000 peptide-spectrum matches resulted in a library of 73 594 peptides from 7666 proteins. Library validation is provided by i) analyzing externally derived SWATH files (https://doi.org/10.1016/j.jprot.2018.03.023) and comparing peptide intensity quantifications; ii) merging of externally derived data to the base library. This furnishes the research community with a comprehensive proteomic resource that will facilitate future molecular-phenotypic studies using (re-engaging) the guinea pig as an experimental model of relevance to human biology. The spectral library and raw data are freely accessible in the MassIVE repository (MSV000083199).
液相色谱-质谱联用技术的进步促进了蛋白质组学研究在许多生物学实验工作流程中的应用。非依赖性数据采集平台,如全理论质量谱序贯窗口采集(SWATH-MS),为无标记定量评估复杂蛋白质组学提供了优于依赖性数据采集(DDA)方法的几个优势。然而,SWATH 数据解释需要光谱库作为详细的参考资源。豚鼠(Cavia porcellus)是一种极好的实验模型,可用于研究人类生理学和疾病的许多方面,但关于其蛋白质组的实验信息有限。为了克服这一知识差距,生成了豚鼠蛋白质组的综合光谱库。从 16 种组织中制备匀浆和胰蛋白酶消化物,并进行了 >200 次 DDA 运行。对 >250000 个肽-谱匹配进行分析,得到了 7666 种蛋白质的 73594 种肽的文库。通过以下方法提供文库验证:i)分析外部衍生的 SWATH 文件(https://doi.org/10.1016/j.jprot.2018.03.023)并比较肽强度定量;ii)将外部衍生的数据合并到基础文库中。这为研究界提供了一个全面的蛋白质组资源,将促进未来使用(重新参与)豚鼠作为与人类生物学相关的实验模型的分子表型研究。该光谱库和原始数据可在 MassIVE 存储库(MSV000083199)中免费获取。