Baldassarre Gianluca, Lord William, Granato Giovanni, Santucci Vieri Giuliano
Laboratory of Computational Embodied Neuroscience, Institute of Cognitive Sciences and Technologies, National Research Council of Italy, Rome, Italy.
School of Engineering Sciences, KTH Royal Institute of Technology, Stockholm, Sweden.
Front Neurorobot. 2019 Jul 26;13:45. doi: 10.3389/fnbot.2019.00045. eCollection 2019.
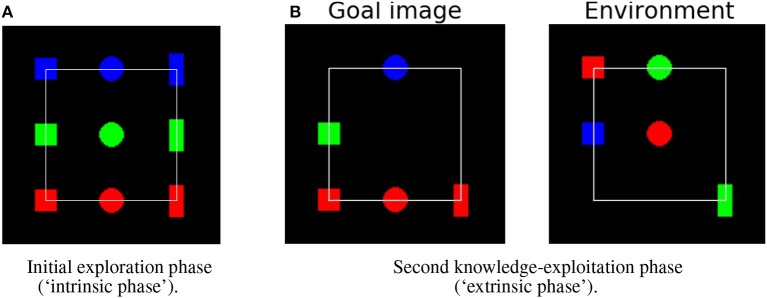
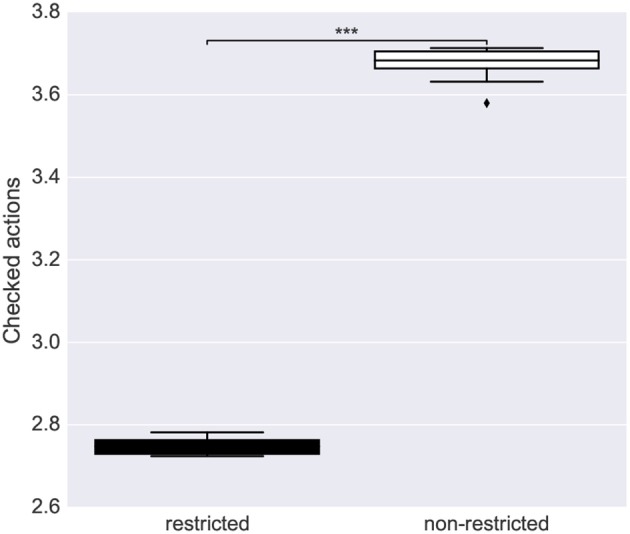
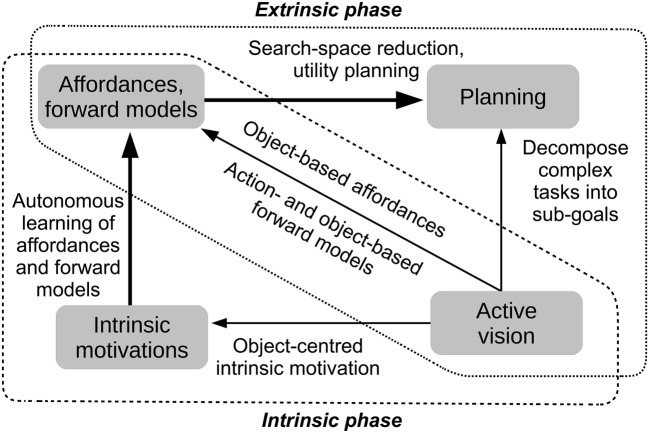
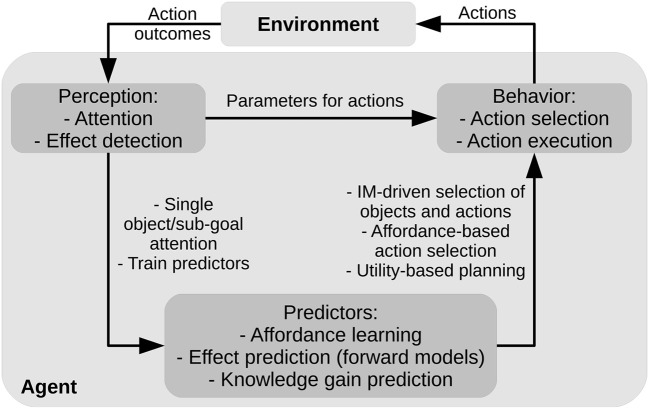
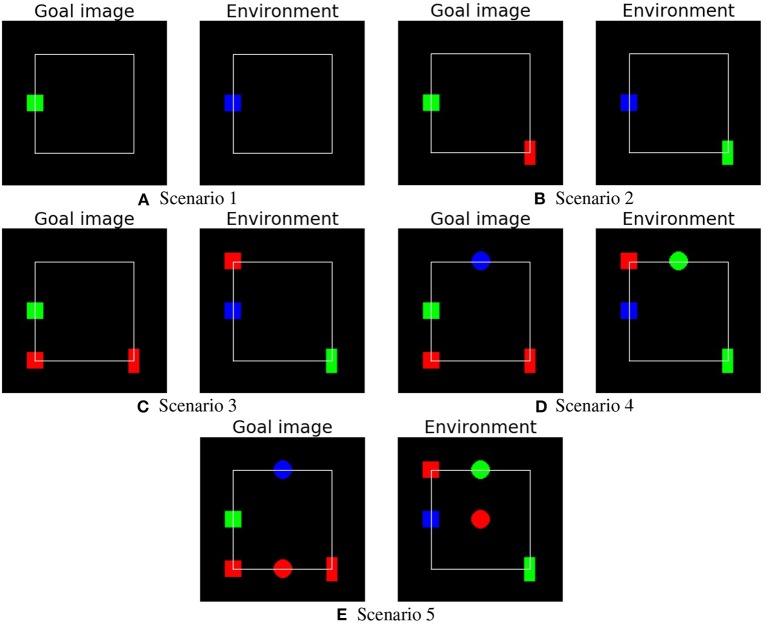
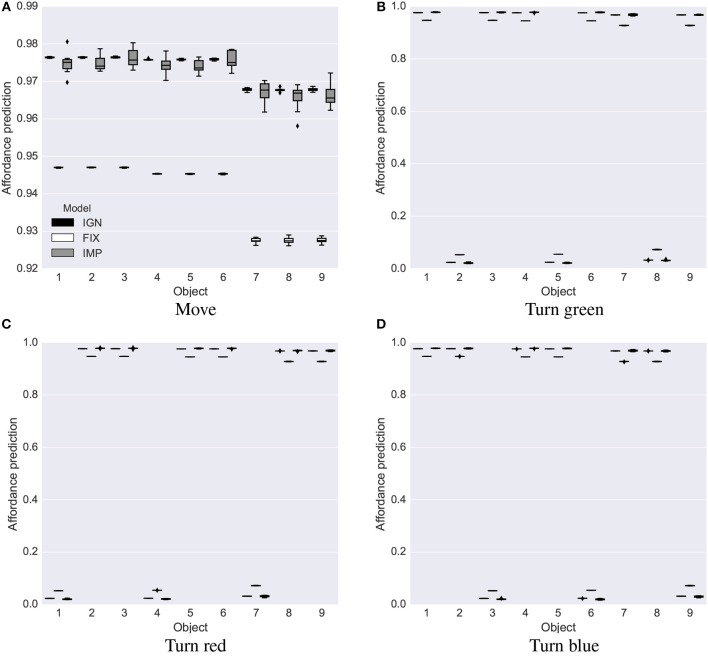
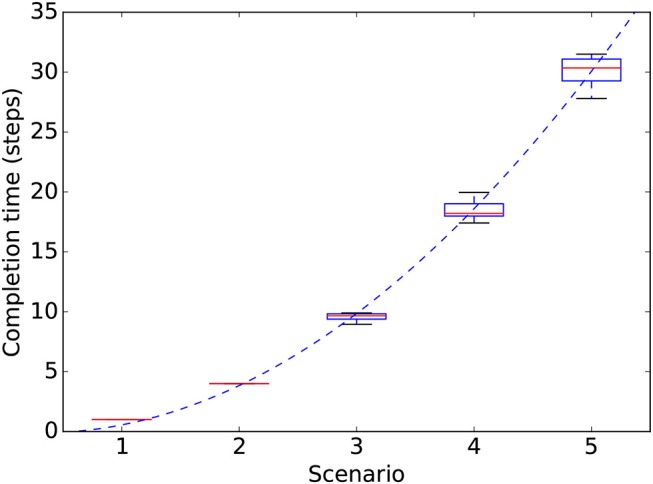
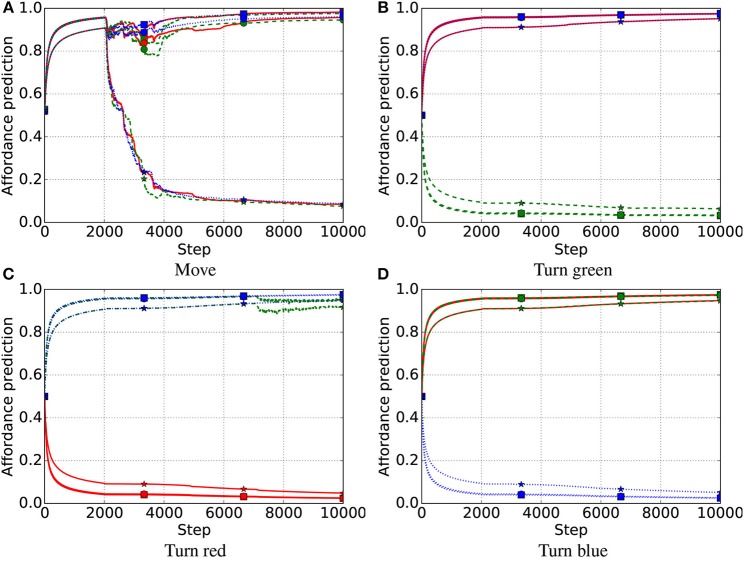
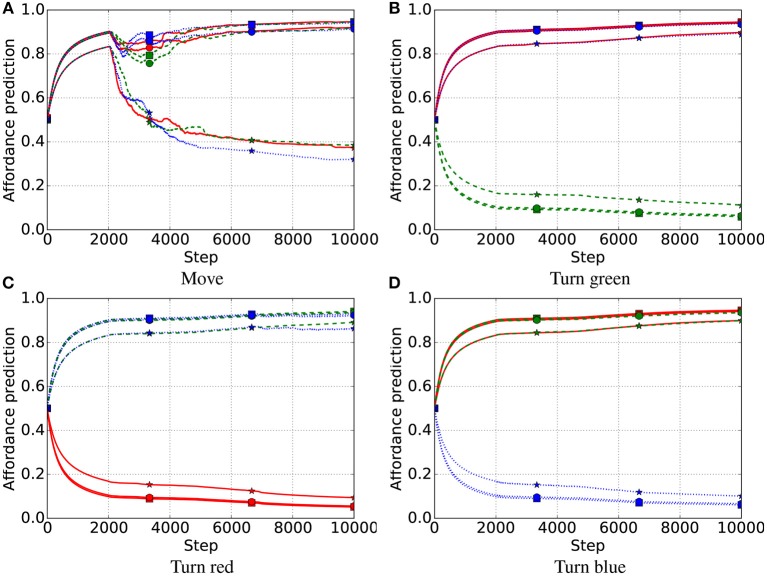
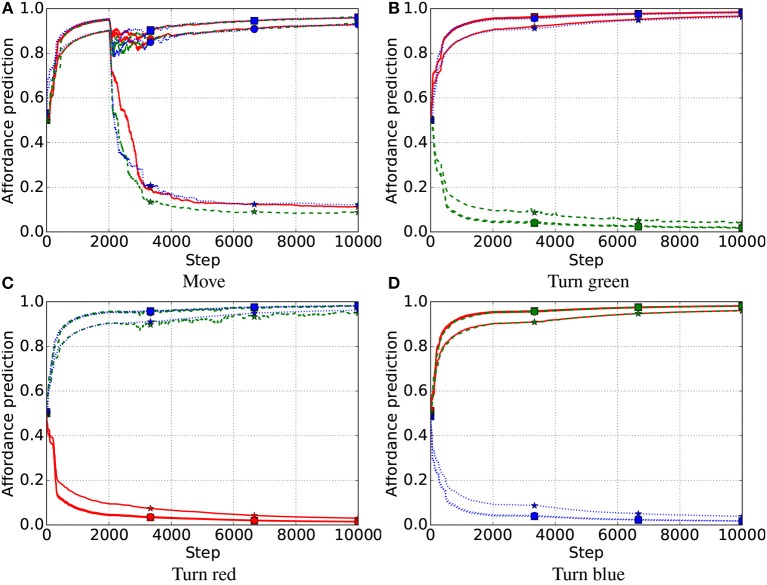
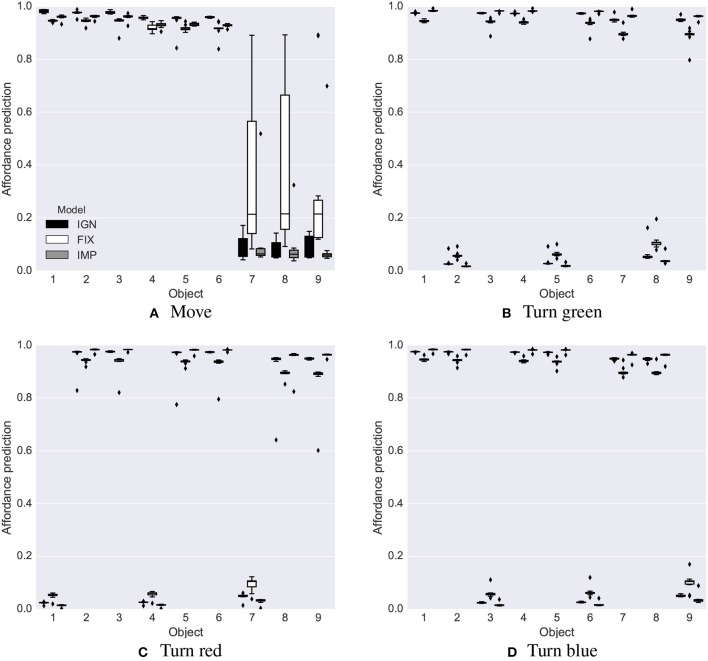
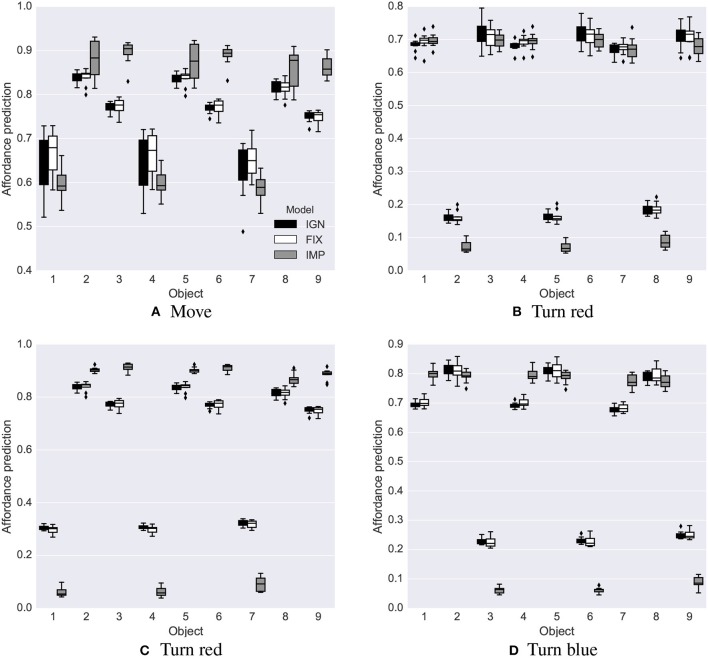
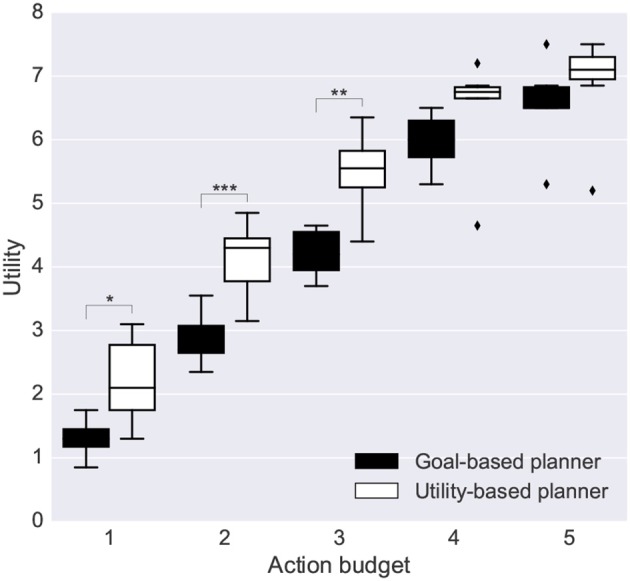
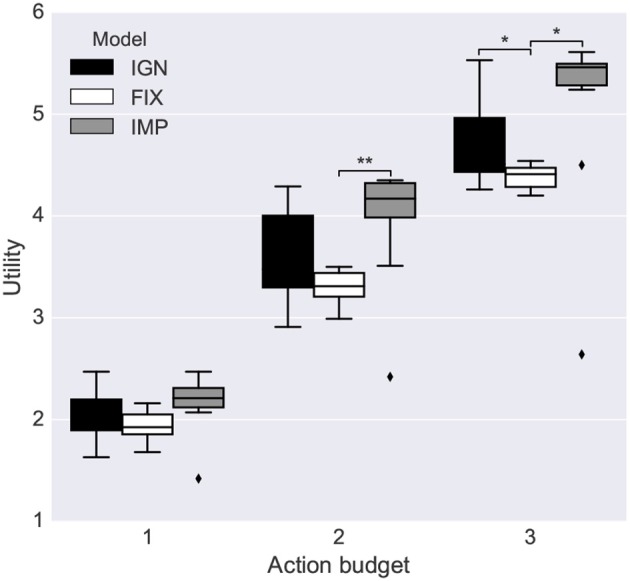
We propose an architecture for the open-ended learning and control of embodied agents. The architecture learns action affordances and forward models based on intrinsic motivations and can later use the acquired knowledge to solve extrinsic tasks by decomposing them into sub-tasks, each solved with one-step planning. An affordance is here operationalized as the agent's estimate of the probability of success of an action performed on a given object. The focus of the work is on the overall architecture while single sensorimotor components are simplified. A key element of the architecture is the use of "active vision" that plays two functions, namely to focus on single objects and to factorize visual information into the object appearance and object position. These processes serve both the acquisition and use of object-related affordances, and the decomposition of extrinsic goals (tasks) into multiple sub-goals (sub-tasks). The architecture gives novel contributions on three problems: (a) the learning of affordances based on intrinsic motivations; (b) the use of active vision to decompose complex extrinsic tasks; (c) the possible role of affordances within planning systems endowed with models of the world. The architecture is tested in a simulated stylized 2D scenario in which objects need to be moved or "manipulated" in order to accomplish new desired overall configurations of the objects (extrinsic goals). The results show the utility of using intrinsic motivations to support affordance learning; the utility of active vision to solve composite tasks; and the possible utility of affordances for solving utility-based planning problems.
我们提出了一种用于具身智能体的开放式学习与控制的架构。该架构基于内在动机学习动作可供性和前向模型,随后可以利用所获取的知识,通过将外部任务分解为子任务,并采用单步规划来解决每个子任务,从而解决外部任务。在这里,可供性被定义为智能体对在给定对象上执行动作成功概率的估计。这项工作的重点在于整体架构,同时简化了单个的感觉运动组件。该架构的一个关键要素是使用“主动视觉”,它具有两个功能,即聚焦于单个对象以及将视觉信息分解为对象外观和对象位置。这些过程既服务于与对象相关的可供性的获取和使用,也服务于将外部目标(任务)分解为多个子目标(子任务)。该架构在三个问题上做出了新颖的贡献:(a)基于内在动机学习可供性;(b)利用主动视觉分解复杂的外部任务;(c)可供性在配备世界模型的规划系统中可能发挥的作用。该架构在一个模拟的二维风格场景中进行了测试,在该场景中,需要移动或“操纵”对象,以实现对象的新的期望整体配置(外部目标)。结果表明了利用内在动机支持可供性学习的效用;利用主动视觉解决复合任务的效用;以及可供性在解决基于效用的规划问题方面可能具有的效用。