Wang Yichen, Chen Robert, Ghosh Joydeep, Denny Joshua C, Kho Abel, Chen You, Malin Bradley A, Sun Jimeng
Georgia Institute of Technology.
University of Texas, Austin.
KDD. 2015 Aug;2015:1265-1274. doi: 10.1145/2783258.2783395.
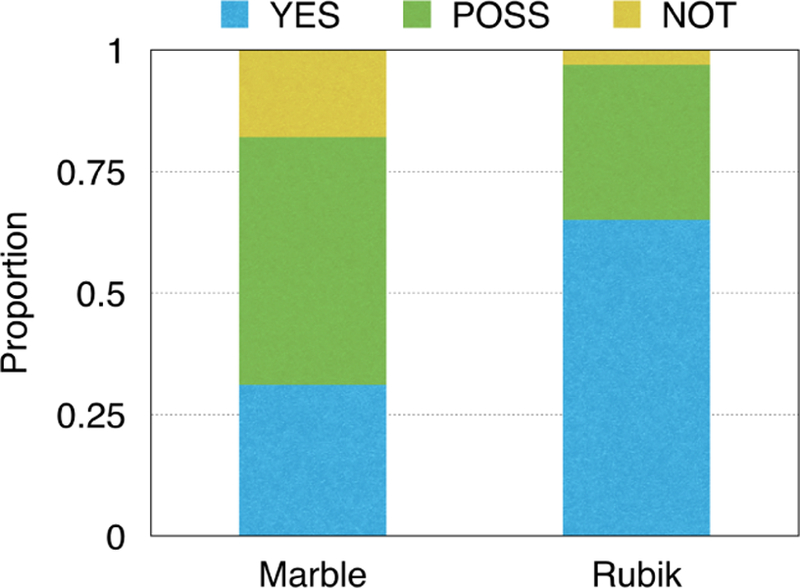
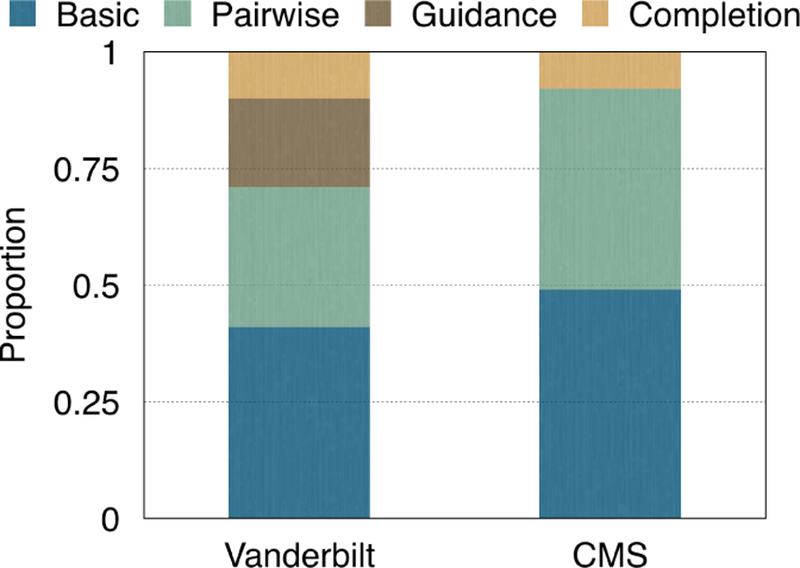
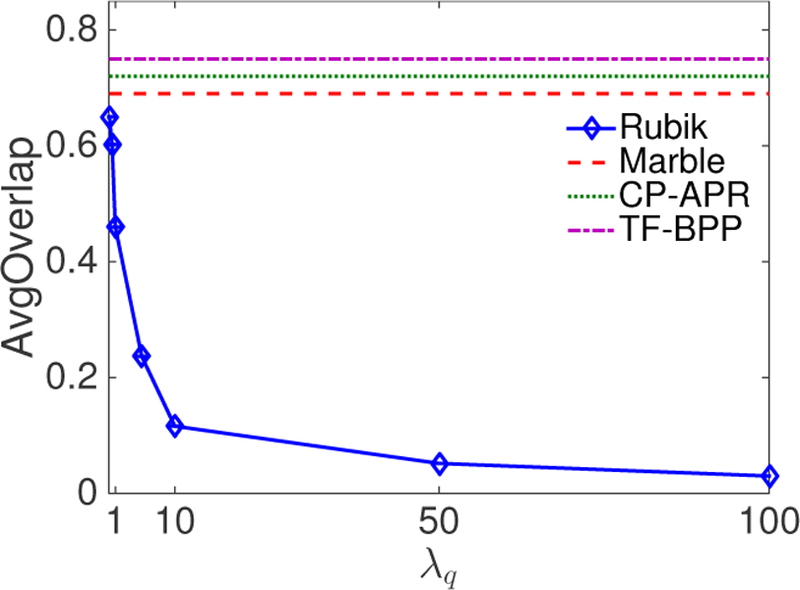
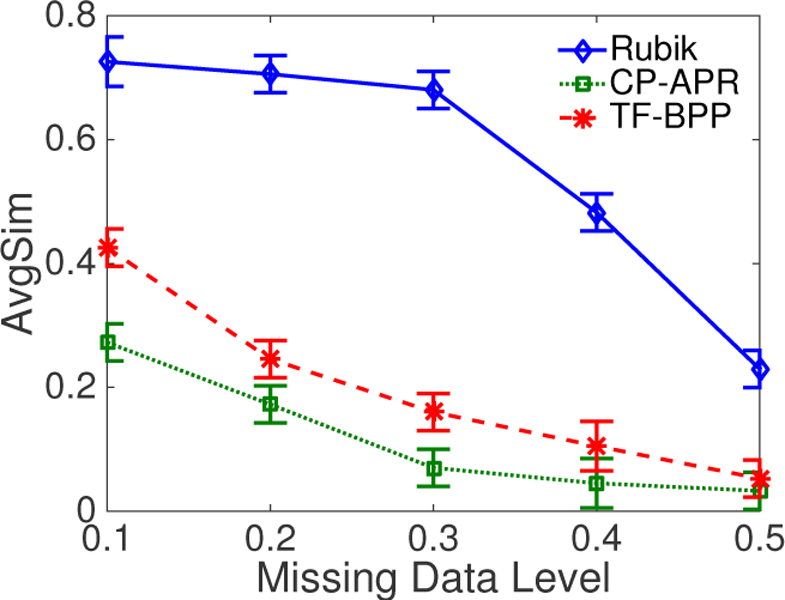
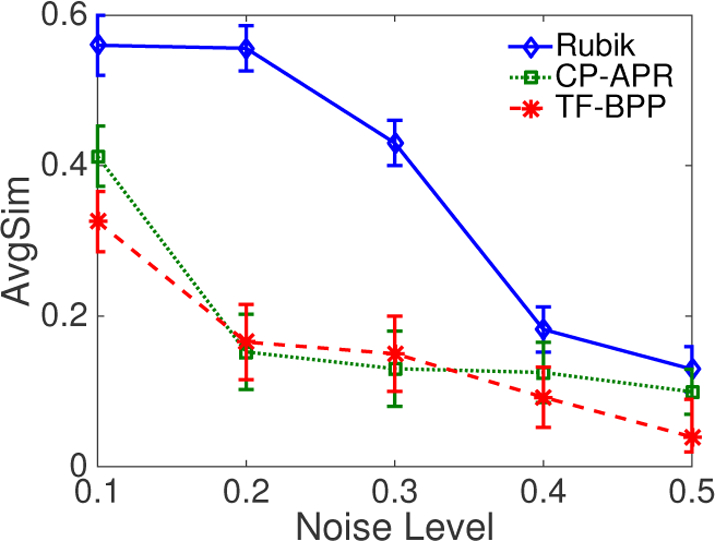
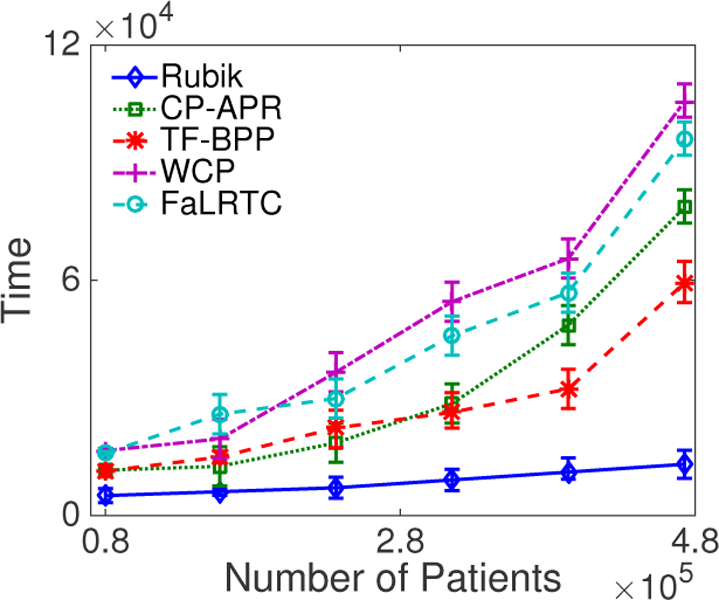
Computational phenotyping is the process of converting heterogeneous electronic health records (EHRs) into meaningful clinical concepts. Unsupervised phenotyping methods have the potential to leverage a vast amount of labeled EHR data for phenotype discovery. However, existing unsupervised phenotyping methods do not incorporate current medical knowledge and cannot directly handle missing, or noisy data. We propose Rubik, a constrained non-negative tensor factorization and completion method for phenotyping. Rubik incorporates 1) guidance constraints to align with existing medical knowledge, and 2) pairwise constraints for obtaining distinct, non-overlapping phenotypes. Rubik also has built-in tensor completion that can significantly alleviate the impact of noisy and missing data. We utilize the Alternating Direction Method of Multipliers (ADMM) framework to tensor factorization and completion, which can be easily scaled through parallel computing. We evaluate Rubik on two EHR datasets, one of which contains 647,118 records for 7,744 patients from an outpatient clinic, the other of which is a public dataset containing 1,018,614 CMS claims records for 472,645 patients. Our results show that Rubik can discover more meaningful and distinct phenotypes than the baselines. In particular, by using knowledge guidance constraints, Rubik can also discover sub-phenotypes for several major diseases. Rubik also runs around seven times faster than current state-of-the-art tensor methods. Finally, Rubik is scalable to large datasets containing millions of EHR records.
计算表型分析是将异构电子健康记录(EHR)转换为有意义的临床概念的过程。无监督表型分析方法有潜力利用大量带标签的EHR数据进行表型发现。然而,现有的无监督表型分析方法没有纳入当前医学知识,并且无法直接处理缺失或有噪声的数据。我们提出了Rubik,一种用于表型分析的约束非负张量分解与补全方法。Rubik纳入了1)指导约束以与现有医学知识对齐,以及2)成对约束以获得不同的、不重叠的表型。Rubik还具有内置的张量补全功能,可显著减轻噪声和缺失数据的影响。我们利用交替方向乘子法(ADMM)框架进行张量分解与补全,该框架可通过并行计算轻松扩展。我们在两个EHR数据集上评估了Rubik,其中一个包含来自门诊诊所的7744名患者的647118条记录,另一个是包含472645名患者的1018614条CMS理赔记录的公共数据集。我们的结果表明,Rubik能比基线方法发现更有意义且不同的表型。特别是,通过使用知识指导约束,Rubik还能发现几种主要疾病的亚表型。Rubik的运行速度也比当前最先进的张量方法快约七倍。最后,Rubik可扩展到包含数百万条EHR记录的大型数据集。