Statistical Bioinformatics, Institute of Functional Genomics, University of Regensburg, Am Biopark 9, 93053, Regensburg, Germany.
Institute of Computational Biology, Helmholtz Zentrum München, Ingolstädter Landstraße 1, 85764, Neuherberg, Germany.
Sci Rep. 2019 Sep 27;9(1):13954. doi: 10.1038/s41598-019-50346-2.
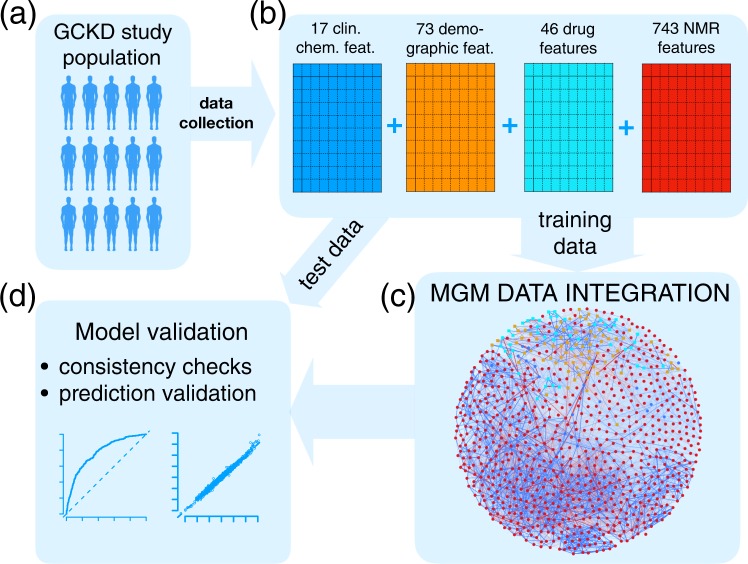
Omics data facilitate the gain of novel insights into the pathophysiology of diseases and, consequently, their diagnosis, treatment, and prevention. To this end, omics data are integrated with other data types, e.g., clinical, phenotypic, and demographic parameters of categorical or continuous nature. We exemplify this data integration issue for a chronic kidney disease (CKD) study, comprising complex clinical, demographic, and one-dimensional H nuclear magnetic resonance metabolic variables. Routine analysis screens for associations of single metabolic features with clinical parameters while accounting for confounders typically chosen by expert knowledge. This knowledge can be incomplete or unavailable. We introduce a framework for data integration that intrinsically adjusts for confounding variables. We give its mathematical and algorithmic foundation, provide a state-of-the-art implementation, and evaluate its performance by sanity checks and predictive performance assessment on independent test data. Particularly, we show that discovered associations remain significant after variable adjustment based on expert knowledge. In contrast, we illustrate that associations discovered in routine univariate screening approaches can be biased by incorrect or incomplete expert knowledge. Our data integration approach reveals important associations between CKD comorbidities and metabolites, including novel associations of the plasma metabolite trimethylamine-N-oxide with cardiac arrhythmia and infarction in CKD stage 3 patients.
组学数据有助于深入了解疾病的病理生理学,并相应地促进疾病的诊断、治疗和预防。为此,组学数据与其他类型的数据进行整合,例如临床、表型和分类或连续性质的人口统计学参数。我们以一个慢性肾病 (CKD) 研究为例来说明这个数据整合问题,该研究包括复杂的临床、人口统计学和一维 H 核磁共振代谢变量。常规分析会筛选单个代谢特征与临床参数之间的关联,同时考虑通常由专家知识选择的混杂因素。这些知识可能不完整或不可用。我们引入了一种数据集成框架,该框架可以内在地调整混杂变量。我们给出了它的数学和算法基础,提供了最先进的实现,并通过独立测试数据的合理性检查和预测性能评估来评估其性能。特别是,我们表明,在基于专家知识的变量调整后,发现的关联仍然具有统计学意义。相比之下,我们说明了在常规单变量筛选方法中发现的关联可能会受到错误或不完整的专家知识的影响。我们的数据集成方法揭示了 CKD 合并症和代谢物之间的重要关联,包括血浆代谢物三甲胺-N-氧化物与 CKD 3 期患者心律失常和梗塞之间的新关联。