Callahan Alison, Fries Jason A, Ré Christopher, Huddleston James I, Giori Nicholas J, Delp Scott, Shah Nigam H
1Center for Biomedical Informatics Research, Stanford University, 1265 Welch Road, Stanford, CA USA 94305.
2Department of Computer Science, Stanford University, 353 Serra Mall, Stanford, CA USA 94305.
NPJ Digit Med. 2019 Sep 25;2:94. doi: 10.1038/s41746-019-0168-z. eCollection 2019.
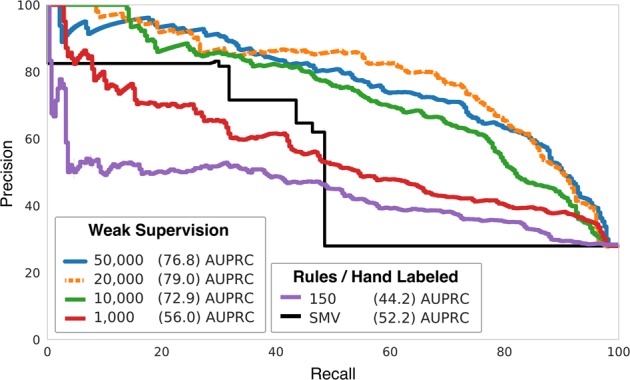
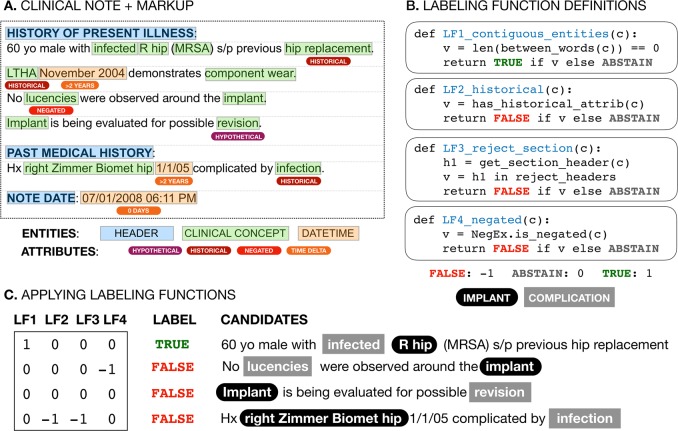
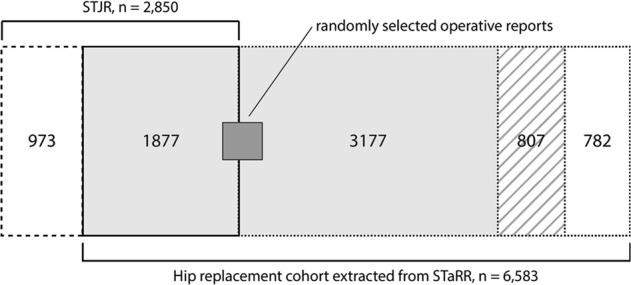
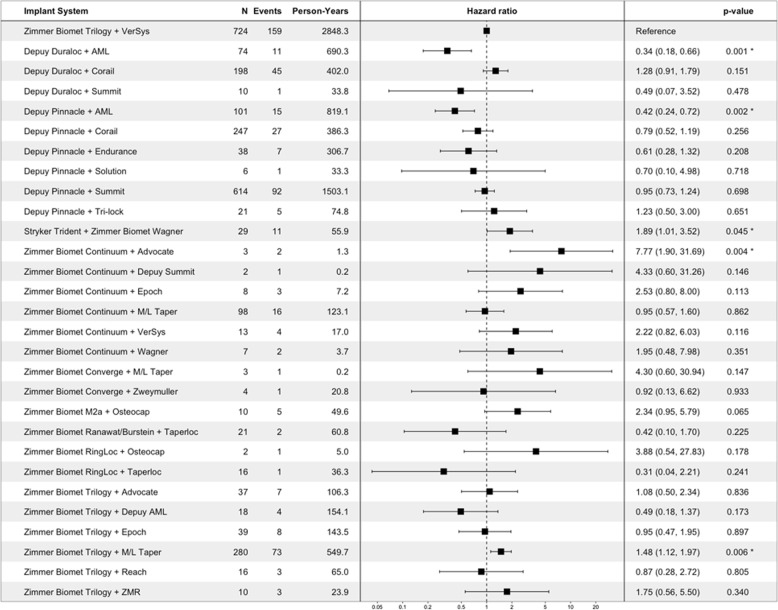
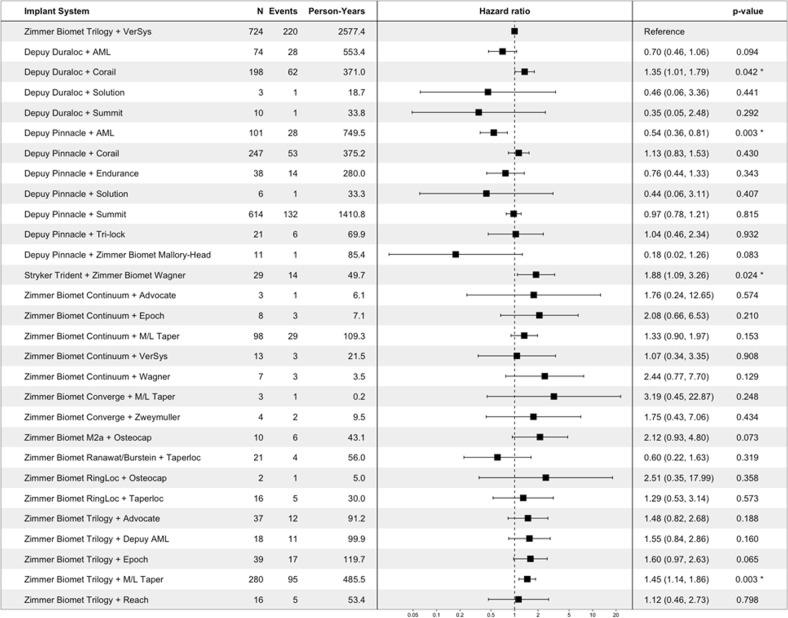
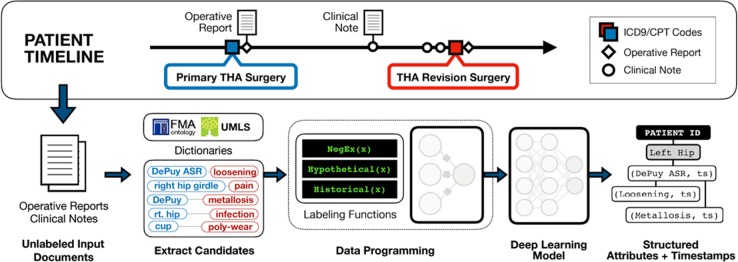
Post-market medical device surveillance is a challenge facing manufacturers, regulatory agencies, and health care providers. Electronic health records are valuable sources of real-world evidence for assessing device safety and tracking device-related patient outcomes over time. However, distilling this evidence remains challenging, as information is fractured across clinical notes and structured records. Modern machine learning methods for machine reading promise to unlock increasingly complex information from text, but face barriers due to their reliance on large and expensive hand-labeled training sets. To address these challenges, we developed and validated state-of-the-art deep learning methods that identify patient outcomes from clinical notes without requiring hand-labeled training data. Using hip replacements-one of the most common implantable devices-as a test case, our methods accurately extracted implant details and reports of complications and pain from electronic health records with up to 96.3% precision, 98.5% recall, and 97.4% F1, improved classification performance by 12.8-53.9% over rule-based methods, and detected over six times as many complication events compared to using structured data alone. Using these additional events to assess complication-free survivorship of different implant systems, we found significant variation between implants, including for risk of revision surgery, which could not be detected using coded data alone. Patients with revision surgeries had more hip pain mentions in the post-hip replacement, pre-revision period compared to patients with no evidence of revision surgery (mean hip pain mentions 4.97 vs. 3.23; t = 5.14; < 0.001). Some implant models were associated with higher or lower rates of hip pain mentions. Our methods complement existing surveillance mechanisms by requiring orders of magnitude less hand-labeled training data, offering a scalable solution for national medical device surveillance using electronic health records.
上市后医疗器械监测是制造商、监管机构和医疗保健提供者面临的一项挑战。电子健康记录是评估设备安全性和长期跟踪与设备相关的患者结局的宝贵真实世界证据来源。然而,提取这些证据仍然具有挑战性,因为信息分散在临床记录和结构化记录中。用于机器阅读的现代机器学习方法有望从文本中解锁日益复杂的信息,但由于依赖大量且昂贵的人工标注训练集而面临障碍。为应对这些挑战,我们开发并验证了先进的深度学习方法,该方法可从临床记录中识别患者结局,而无需人工标注训练数据。以髋关节置换术(最常见的可植入设备之一)为例,我们的方法能够从电子健康记录中准确提取植入物细节以及并发症和疼痛报告,精确率高达96.3%,召回率为98.5%,F1值为97.4%,与基于规则的方法相比,分类性能提高了12.8 - 53.9%,并且与仅使用结构化数据相比,检测到的并发症事件数量多出六倍以上。利用这些额外的事件来评估不同植入系统的无并发症生存期,我们发现植入物之间存在显著差异,包括翻修手术风险方面的差异,而仅使用编码数据无法检测到这些差异。与没有翻修手术证据的患者相比,接受翻修手术的患者在髋关节置换术后、翻修术前阶段提及髋关节疼痛的次数更多(平均髋关节疼痛提及次数为4.97次对3.23次;t = 5.14;< 0.001)。一些植入模型与较高或较低的髋关节疼痛提及率相关。我们的方法通过所需的人工标注训练数据数量减少几个数量级来补充现有的监测机制,为使用电子健康记录进行全国性医疗器械监测提供了一种可扩展的解决方案。