LIMSI, CNRS, Université Paris Saclay, Rue du Belvedère, Orsay, 91405, France.
Amsterdam Public Health, Amsterdam UMC, University of Amsterdam, Meibergdreef 9, Amsterdam, 1105 AZ, the Netherlands.
Syst Rev. 2019 Oct 28;8(1):243. doi: 10.1186/s13643-019-1162-x.
The large and increasing number of new studies published each year is making literature identification in systematic reviews ever more time-consuming and costly. Technological assistance has been suggested as an alternative to the conventional, manual study identification to mitigate the cost, but previous literature has mainly evaluated methods in terms of recall (search sensitivity) and workload reduction. There is a need to also evaluate whether screening prioritization methods leads to the same results and conclusions as exhaustive manual screening. In this study, we examined the impact of one screening prioritization method based on active learning on sensitivity and specificity estimates in systematic reviews of diagnostic test accuracy.
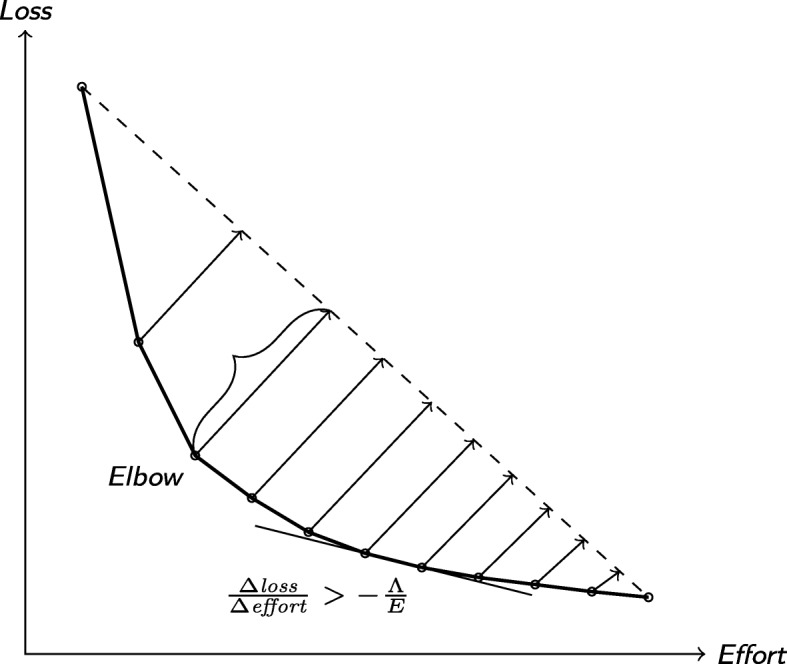
We simulated the screening process in 48 Cochrane reviews of diagnostic test accuracy and re-run 400 meta-analyses based on a least 3 studies. We compared screening prioritization (with technological assistance) and screening in randomized order (standard practice without technology assistance). We examined if the screening could have been stopped before identifying all relevant studies while still producing reliable summary estimates. For all meta-analyses, we also examined the relationship between the number of relevant studies and the reliability of the final estimates.
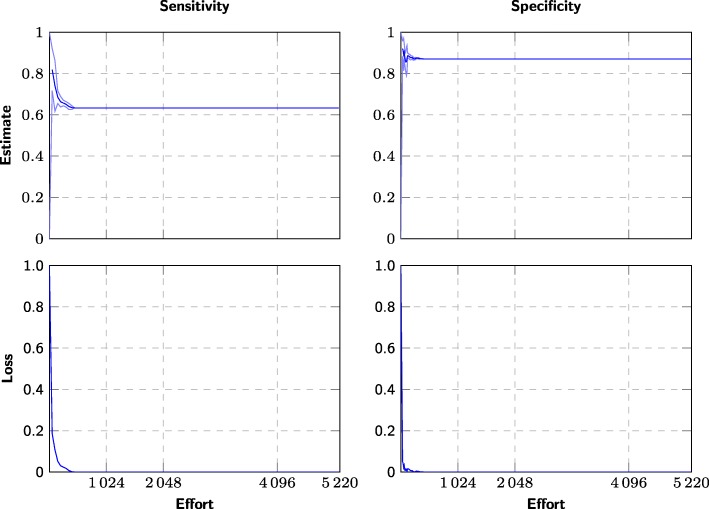
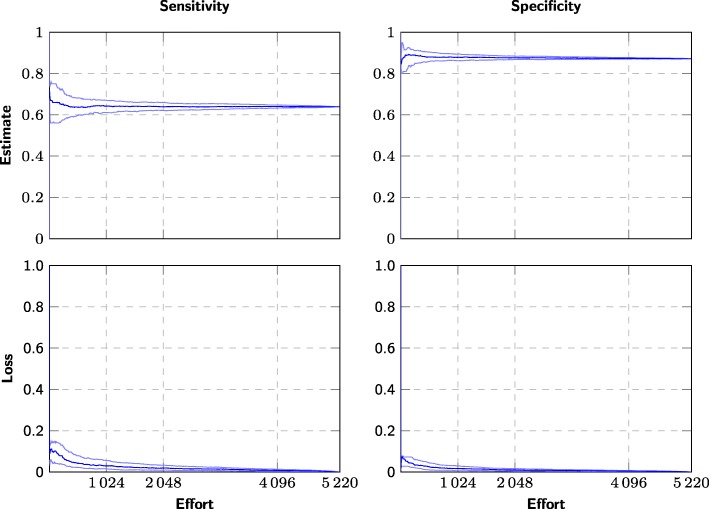
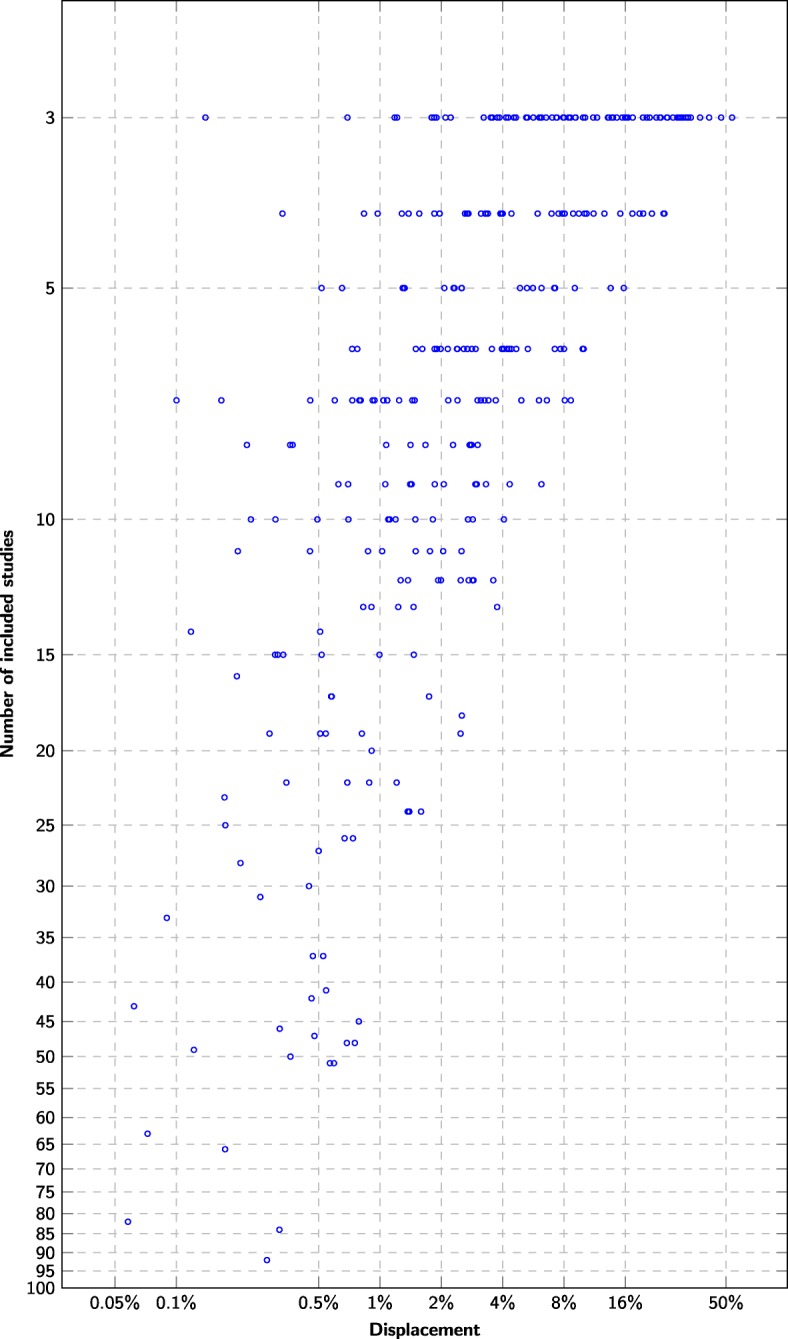
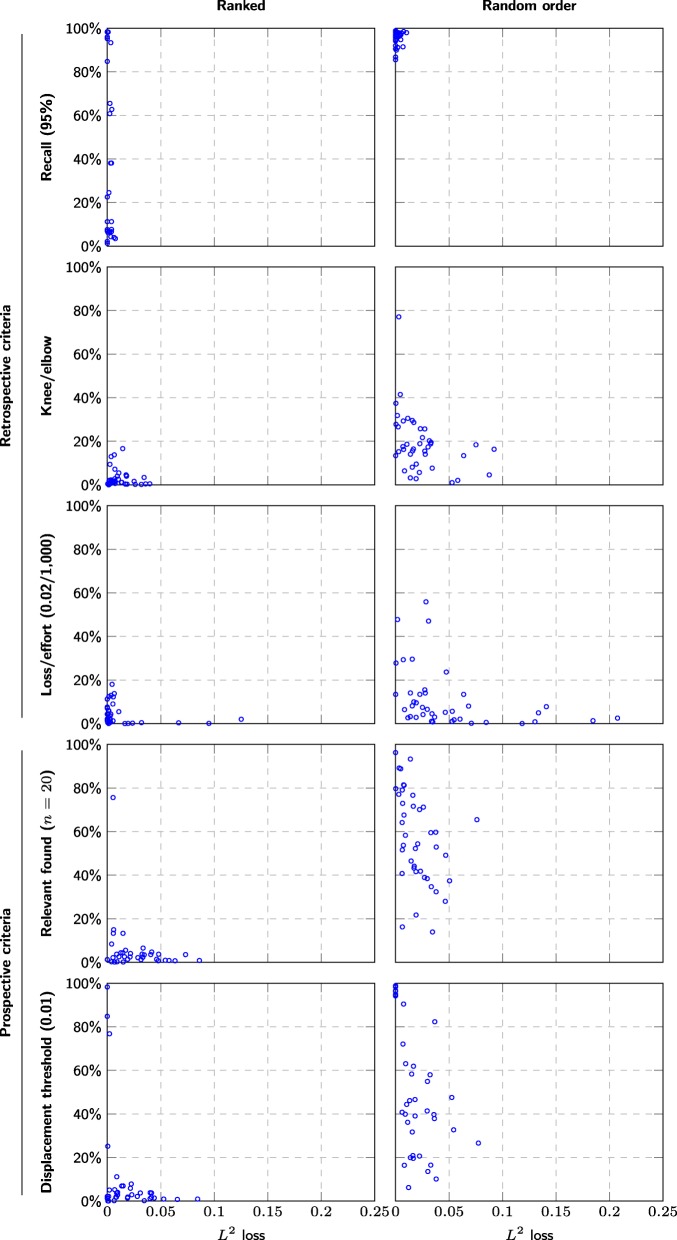
The main meta-analysis in each systematic review could have been performed after screening an average of 30% of the candidate articles (range 0.07 to 100%). No systematic review would have required screening more than 2308 studies, whereas manual screening would have required screening up to 43,363 studies. Despite an average 70% recall, the estimation error would have been 1.3% on average, compared to an average 2% estimation error expected when replicating summary estimate calculations.
Screening prioritization coupled with stopping criteria in diagnostic test accuracy reviews can reliably detect when the screening process has identified a sufficient number of studies to perform the main meta-analysis with an accuracy within pre-specified tolerance limits. However, many of the systematic reviews did not identify a sufficient number of studies that the meta-analyses were accurate within a 2% limit even with exhaustive manual screening, i.e., using current practice.
每年发表的大量新研究使得系统评价中的文献识别越来越耗时和昂贵。有人建议采用技术辅助作为传统手动文献识别的替代方法来降低成本,但以前的文献主要评估了方法的召回率(搜索灵敏度)和工作量减少。还需要评估筛选优先级方法是否会导致与全面手动筛选相同的结果和结论。在这项研究中,我们检查了一种基于主动学习的筛选优先级方法对诊断测试准确性系统评价中敏感性和特异性估计的影响。
我们模拟了 48 项 Cochrane 诊断测试准确性系统评价中的筛选过程,并基于至少 3 项研究重新运行了 400 项荟萃分析。我们比较了基于技术辅助的筛选优先级和随机筛选(无技术辅助的标准实践)。我们检查了是否可以在识别所有相关研究之前停止筛选,同时仍然可以产生可靠的汇总估计。对于所有荟萃分析,我们还检查了相关研究数量与最终估计可靠性之间的关系。
每项系统评价的主要荟萃分析平均可以在筛选出候选文章的 30%(范围 0.07 至 100%)后进行。没有一项系统评价需要筛选超过 2308 项研究,而手动筛选可能需要筛选多达 43363 项研究。尽管平均召回率为 70%,但估计误差平均为 1.3%,而复制汇总估计计算时预计的平均误差为 2%。
在诊断测试准确性评价中,结合停止标准的筛选优先级可以可靠地检测到筛选过程已经识别出足够数量的研究,以便在预先指定的容差范围内进行主要荟萃分析,并且具有准确性。然而,即使使用全面的手动筛选,许多系统评价也没有识别出足够数量的研究,使得荟萃分析在 2%的限制内具有准确性,即使用当前的实践。