Department of Electronics, Information and Bioengineering, Politecnico di Milano, Milan, Italy.
BMC Bioinformatics. 2019 Nov 8;20(1):560. doi: 10.1186/s12859-019-3159-9.
With the growth of available sequenced datasets, analysis of heterogeneous processed data can answer increasingly relevant biological and clinical questions. Scientists are challenged in performing efficient and reproducible data extraction and analysis pipelines over heterogeneously processed datasets. Available software packages are suitable for analyzing experimental files from such datasets one by one, but do not scale to thousands of experiments. Moreover, they lack proper support for metadata manipulation.
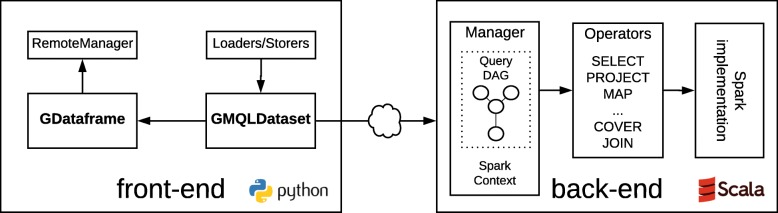
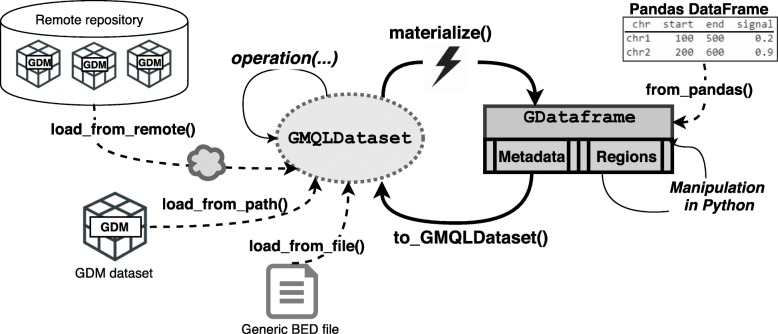
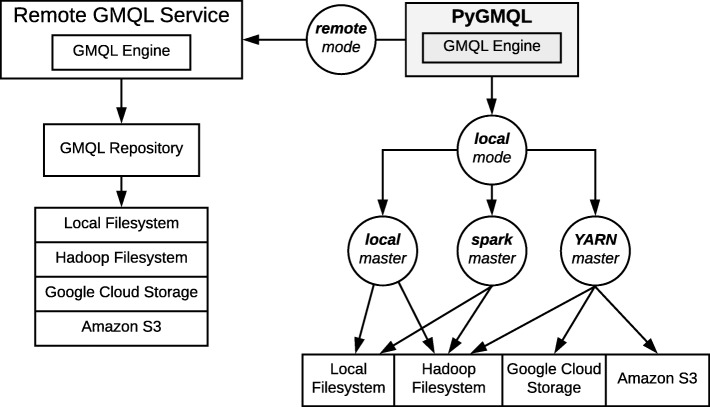
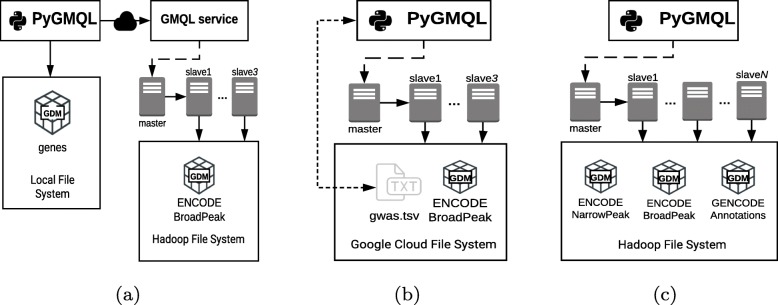
We present PyGMQL, a novel software for the manipulation of region-based genomic files and their relative metadata, built on top of the GMQL genomic big data management system. PyGMQL provides a set of expressive functions for the manipulation of region data and their metadata that can scale to arbitrary clusters and implicitly apply to thousands of files, producing millions of regions. PyGMQL provides data interoperability, distribution transparency and query outsourcing. The PyGMQL package integrates scalable data extraction over the Apache Spark engine underlying the GMQL implementation with native Python support for interactive data analysis and visualization. It supports data interoperability, solving the impedance mismatch between executing set-oriented queries and programming in Python. PyGMQL provides distribution transparency (the ability to address a remote dataset) and query outsourcing (the ability to assign processing to a remote service) in an orthogonal way. Outsourced processing can address cloud-based installations of the GMQL engine.
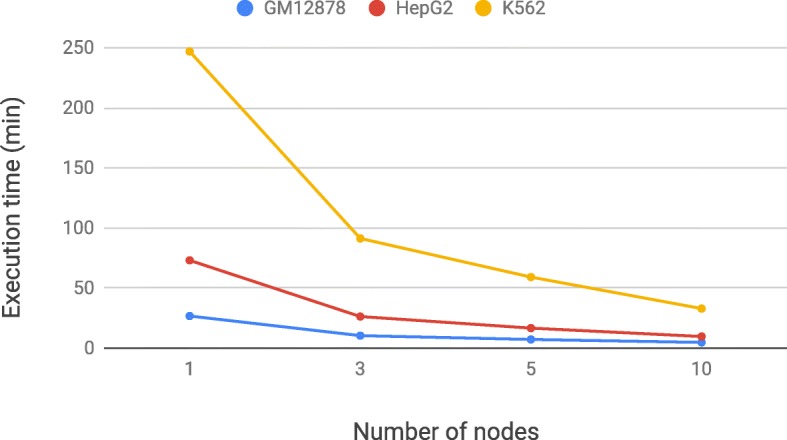
PyGMQL is an effective and innovative tool for supporting tertiary data extraction and analysis pipelines. We demonstrate the expressiveness and performance of PyGMQL through a sequence of biological data analysis scenarios of increasing complexity, which highlight reproducibility, expressive power and scalability.
随着可用测序数据集的增长,对异质处理数据的分析可以回答越来越相关的生物学和临床问题。科学家们在对异质处理数据集执行高效且可重复的数据提取和分析管道方面面临挑战。现有的软件包适用于逐个分析此类数据集的实验文件,但不适用于数千个实验。此外,它们缺乏适当的元数据处理支持。
我们提出了 PyGMQL,这是一种用于处理基于区域的基因组文件及其相对元数据的新型软件,构建在 GMQL 基因组大数据管理系统之上。PyGMQL 提供了一组用于处理区域数据及其元数据的表达性函数,可以扩展到任意集群,并隐式应用于数千个文件,生成数百万个区域。PyGMQL 提供数据互操作性、分布透明性和查询外包。PyGMQL 包集成了基于 Apache Spark 引擎的可扩展数据提取,该引擎是 GMQL 实现的基础,同时为交互式数据分析和可视化提供了本机 Python 支持。它支持数据互操作性,解决了在 Python 中执行基于集合的查询和编程之间的阻抗不匹配问题。PyGMQL 以正交的方式提供分布透明性(寻址远程数据集的能力)和查询外包(将处理分配给远程服务的能力)。外包处理可以解决 GMQL 引擎的基于云的安装问题。
PyGMQL 是支持三级数据提取和分析管道的有效且创新的工具。我们通过一系列越来越复杂的生物学数据分析场景展示了 PyGMQL 的表达能力和性能,突出了可重复性、表达能力和可扩展性。