Machine Learning Group, Sidra Medicine, Doha, Qatar.
Department of Computer Science and Engineering, Qatar University, Doha, Qatar.
BMC Med Inform Decis Mak. 2019 Nov 8;19(1):214. doi: 10.1186/s12911-019-0951-4.
Predictive modeling with longitudinal electronic health record (EHR) data offers great promise for accelerating personalized medicine and better informs clinical decision-making. Recently, deep learning models have achieved state-of-the-art performance for many healthcare prediction tasks. However, deep models lack interpretability, which is integral to successful decision-making and can lead to better patient care. In this paper, we build upon the contextual decomposition (CD) method, an algorithm for producing importance scores from long short-term memory networks (LSTMs). We extend the method to bidirectional LSTMs (BiLSTMs) and use it in the context of predicting future clinical outcomes using patients' EHR historical visits.
We use a real EHR dataset comprising 11071 patients, to evaluate and compare CD interpretations from LSTM and BiLSTM models. First, we train LSTM and BiLSTM models for the task of predicting which pre-school children with respiratory system-related complications will have asthma at school-age. After that, we conduct quantitative and qualitative analysis to evaluate the CD interpretations produced by the contextual decomposition of the trained models. In addition, we develop an interactive visualization to demonstrate the utility of CD scores in explaining predicted outcomes.
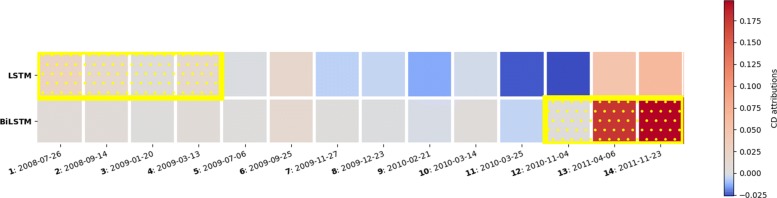
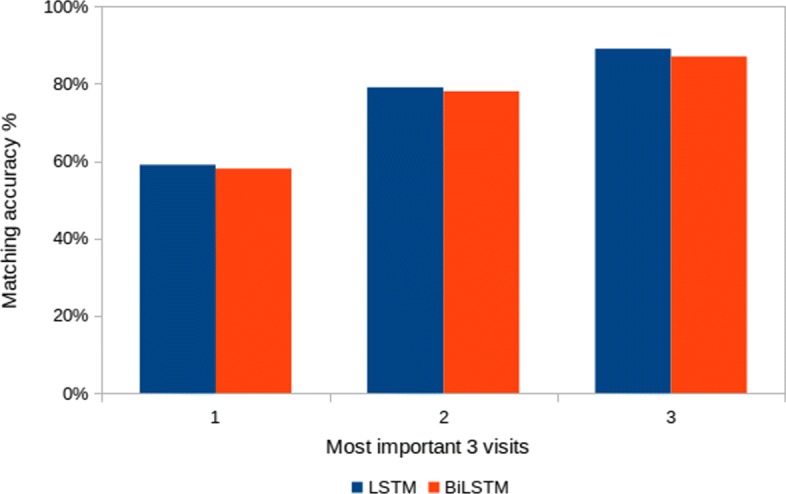
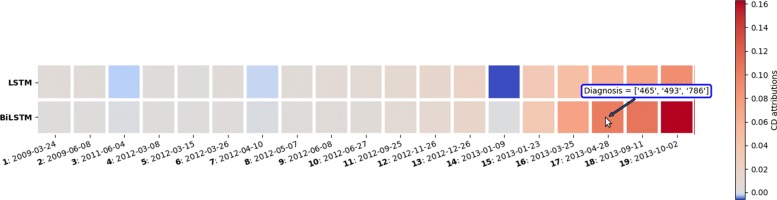
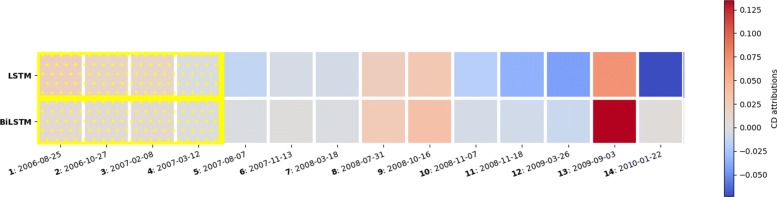
Our experimental evaluation demonstrate that whenever a clear visit-level pattern exists, the models learn that pattern and the contextual decomposition can appropriately attribute the prediction to the correct pattern. In addition, the results confirm that the CD scores agree to a large extent with the importance scores generated using logistic regression coefficients. Our main insight was that rather than interpreting the attribution of individual visits to the predicted outcome, we could instead attribute a model's prediction to a group of visits.
We presented a quantitative and qualitative evidence that CD interpretations can explain patient-specific predictions using CD attributions of individual visits or a group of visits.
利用纵向电子健康记录 (EHR) 数据进行预测建模为加速个性化医疗并为临床决策提供更好的信息提供了巨大的前景。最近,深度学习模型在许多医疗保健预测任务中达到了最先进的性能。然而,深度模型缺乏可解释性,这对于成功的决策至关重要,并可以导致更好的患者护理。在本文中,我们在上下文分解 (CD) 方法的基础上进行了构建,这是一种从长短期记忆网络 (LSTM) 生成重要性得分的算法。我们将该方法扩展到双向 LSTM (BiLSTM),并将其用于使用患者的 EHR 历史就诊记录预测未来临床结果的上下文中。
我们使用包含 11071 名患者的真实 EHR 数据集,评估和比较 LSTM 和 BiLSTM 模型的 CD 解释。首先,我们训练 LSTM 和 BiLSTM 模型来预测呼吸系统相关并发症的学龄前儿童在学龄期是否会患有哮喘。之后,我们进行定量和定性分析,以评估从训练模型的上下文分解中产生的 CD 解释。此外,我们开发了一个交互式可视化工具,以演示 CD 分数在解释预测结果方面的实用性。
我们的实验评估表明,只要存在明确的就诊级模式,模型就会学习该模式,上下文分解可以适当地将预测归因于正确的模式。此外,结果证实 CD 分数在很大程度上与使用逻辑回归系数生成的重要性分数一致。我们的主要见解是,我们可以将模型的预测归因于一组就诊,而不是解释对预测结果的个别就诊的归因。
我们提供了定量和定性的证据,表明 CD 解释可以使用对个体就诊或一组就诊的 CD 归因来解释患者特定的预测。