Institute of Cardiovascular Science, University College London, London, UK.
Health Data Research UK and UCL BHF Research Accelerator, London, UK.
Sci Rep. 2019 Dec 11;9(1):18911. doi: 10.1038/s41598-019-54849-w.
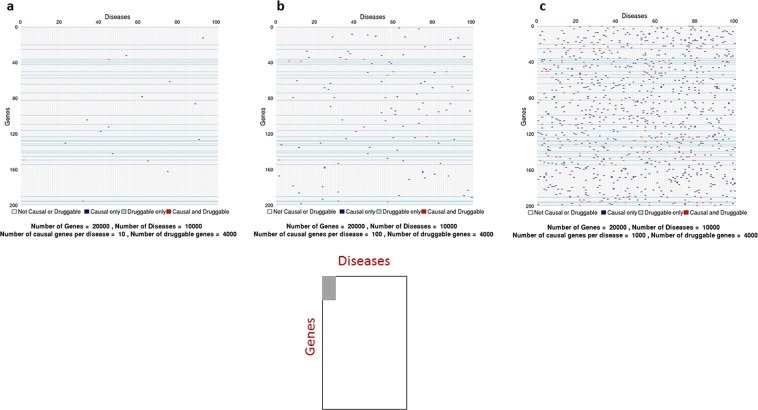
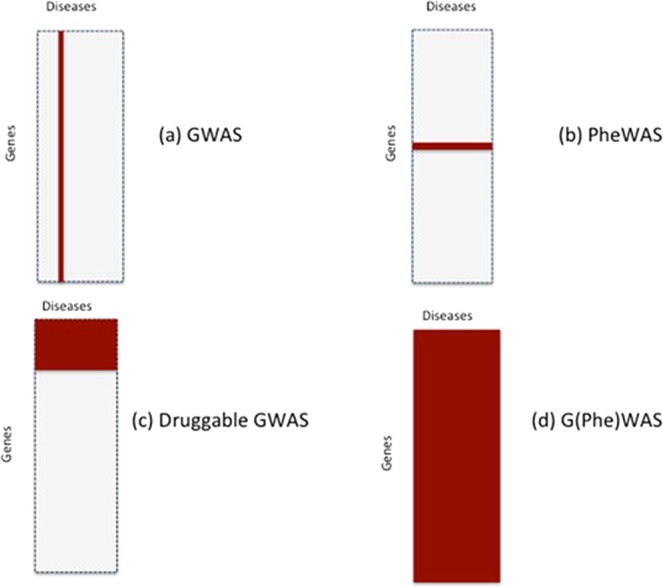
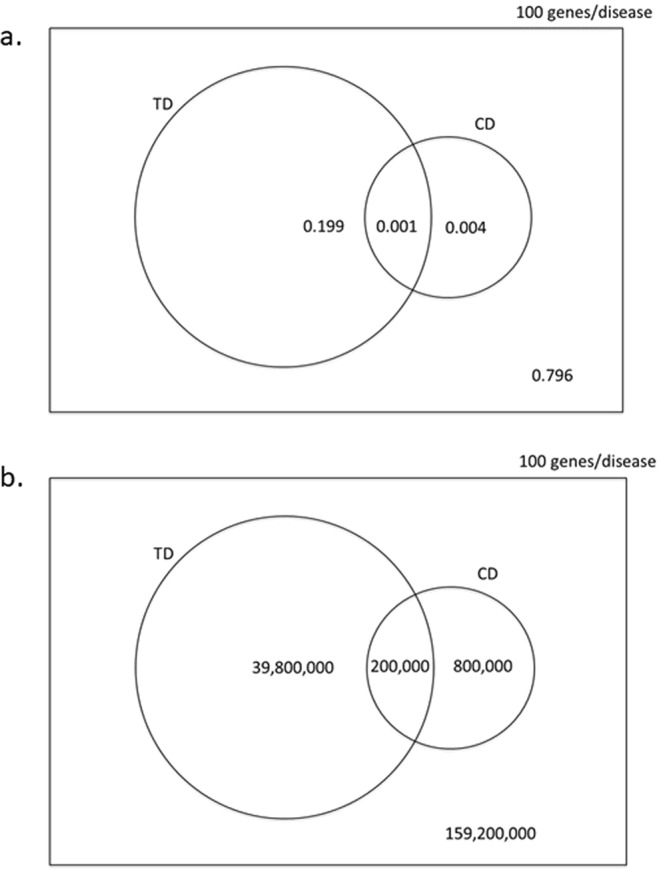
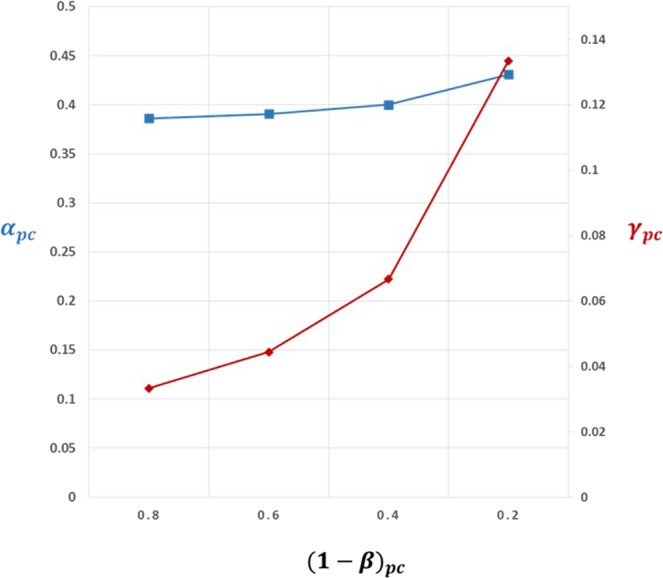
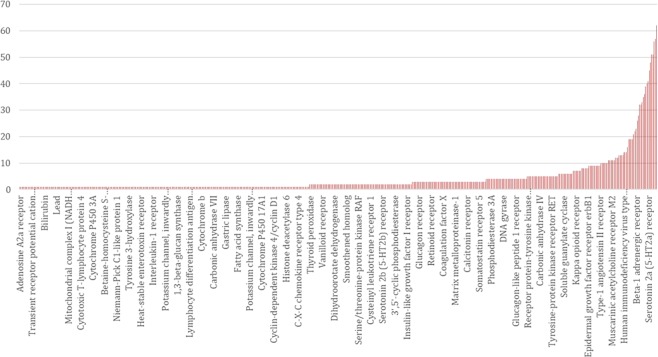
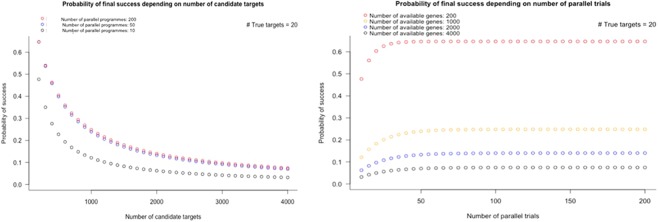
Lack of efficacy in the intended disease indication is the major cause of clinical phase drug development failure. Explanations could include the poor external validity of pre-clinical (cell, tissue, and animal) models of human disease and the high false discovery rate (FDR) in preclinical science. FDR is related to the proportion of true relationships available for discovery (γ), and the type 1 (false-positive) and type 2 (false negative) error rates of the experiments designed to uncover them. We estimated the FDR in preclinical science, its effect on drug development success rates, and improvements expected from use of human genomics rather than preclinical studies as the primary source of evidence for drug target identification. Calculations were based on a sample space defined by all human diseases - the 'disease-ome' - represented as columns; and all protein coding genes - 'the protein-coding genome'- represented as rows, producing a matrix of unique gene- (or protein-) disease pairings. We parameterised the space based on 10,000 diseases, 20,000 protein-coding genes, 100 causal genes per disease and 4000 genes encoding druggable targets, examining the effect of varying the parameters and a range of underlying assumptions, on the inferences drawn. We estimated γ, defined mathematical relationships between preclinical FDR and drug development success rates, and estimated improvements in success rates based on human genomics (rather than orthodox preclinical studies). Around one in every 200 protein-disease pairings was estimated to be causal (γ = 0.005) giving an FDR in preclinical research of 92.6%, which likely makes a major contribution to the reported drug development failure rate of 96%. Observed success rate was only slightly greater than expected for a random pick from the sample space. Values for γ back-calculated from reported preclinical and clinical drug development success rates were also close to the a priori estimates. Substituting genome wide (or druggable genome wide) association studies for preclinical studies as the major information source for drug target identification was estimated to reverse the probability of late stage failure because of the more stringent type 1 error rate employed and the ability to interrogate every potential druggable target in the same experiment. Genetic studies conducted at much larger scale, with greater resolution of disease end-points, e.g. by connecting genomics and electronic health record data within healthcare systems has the potential to produce radical improvement in drug development success rate.
在预期疾病适应证中缺乏疗效是临床阶段药物开发失败的主要原因。原因可能包括人类疾病的临床前(细胞、组织和动物)模型的外部有效性较差,以及临床前科学中的高假发现率(FDR)。FDR 与可发现的真实关系比例(γ)有关,以及旨在发现这些关系的实验的Ⅰ型(假阳性)和Ⅱ型(假阴性)错误率有关。我们估计了临床前科学中的 FDR,它对药物开发成功率的影响,以及使用人类基因组学而不是临床前研究作为药物靶点识别的主要证据来源预计会带来的改进。计算基于一个由所有人类疾病定义的样本空间——“疾病组”——表示为列;以及所有编码蛋白的基因——“编码蛋白基因组”——表示为行,生成一个独特的基因-(或蛋白)-疾病配对矩阵。我们根据 10000 种疾病、20000 个编码蛋白的基因、每种疾病的 100 个因果基因和 4000 个编码可成药靶点的基因,对空间进行了参数化,检查了改变参数和一系列潜在假设对推断的影响。我们估计了γ,定义了临床前 FDR 和药物开发成功率之间的数学关系,并根据人类基因组学(而不是传统的临床前研究)估计了成功率的提高。估计每 200 个蛋白-疾病对中约有 1 个是因果关系(γ=0.005),这使得临床前研究中的 FDR 达到 92.6%,这可能是报告的药物开发失败率为 96%的主要原因。观察到的成功率仅略高于从样本空间中随机选择的预期值。从报告的临床前和临床药物开发成功率中反向计算出的γ值也接近先验估计值。用全基因组(或可成药基因组)关联研究替代临床前研究作为药物靶点识别的主要信息来源,预计会因为采用更严格的Ⅰ型错误率和能够在同一个实验中检测每个潜在的可成药靶点而扭转由于后期失败的概率。在更大规模、疾病终点分辨率更高的遗传研究中,例如通过在医疗保健系统内连接基因组学和电子健康记录数据,有可能使药物开发成功率得到大幅提高。