Predictive Society and Data Analytics Lab, Tampere University, Tampere, Korkeakoulunkatu 10, 33720, Tampere, Finland.
Steyr School of Management, University of Applied Sciences Upper Austria, 4400, Steyr Campus, Austria.
Sci Rep. 2020 Jan 29;10(1):1432. doi: 10.1038/s41598-020-58178-1.
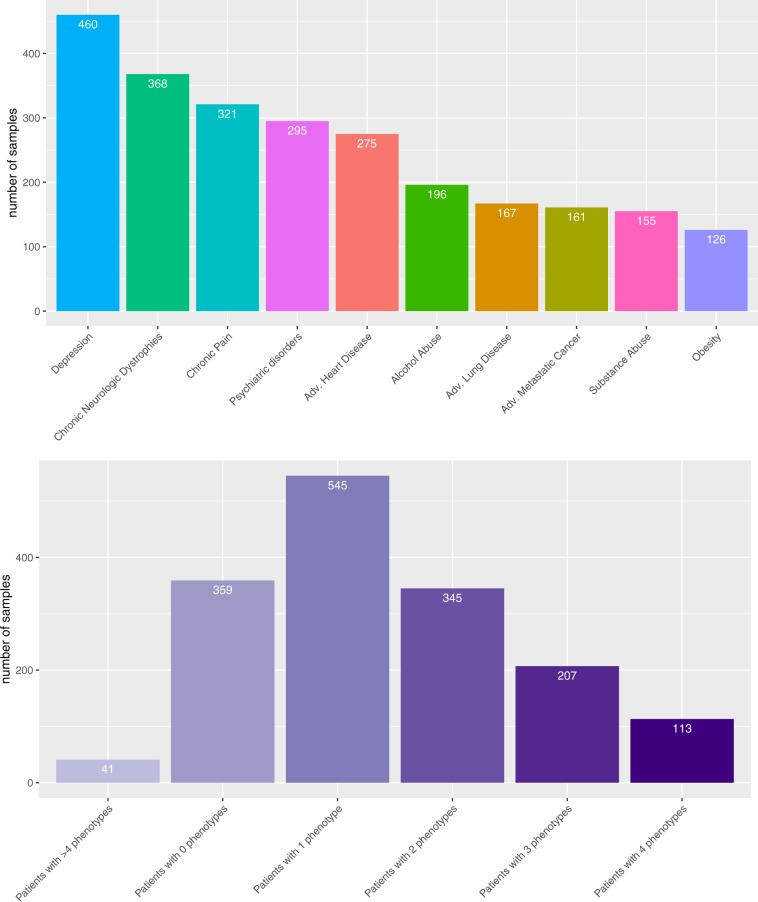
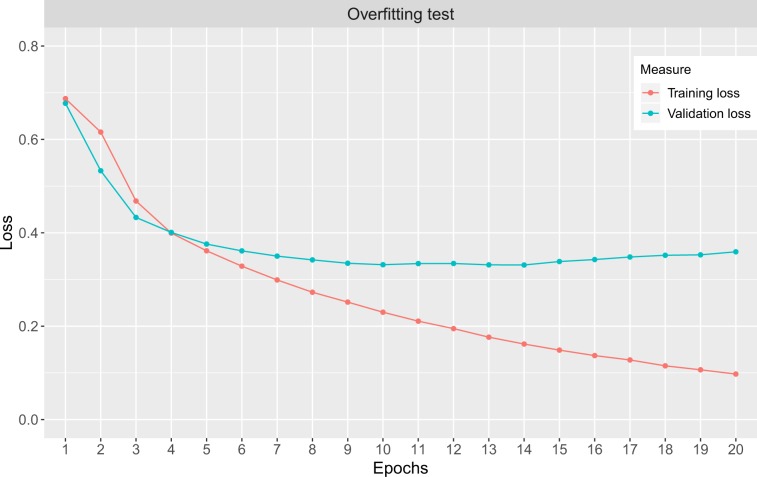
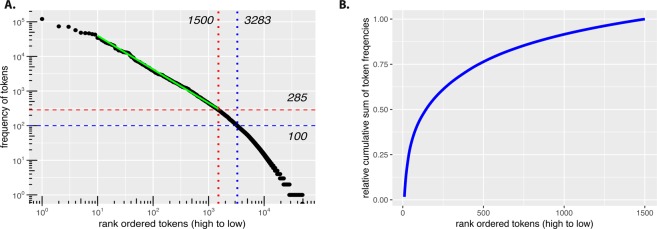
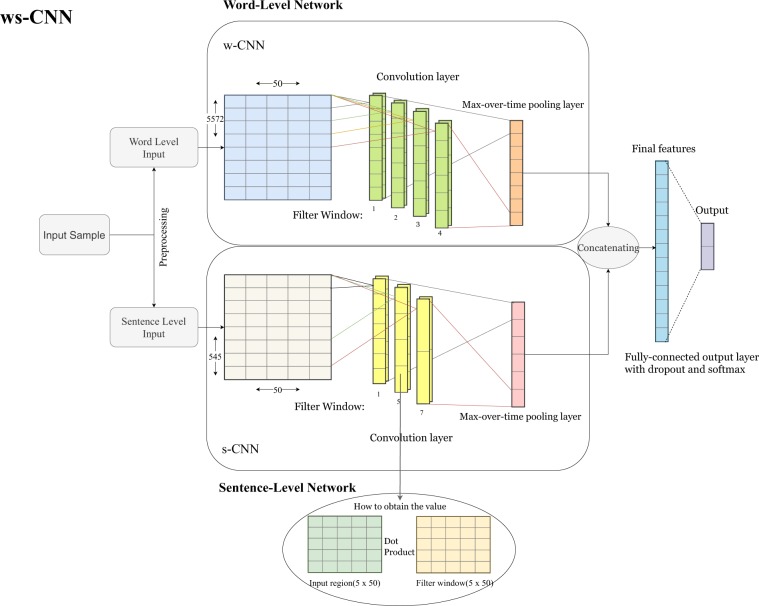
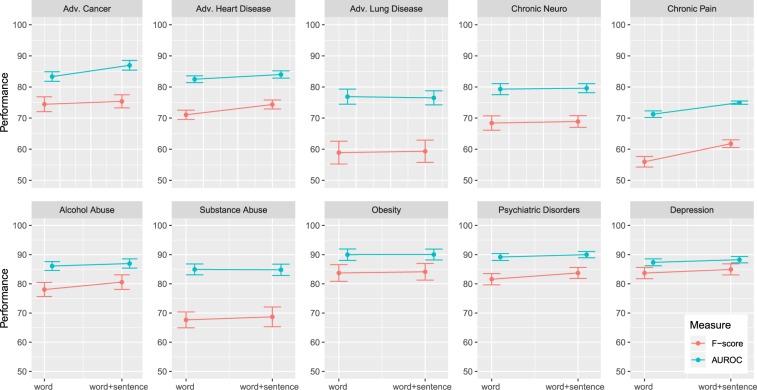
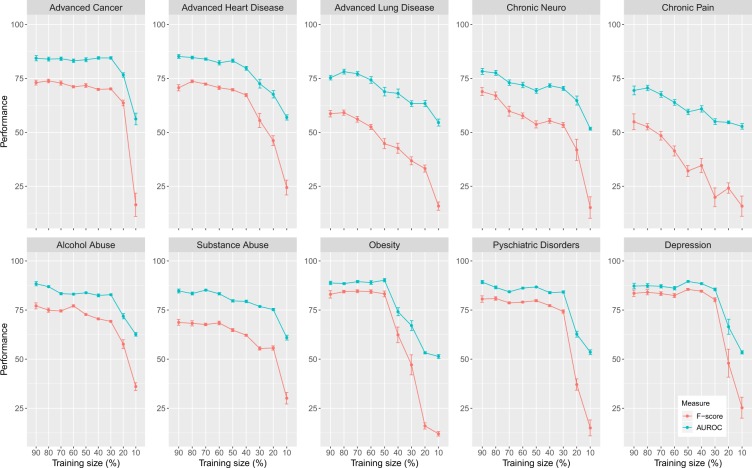
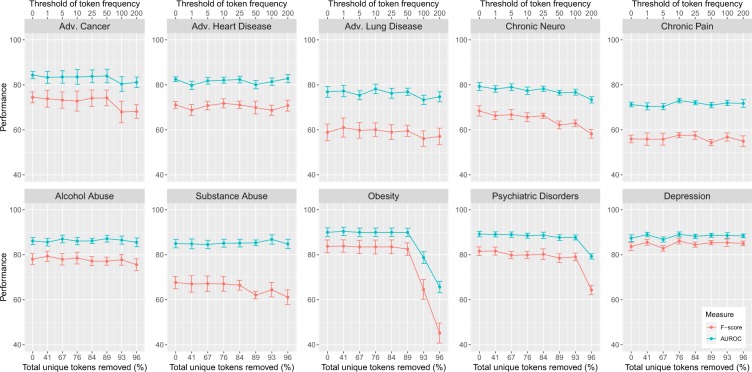
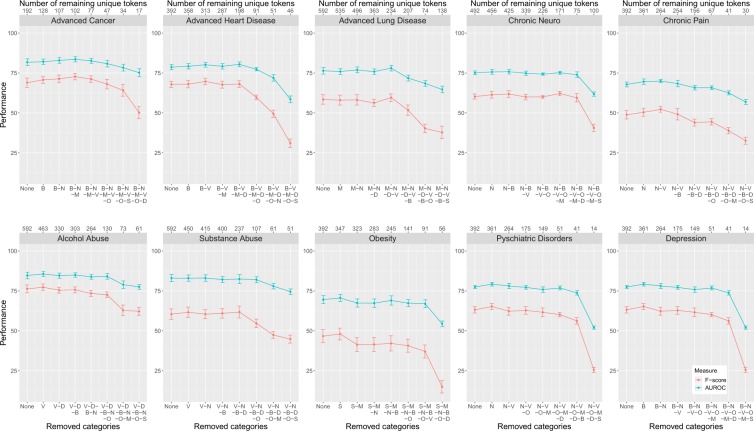
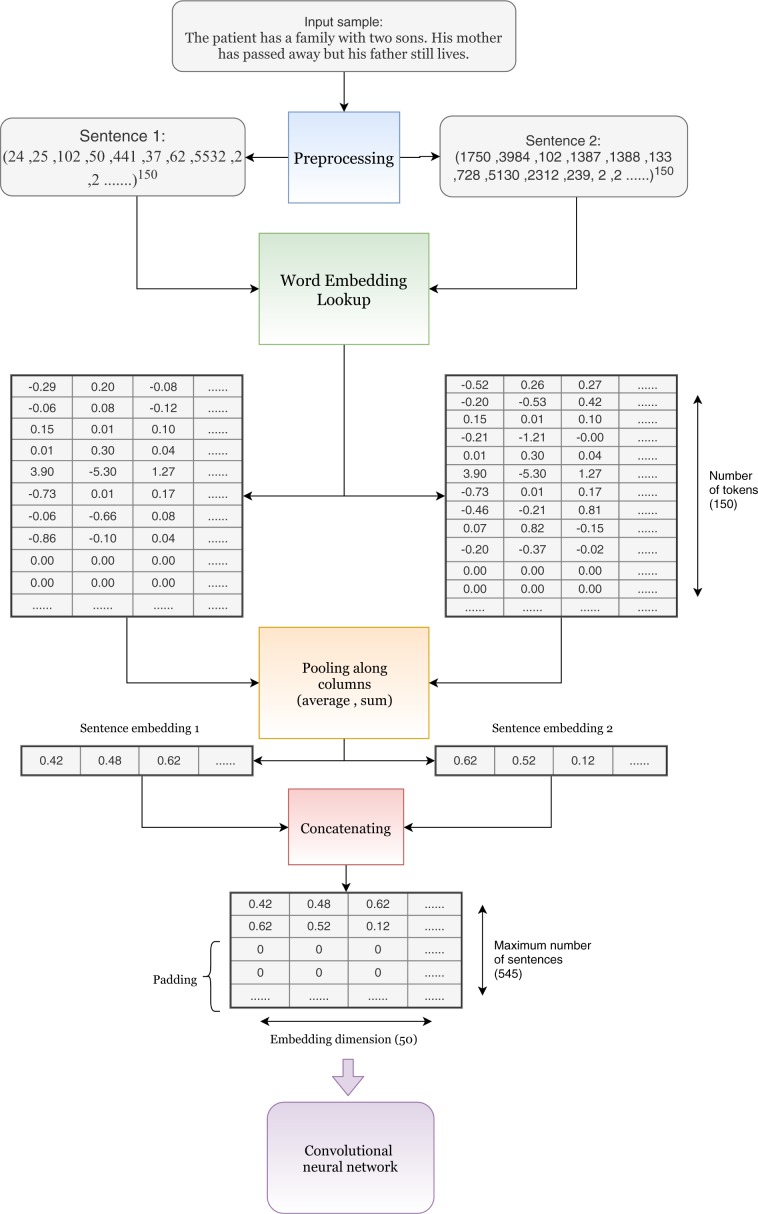
Artificial intelligence provides the opportunity to reveal important information buried in large amounts of complex data. Electronic health records (eHRs) are a source of such big data that provide a multitude of health related clinical information about patients. However, text data from eHRs, e.g., discharge summary notes, are challenging in their analysis because these notes are free-form texts and the writing formats and styles vary considerably between different records. For this reason, in this paper we study deep learning neural networks in combination with natural language processing to analyze text data from clinical discharge summaries. We provide a detail analysis of patient phenotyping, i.e., the automatic prediction of ten patient disorders, by investigating the influence of network architectures, sample sizes and information content of tokens. Importantly, for patients suffering from Chronic Pain, the disorder that is the most difficult one to classify, we find the largest performance gain for a combined word- and sentence-level input convolutional neural network (ws-CNN). As a general result, we find that the combination of data quality and data quantity of the text data is playing a crucial role for using more complex network architectures that improve significantly beyond a word-level input CNN model. From our investigations of learning curves and token selection mechanisms, we conclude that for such a transition one requires larger sample sizes because the amount of information per sample is quite small and only carried by few tokens and token categories. Interestingly, we found that the token frequency in the eHRs follow a Zipf law and we utilized this behavior to investigate the information content of tokens by defining a token selection mechanism. The latter addresses also issues of explainable AI.
人工智能提供了揭示隐藏在大量复杂数据中的重要信息的机会。电子健康记录(EHR)是此类大数据的来源,提供了大量与患者相关的临床信息。然而,EHR 中的文本数据,例如出院小结,在分析时具有挑战性,因为这些记录是自由格式的文本,并且不同记录之间的书写格式和风格差异很大。出于这个原因,在本文中,我们研究了深度学习神经网络与自然语言处理的结合,以分析来自临床出院小结的文本数据。我们通过研究网络架构、样本大小和标记信息含量对患者表型分析(即自动预测十种患者疾病)进行了详细分析。重要的是,对于患有慢性疼痛的患者,这种疾病是最难分类的,我们发现对于组合的词和句子级输入卷积神经网络(ws-CNN),可以获得最大的性能提升。一般来说,我们发现文本数据的质量和数量的结合对于使用更复杂的网络架构至关重要,这些架构的性能显著优于基于词级输入的 CNN 模型。从我们对学习曲线和标记选择机制的研究中,我们得出结论,对于这种转变,需要更大的样本量,因为每个样本的信息量很小,只能通过少数标记和标记类别来承载。有趣的是,我们发现 EHR 中的标记频率遵循 Zipf 定律,我们利用这种行为通过定义标记选择机制来研究标记的信息含量。后者还解决了人工智能可解释性的问题。