SDU Health Informatics and Technology, The Maersk Mc-Kinney Moller Institute, University of Southern Denmark, Odense, 5230, Denmark.
Department of Oncology, Lillebaelt Hospital, University Hospital of Southern Denmark, Vejle, 7100, Denmark.
BMC Med Res Methodol. 2024 May 17;24(1):114. doi: 10.1186/s12874-024-02231-4.
Smoking is a critical risk factor responsible for over eight million annual deaths worldwide. It is essential to obtain information on smoking habits to advance research and implement preventive measures such as screening of high-risk individuals. In most countries, including Denmark, smoking habits are not systematically recorded and at best documented within unstructured free-text segments of electronic health records (EHRs). This would require researchers and clinicians to manually navigate through extensive amounts of unstructured data, which is one of the main reasons that smoking habits are rarely integrated into larger studies. Our aim is to develop machine learning models to classify patients' smoking status from their EHRs.
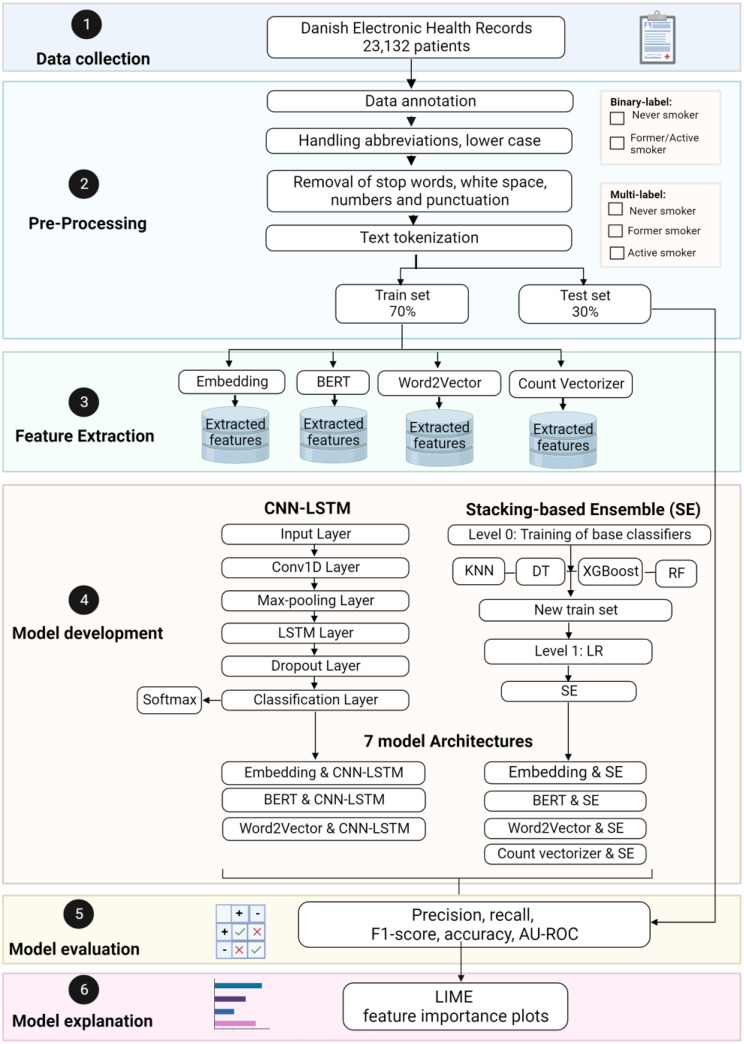
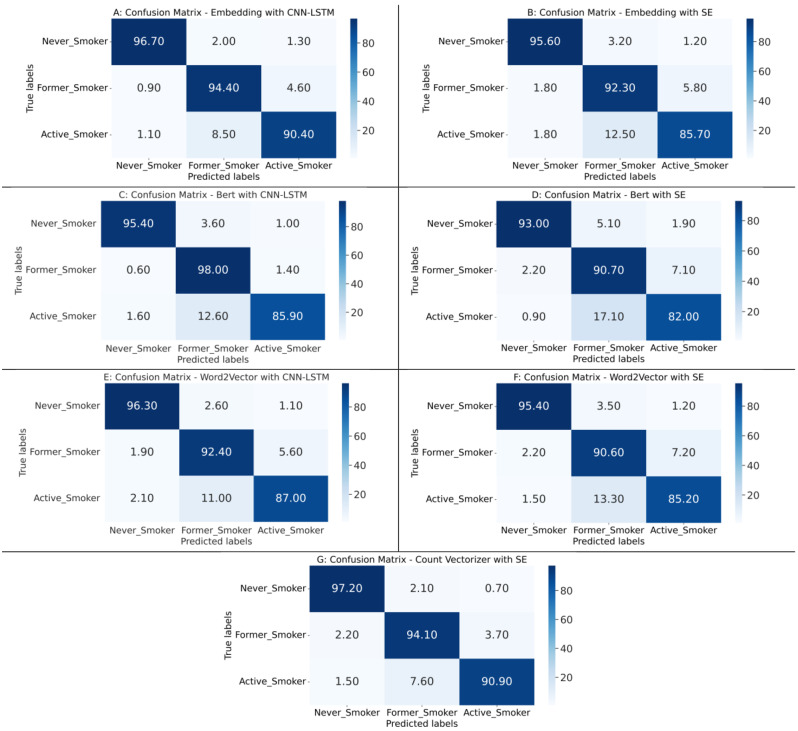
This study proposes an efficient natural language processing (NLP) pipeline capable of classifying patients' smoking status and providing explanations for the decisions. The proposed NLP pipeline comprises four distinct components, which are; (1) considering preprocessing techniques to address abbreviations, punctuation, and other textual irregularities, (2) four cutting-edge feature extraction techniques, i.e. Embedding, BERT, Word2Vec, and Count Vectorizer, employed to extract the optimal features, (3) utilization of a Stacking-based Ensemble (SE) model and a Convolutional Long Short-Term Memory Neural Network (CNN-LSTM) for the identification of smoking status, and (4) application of a local interpretable model-agnostic explanation to explain the decisions rendered by the detection models. The EHRs of 23,132 patients with suspected lung cancer were collected from the Region of Southern Denmark during the period 1/1/2009-31/12/2018. A medical professional annotated the data into 'Smoker' and 'Non-Smoker' with further classifications as 'Active-Smoker', 'Former-Smoker', and 'Never-Smoker'. Subsequently, the annotated dataset was used for the development of binary and multiclass classification models. An extensive comparison was conducted of the detection performance across various model architectures.
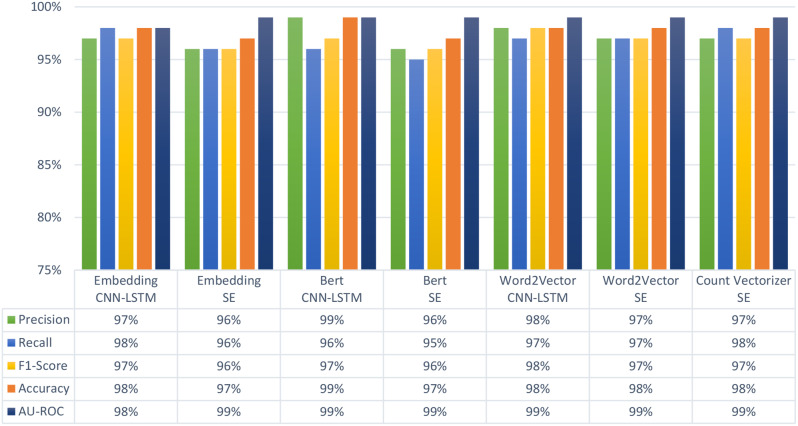
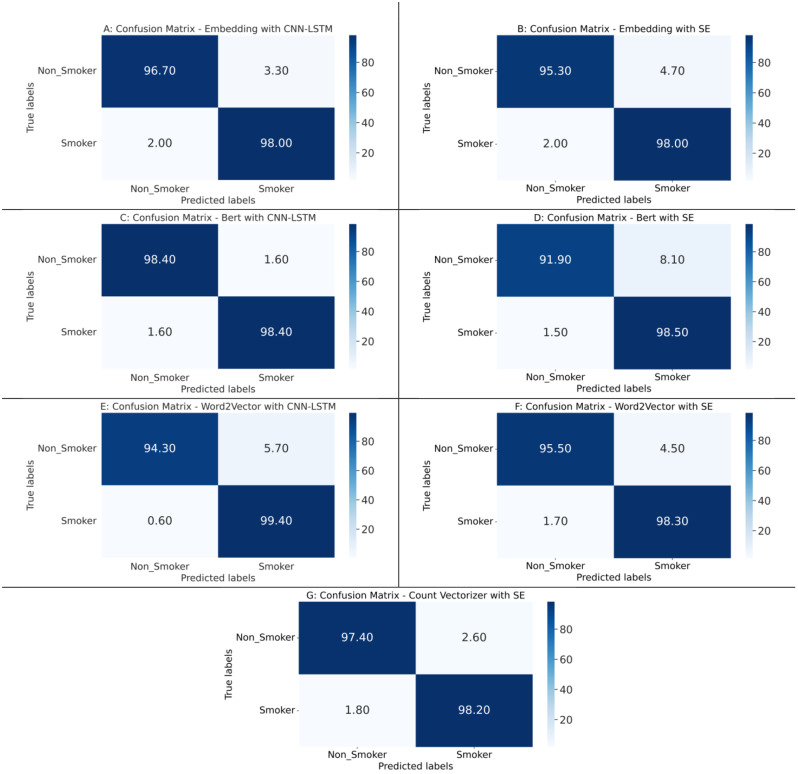
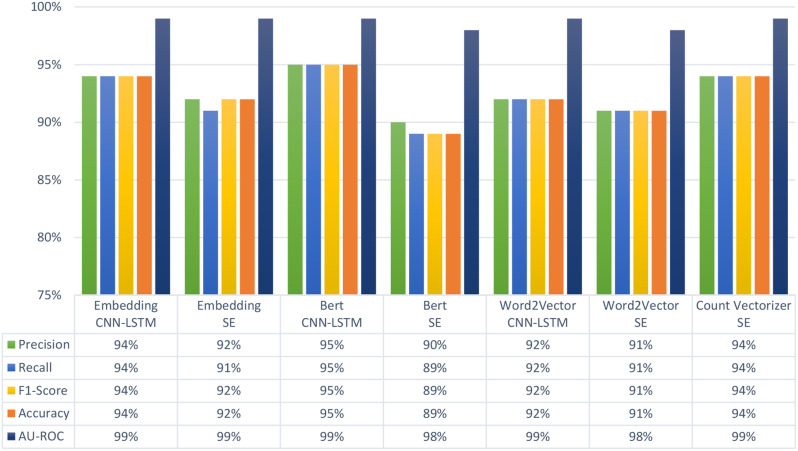
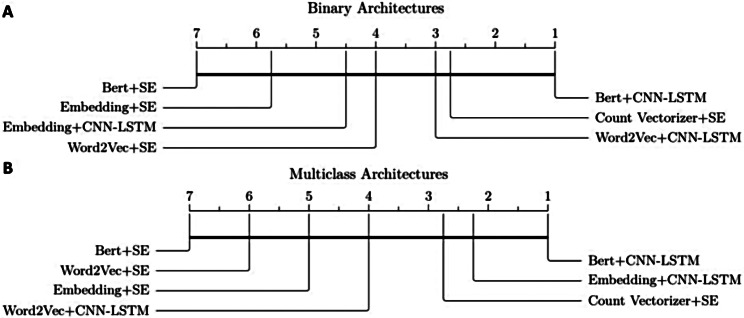
The results of experimental validation confirm the consistency among the models. However, for binary classification, BERT method with CNN-LSTM architecture outperformed other models by achieving precision, recall, and F1-scores between 97% and 99% for both Never-Smokers and Active-Smokers. In multiclass classification, the Embedding technique with CNN-LSTM architecture yielded the most favorable results in class-specific evaluations, with equal performance measures of 97% for Never-Smoker and measures in the range of 86 to 89% for Active-Smoker and 91-92% for Never-Smoker.
Our proposed NLP pipeline achieved a high level of classification performance. In addition, we presented the explanation of the decision made by the best performing detection model. Future work will expand the model's capabilities to analyze longer notes and a broader range of categories to maximize its utility in further research and screening applications.
吸烟是一个关键的风险因素,导致全球每年有超过 800 万人死亡。了解吸烟习惯对于推进研究和实施预防措施(如对高危人群进行筛查)至关重要。在大多数国家,包括丹麦,吸烟习惯并没有系统地记录,最多也只是在电子健康记录(EHR)的非结构化自由文本段中记录。这将要求研究人员和临床医生手动浏览大量的非结构化数据,这也是吸烟习惯很少被纳入更大规模研究的主要原因之一。我们的目标是开发机器学习模型,以便从 EHR 中对患者的吸烟状况进行分类。
本研究提出了一种高效的自然语言处理(NLP)管道,能够对患者的吸烟状况进行分类,并对决策提供解释。所提出的 NLP 管道由四个不同的组件组成,包括:(1)考虑预处理技术,以解决缩写、标点符号和其他文本不规则性问题;(2)四种先进的特征提取技术,即嵌入、BERT、Word2Vec 和计数向量器,用于提取最佳特征;(3)使用基于堆叠的集成(SE)模型和卷积长短期记忆神经网络(CNN-LSTM)来识别吸烟状况;(4)应用局部可解释的无模型解释方法来解释检测模型做出的决策。该研究从 2009 年 1 月 1 日至 2018 年 12 月 31 日期间从丹麦南部地区收集了 23132 名疑似肺癌患者的 EHR。一名医疗专业人员将数据标注为“吸烟者”和“非吸烟者”,并进一步细分为“活跃吸烟者”、“前吸烟者”和“从不吸烟者”。随后,对标注数据集进行了二元和多类分类模型的开发。对各种模型架构的检测性能进行了广泛比较。
实验验证的结果证实了模型之间的一致性。然而,对于二元分类,BERT 方法与 CNN-LSTM 架构的表现优于其他模型,Never-Smoker 和 Active-Smoker 的准确率、召回率和 F1 得分均在 97%至 99%之间。在多类分类中,嵌入技术与 CNN-LSTM 架构在类别特定评估中产生了最有利的结果,Never-Smoker 的性能指标相同,均为 97%,而 Active-Smoker 的指标范围为 86%至 89%,Never-Smoker 的指标为 91%至 92%。
我们提出的 NLP 管道实现了高水平的分类性能。此外,我们还展示了最佳检测模型决策的解释。未来的工作将扩展模型的功能,以分析更长的笔记和更广泛的类别,从而最大限度地提高其在进一步研究和筛选应用中的效用。