Google Research, Google LLC, 1600 Amphitheatre Parkway, Mountain View, CA, USA.
, Palo Alto, CA, USA.
BMC Med Inform Decis Mak. 2020 Jan 30;20(1):14. doi: 10.1186/s12911-020-1026-2.
Automated machine-learning systems are able to de-identify electronic medical records, including free-text clinical notes. Use of such systems would greatly boost the amount of data available to researchers, yet their deployment has been limited due to uncertainty about their performance when applied to new datasets.
We present practical options for clinical note de-identification, assessing performance of machine learning systems ranging from off-the-shelf to fully customized.
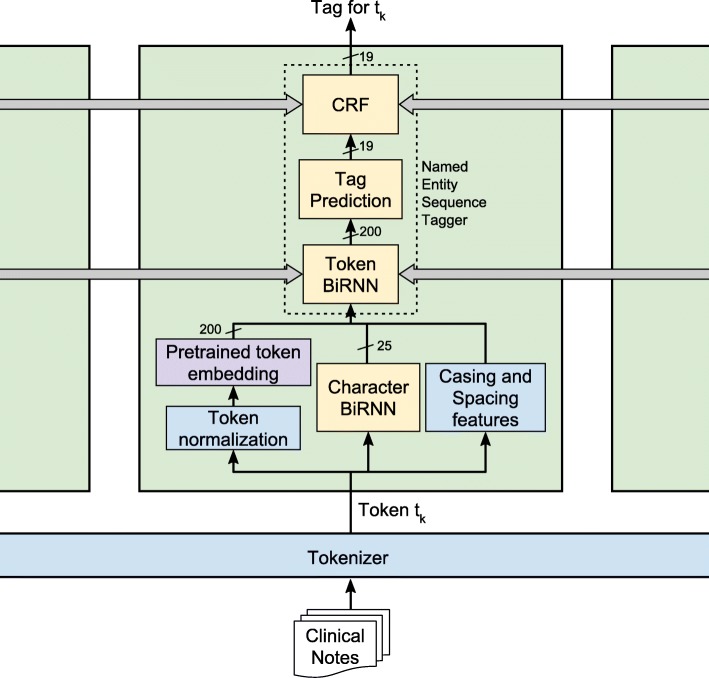
We implement a state-of-the-art machine learning de-identification system, training and testing on pairs of datasets that match the deployment scenarios. We use clinical notes from two i2b2 competition corpora, the Physionet Gold Standard corpus, and parts of the MIMIC-III dataset.
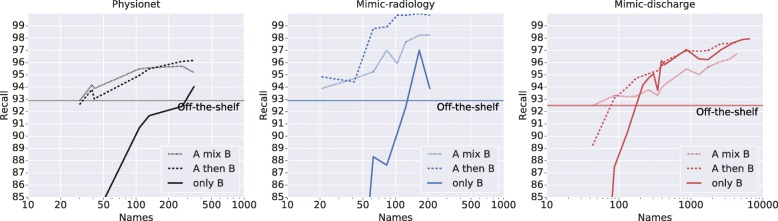
Fully customized systems remove 97-99% of personally identifying information. Performance of off-the-shelf systems varies by dataset, with performance mostly above 90%. Providing a small labeled dataset or large unlabeled dataset allows for fine-tuning that improves performance over off-the-shelf systems.
Health organizations should be aware of the levels of customization available when selecting a de-identification deployment solution, in order to choose the one that best matches their resources and target performance level.
自动化机器学习系统能够对电子病历(包括自由文本临床记录)进行去识别化。此类系统的使用将极大地增加研究人员可获取的数据量,但由于其在应用于新数据集时的性能存在不确定性,因此其部署受到了限制。
我们提出了临床记录去识别化的实用选项,评估了从现成的到完全定制的机器学习系统的性能。
我们实现了最先进的机器学习去识别化系统,在匹配部署场景的数据集对上进行训练和测试。我们使用了来自两个 i2b2 竞赛语料库、Physionet 金标准语料库以及 MIMIC-III 数据集的部分内容的临床记录。
完全定制的系统可以去除 97%-99%的个人识别信息。现成系统的性能因数据集而异,大多数性能超过 90%。提供一个小的有标签数据集或大的无标签数据集可以进行微调,从而提高现成系统的性能。
医疗组织在选择去识别化部署解决方案时应了解可用的定制化程度,以便选择最符合其资源和目标性能水平的解决方案。