Center for Genomics and Systems Biology, Department of Biology, New York University, New York, NY, USA.
Oxford Nanopore Technologies, New York, NY, USA.
Genome Biol. 2020 Feb 5;21(1):21. doi: 10.1186/s13059-020-1938-2.
The circum-basmati group of cultivated Asian rice (Oryza sativa) contains many iconic varieties and is widespread in the Indian subcontinent. Despite its economic and cultural importance, a high-quality reference genome is currently lacking, and the group's evolutionary history is not fully resolved. To address these gaps, we use long-read nanopore sequencing and assemble the genomes of two circum-basmati rice varieties.
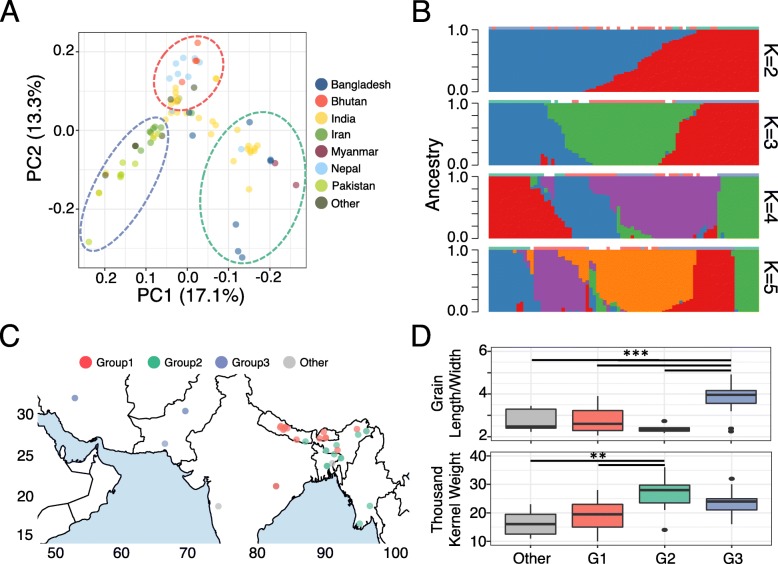
We generate two high-quality, chromosome-level reference genomes that represent the 12 chromosomes of Oryza. The assemblies show a contig N50 of 6.32 Mb and 10.53 Mb for Basmati 334 and Dom Sufid, respectively. Using our highly contiguous assemblies, we characterize structural variations segregating across circum-basmati genomes. We discover repeat expansions not observed in japonica-the rice group most closely related to circum-basmati-as well as the presence and absence variants of over 20 Mb, one of which is a circum-basmati-specific deletion of a gene regulating awn length. We further detect strong evidence of admixture between the circum-basmati and circum-aus groups. This gene flow has its greatest effect on chromosome 10, causing both structural variation and single-nucleotide polymorphism to deviate from genome-wide history. Lastly, population genomic analysis of 78 circum-basmati varieties shows three major geographically structured genetic groups: Bhutan/Nepal, India/Bangladesh/Myanmar, and Iran/Pakistan.
The availability of high-quality reference genomes allows functional and evolutionary genomic analyses providing genome-wide evidence for gene flow between circum-aus and circum-basmati, describes the nature of circum-basmati structural variation, and reveals the presence/absence variation in this important and iconic rice variety group.
栽培亚洲稻的籼稻亚种群(Oryza sativa)包含许多标志性品种,广泛分布于印度次大陆。尽管它具有经济和文化重要性,但目前缺乏高质量的参考基因组,并且该群体的进化历史尚未完全解决。为了解决这些差距,我们使用长读长纳米孔测序技术组装了两个籼稻亚种品种的基因组。
我们生成了两个高质量的染色体水平参考基因组,代表了 Oryza 的 12 条染色体。组装结果显示 Basmati 334 和 Dom Sufid 的 contig N50 分别为 6.32 Mb 和 10.53 Mb。利用我们高度连续的组装结果,我们对籼稻亚种基因组中分离的结构变异进行了特征描述。我们发现了在粳稻(与籼稻亚种最接近的水稻群体)中未观察到的重复扩展,以及超过 20 Mb 的存在和缺失变体,其中一个是一个调节芒长的基因的籼稻亚种特异性缺失。我们进一步检测到籼稻亚种和籼稻亚种群之间强烈的混合证据。这种基因流对 10 号染色体的影响最大,导致结构变异和单核苷酸多态性偏离全基因组历史。最后,对 78 个籼稻亚种品种的群体基因组分析显示出三个主要的地理结构遗传群体:不丹/尼泊尔、印度/孟加拉国/缅甸和伊朗/巴基斯坦。
高质量参考基因组的可用性允许进行功能和进化基因组分析,为籼稻亚种和籼稻亚种群之间的基因流动提供了全基因组证据,描述了籼稻亚种结构变异的性质,并揭示了这个重要和标志性水稻品种群体中的存在/缺失变异。