College of Information and Computer Engineering, Northeast Forestry University, No.26 Hexing Road, Harbin, 150040, China.
Department of Neurology, The 2nd Affiliated Hospital of Harbin Medical University, No. 246 Xuefu Road, Harbin, 150086, China.
BMC Bioinformatics. 2020 Feb 5;21(1):43. doi: 10.1186/s12859-020-3388-y.
Various methods for differential expression analysis have been widely used to identify features which best distinguish between different categories of samples. Multiple hypothesis testing may leave out explanatory features, each of which may be composed of individually insignificant variables. Multivariate hypothesis testing holds a non-mainstream position, considering the large computation overhead of large-scale matrix operation. Random forest provides a classification strategy for calculation of variable importance. However, it may be unsuitable for different distributions of samples.
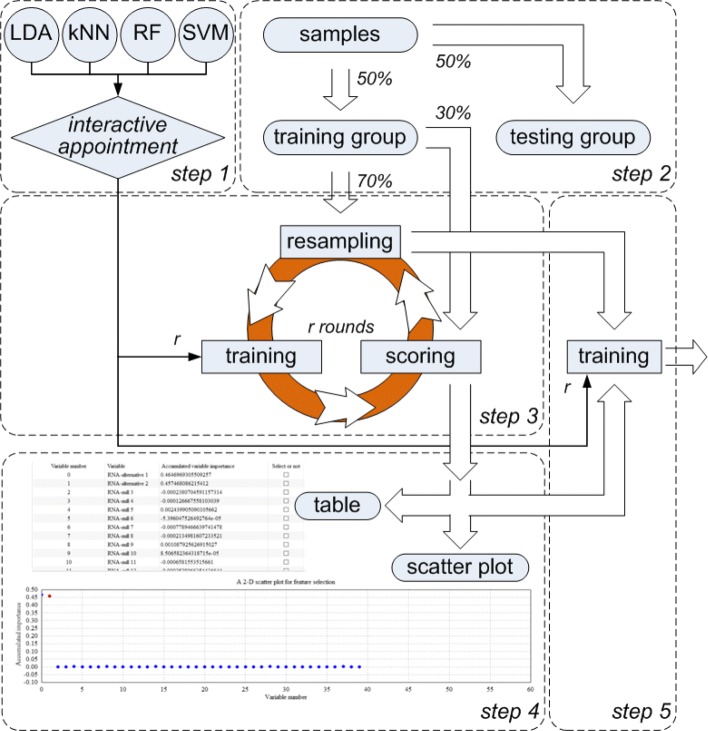
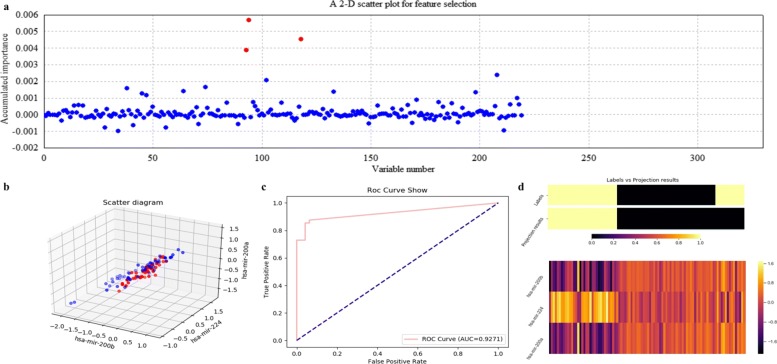
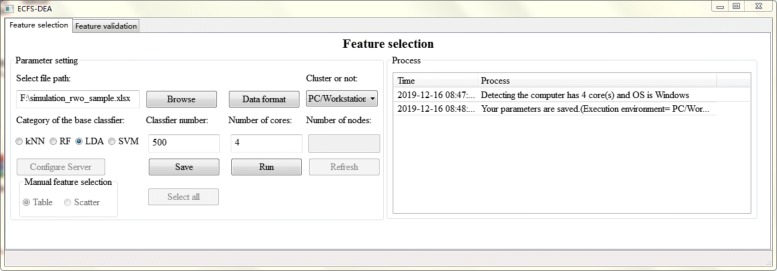
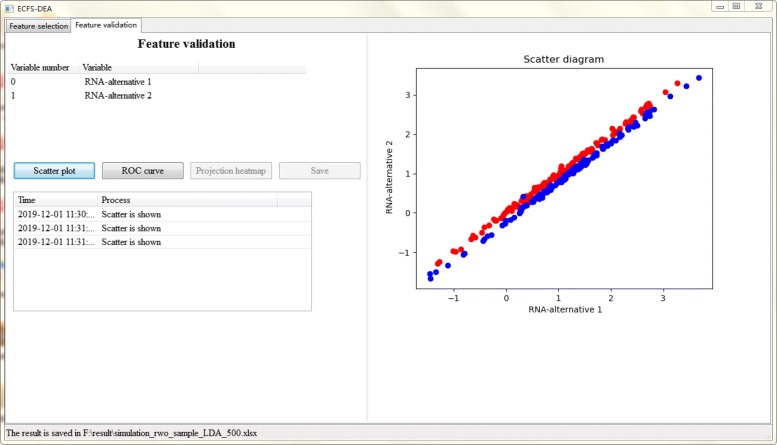
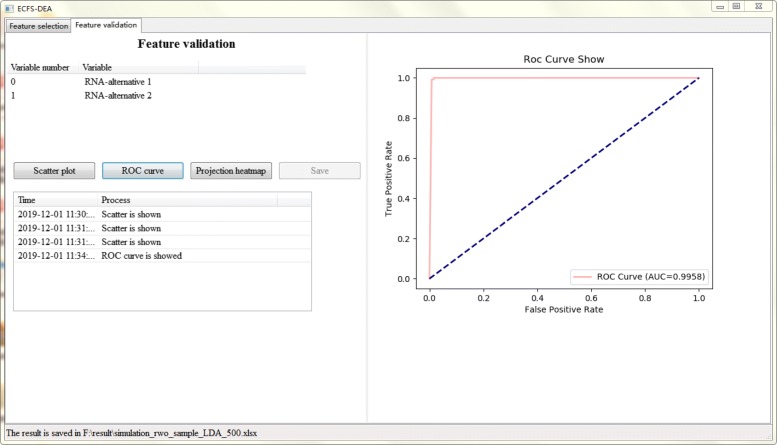
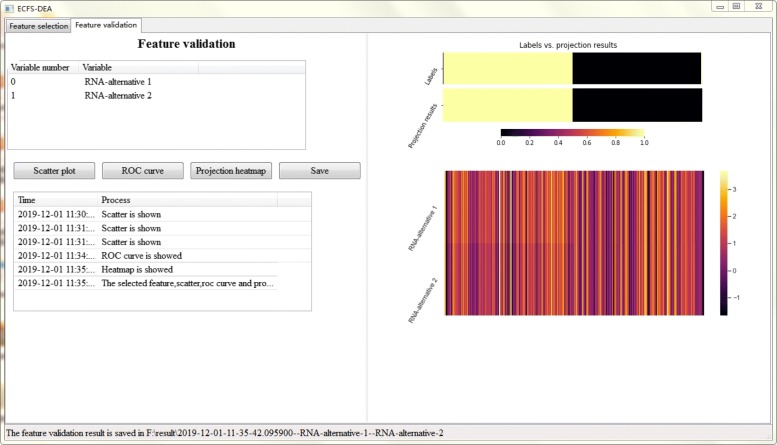
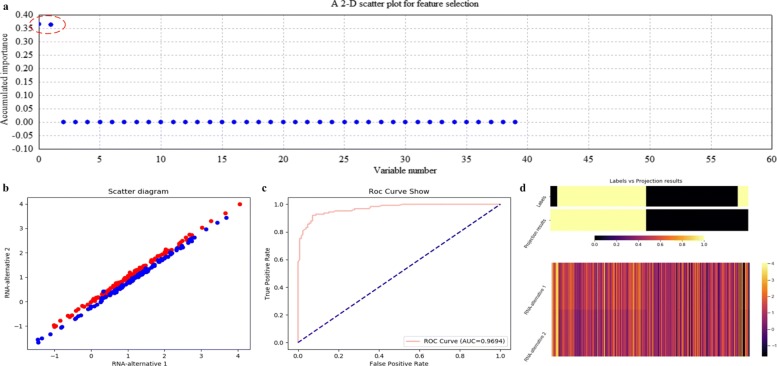
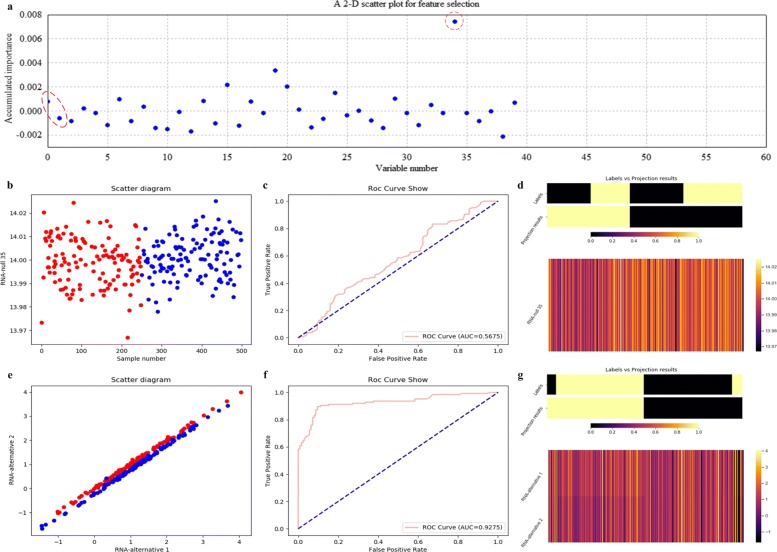
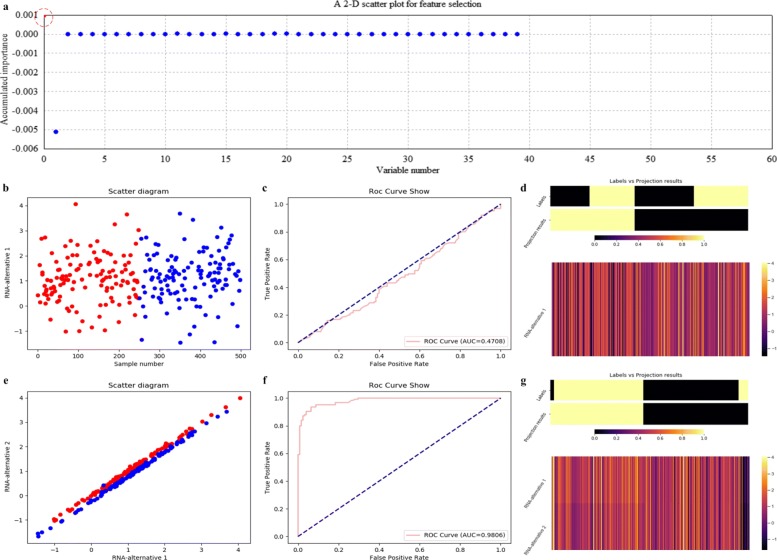
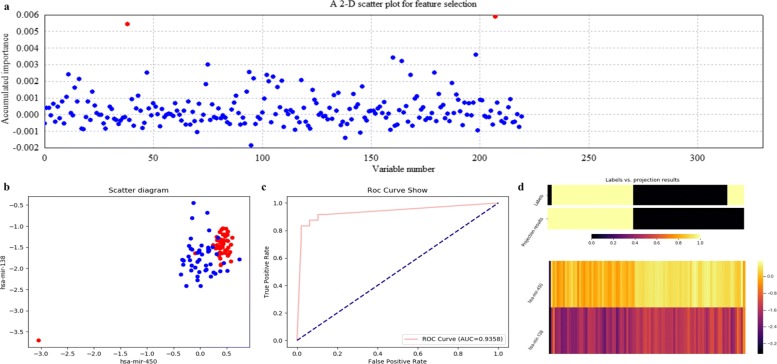
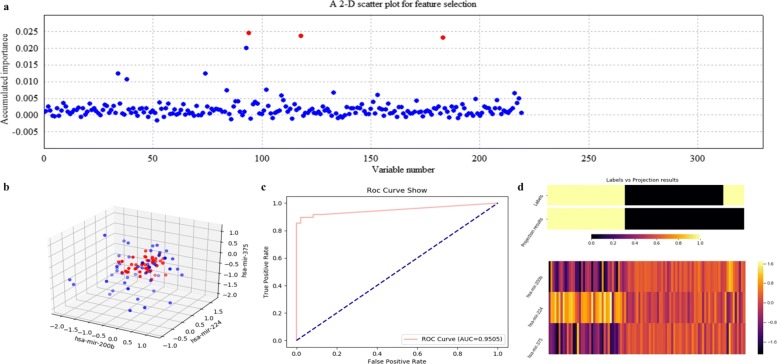
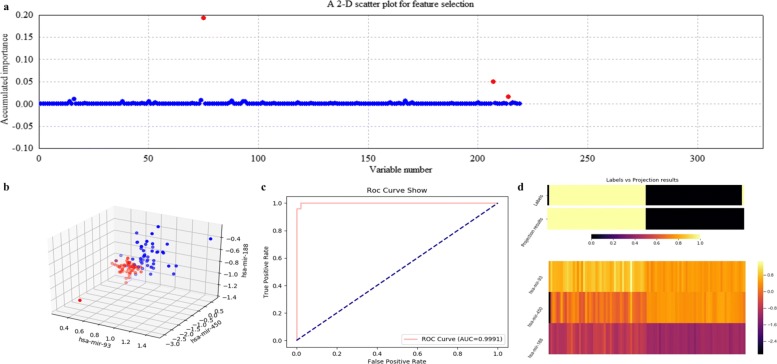
Based on the thought of using an ensemble classifier, we develop a feature selection tool for differential expression analysis on expression profiles (i.e., ECFS-DEA for short). Considering the differences in sample distribution, a graphical user interface is designed to allow the selection of different base classifiers. Inspired by random forest, a common measure which is applicable to any base classifier is proposed for calculation of variable importance. After an interactive selection of a feature on sorted individual variables, a projection heatmap is presented using k-means clustering. ROC curve is also provided, both of which can intuitively demonstrate the effectiveness of the selected feature.
Feature selection through ensemble classifiers helps to select important variables and thus is applicable for different sample distributions. Experiments on simulation and realistic data demonstrate the effectiveness of ECFS-DEA for differential expression analysis on expression profiles. The software is available at http://bio-nefu.com/resource/ecfs-dea.
为了识别能够最好地区分不同类别样本的特征,已经广泛使用了各种差异表达分析方法。多重假设检验可能会遗漏解释性特征,每个特征可能由单独的非显著变量组成。由于大规模矩阵运算的计算开销较大,因此多元假设检验的地位并不主流。随机森林提供了一种用于计算变量重要性的分类策略。然而,它可能不适用于不同分布的样本。
基于使用集成分类器的思想,我们开发了一种用于表达谱差异表达分析的特征选择工具(简称 ECFS-DEA)。考虑到样本分布的差异,设计了一个图形用户界面,允许选择不同的基础分类器。受随机森林的启发,提出了一种适用于任何基础分类器的通用度量标准,用于计算变量重要性。在对排序后的单个变量进行特征交互选择后,使用 k-均值聚类呈现投影热图。还提供了 ROC 曲线,两者都可以直观地展示所选特征的有效性。
通过集成分类器进行特征选择有助于选择重要变量,因此适用于不同的样本分布。对模拟和真实数据的实验表明,ECFS-DEA 对表达谱的差异表达分析是有效的。该软件可在 http://bio-nefu.com/resource/ecfs-dea 上获得。