Ling Albee Y, Kurian Allison W, Caswell-Jin Jennifer L, Sledge George W, Shah Nigam H, Tamang Suzanne R
Biomedical Informatics Training Program, Stanford University, Stanford, CA.
Department of Biomedical Data Science, Stanford University, Stanford, CA.
JAMIA Open. 2019 Sep 18;2(4):528-537. doi: 10.1093/jamiaopen/ooz040. eCollection 2019 Dec.
Most population-based cancer databases lack information on metastatic recurrence. Electronic medical records (EMR) and cancer registries contain complementary information on cancer diagnosis, treatment and outcome, yet are rarely used synergistically. To construct a cohort of metastatic breast cancer (MBC) patients, we applied natural language processing techniques within a semisupervised machine learning framework to linked EMR-California Cancer Registry (CCR) data.
We studied all female patients treated at Stanford Health Care with an incident breast cancer diagnosis from 2000 to 2014. Our database consisted of structured fields and unstructured free-text clinical notes from EMR, linked to CCR, a component of the Surveillance, Epidemiology and End Results Program (SEER). We identified MBC patients from CCR and extracted information on distant recurrences from patient notes in EMR. Furthermore, we trained a regularized logistic regression model for recurrent MBC classification and evaluated its performance on a gold standard set of 146 patients.
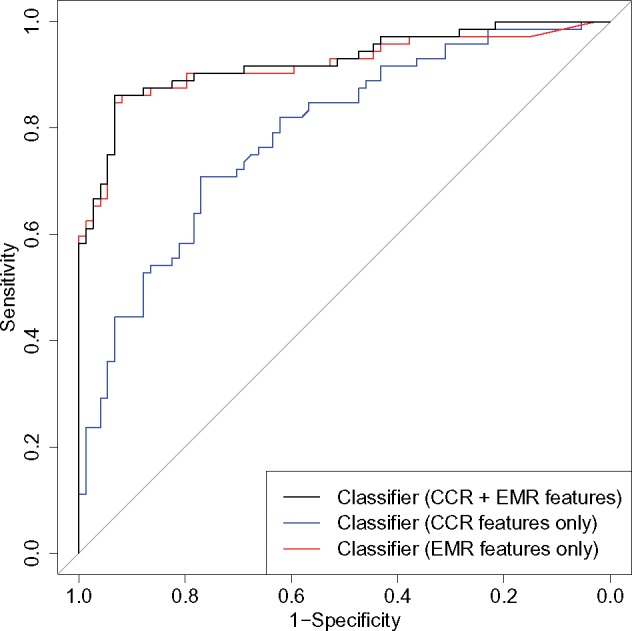
There were 11 459 breast cancer patients in total and the median follow-up time was 96.3 months. We identified 1886 MBC patients, 512 (27.1%) of whom were MBC patients and 1374 (72.9%) were recurrent MBC patients. Our final MBC classifier achieved an area under the receiver operating characteristic curve (AUC) of 0.917, with sensitivity 0.861, specificity 0.878, and accuracy 0.870.
To enable population-based research on MBC, we developed a framework for retrospective case detection combining EMR and CCR data. Our classifier achieved good AUC, sensitivity, and specificity without expert-labeled examples.
大多数基于人群的癌症数据库缺乏关于转移性复发的信息。电子病历(EMR)和癌症登记处包含有关癌症诊断、治疗和结果的补充信息,但很少协同使用。为了构建一个转移性乳腺癌(MBC)患者队列,我们在半监督机器学习框架内应用自然语言处理技术来链接EMR-加利福尼亚癌症登记处(CCR)数据。
我们研究了2000年至2014年在斯坦福医疗保健机构接受首次乳腺癌诊断治疗的所有女性患者。我们的数据库由EMR中的结构化字段和非结构化自由文本临床记录组成,并与CCR(监测、流行病学和最终结果计划(SEER)的一个组成部分)相链接。我们从CCR中识别出MBC患者,并从EMR中的患者记录中提取远处复发的信息。此外,我们训练了一个用于复发性MBC分类的正则化逻辑回归模型,并在一组146例患者的金标准数据集上评估其性能。
总共有11459例乳腺癌患者,中位随访时间为96.3个月。我们识别出1886例MBC患者,其中512例(27.1%)为初治MBC患者,1374例(72.9%)为复发性MBC患者。我们最终的MBC分类器在受试者工作特征曲线(AUC)下的面积为0.917,敏感性为0.861,特异性为0.878,准确性为0.870。
为了开展基于人群的MBC研究,我们开发了一个结合EMR和CCR数据的回顾性病例检测框架。我们的分类器在没有专家标记示例的情况下取得了良好的AUC、敏感性和特异性。