Luo Huoling, Hu Qingmao, Jia Fucang
Research Lab for Medical Imaging and Digital Surgery, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, People's Republic of China.
Shenzhen College of Advanced Technology, University of Chinese Academy of Sciences, Shenzhen, People's Republic of China.
Healthc Technol Lett. 2019 Nov 13;6(6):154-158. doi: 10.1049/htl.2019.0063. eCollection 2019 Dec.
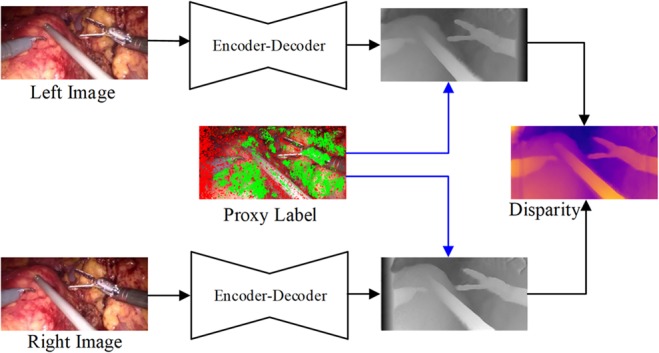
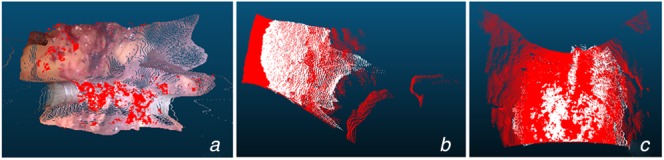
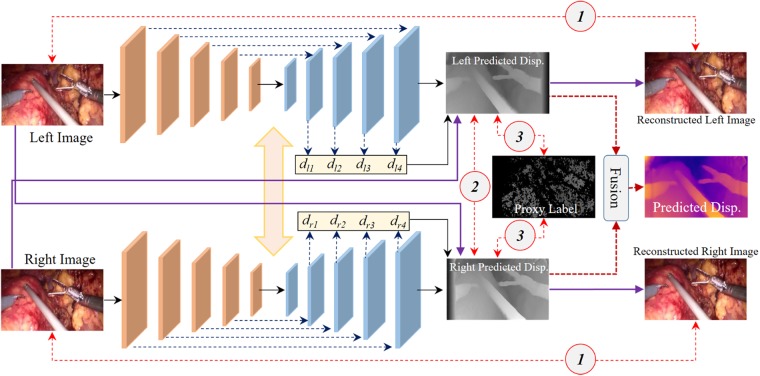
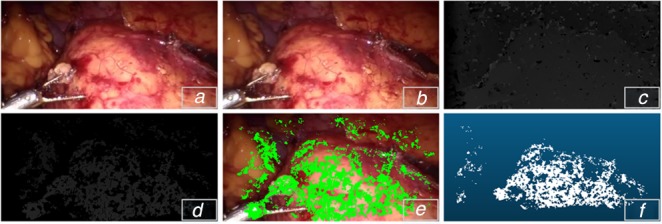
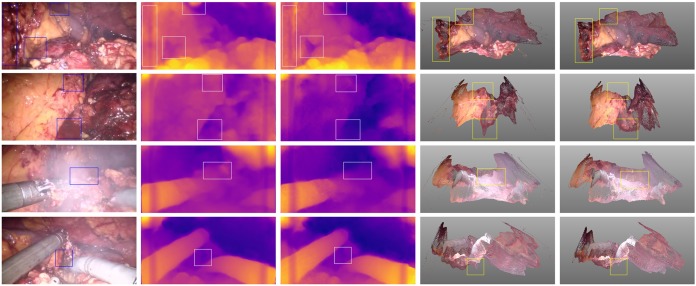
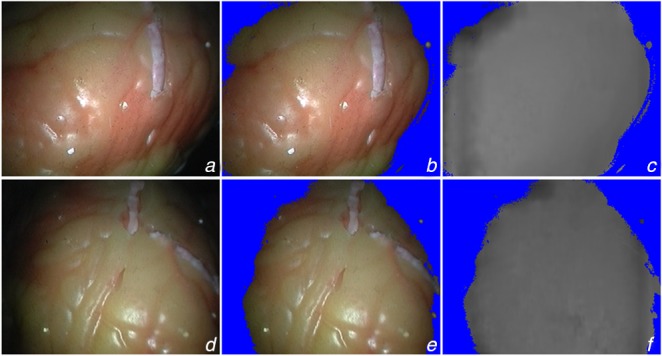
Depth estimation plays an important role in vision-based laparoscope surgical navigation systems. Most learning-based depth estimation methods require ground truth depth or disparity images for training; however, these data are difficult to obtain in laparoscopy. The authors present an unsupervised learning depth estimation approach by fusing traditional stereo knowledge. The traditional stereo method is used to generate proxy disparity labels, in which unreliable depth measurements are removed via a confidence measure to improve stereo accuracy. The disparity images are generated by training a dual encoder-decoder convolutional neural network from rectified stereo images coupled with proxy labels generated by the traditional stereo method. A principled mask is computed to exclude the pixels, which are not seen in one of views due to parallax effects from the calculation of loss function. Moreover, the neighbourhood smoothness term is employed to constrain neighbouring pixels with similar appearances to generate a smooth depth surface. This approach can make the depth of the projected point cloud closer to the real surgical site and preserve realistic details. The authors demonstrate the performance of the method by training and evaluation with a partial nephrectomy da Vinci surgery dataset and heart phantom data from the Hamlyn Centre.
深度估计在基于视觉的腹腔镜手术导航系统中起着重要作用。大多数基于学习的深度估计方法在训练时需要真实深度或视差图像;然而,这些数据在腹腔镜检查中很难获得。作者提出了一种通过融合传统立体视觉知识的无监督学习深度估计方法。传统立体视觉方法用于生成代理视差标签,其中通过置信度测量去除不可靠的深度测量值,以提高立体视觉精度。视差图像是通过从校正后的立体图像训练一个双编码器-解码器卷积神经网络生成的,该网络结合了传统立体视觉方法生成的代理标签。计算一个有原则的掩码,以排除由于视差效应在其中一个视图中不可见的像素,从而避免其参与损失函数的计算。此外,采用邻域平滑项来约束具有相似外观的相邻像素,以生成平滑的深度表面。这种方法可以使投影点云的深度更接近真实手术部位,并保留逼真的细节。作者通过使用部分肾切除术达芬奇手术数据集和哈姆林中心的心脏模型数据进行训练和评估,展示了该方法的性能。