Johns Hopkins University, Bloomberg School of Public Health, Center for Alternatives to Animal Testing (CAAT), Baltimore, MD, United States.
ToxTrack LLC, Baltimore, USA.
Sci Rep. 2020 Mar 5;10(1):4106. doi: 10.1038/s41598-020-60456-x.
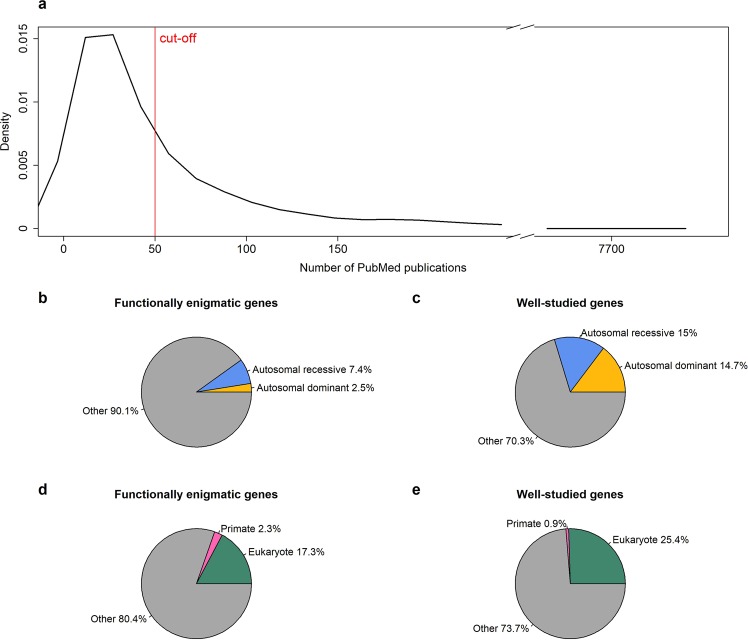
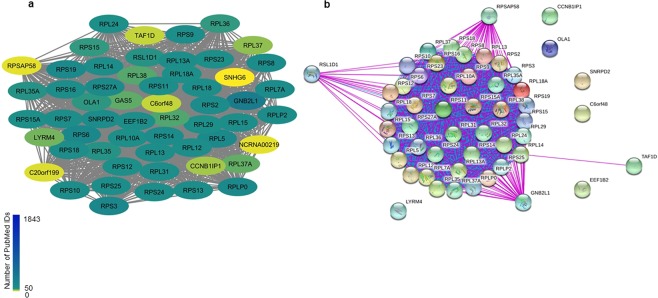
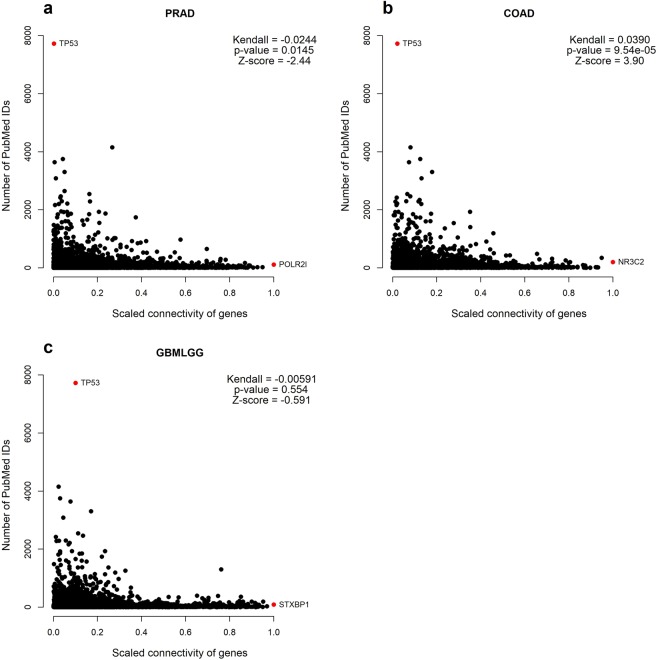
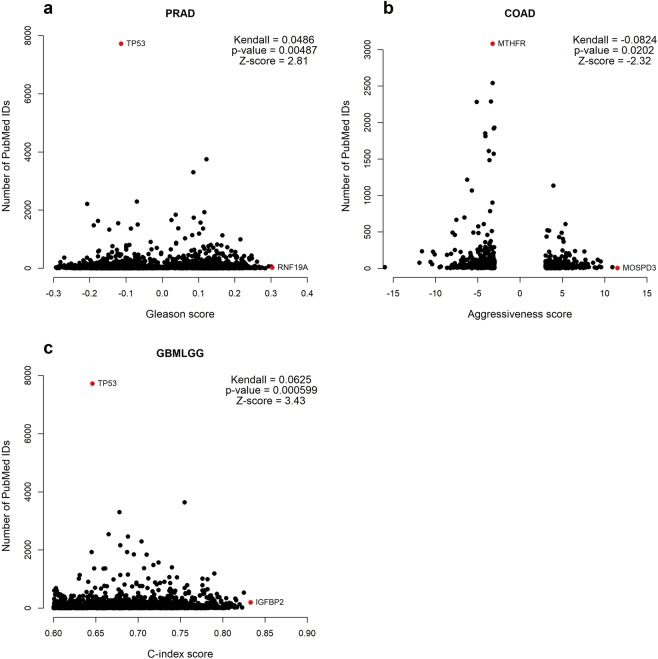
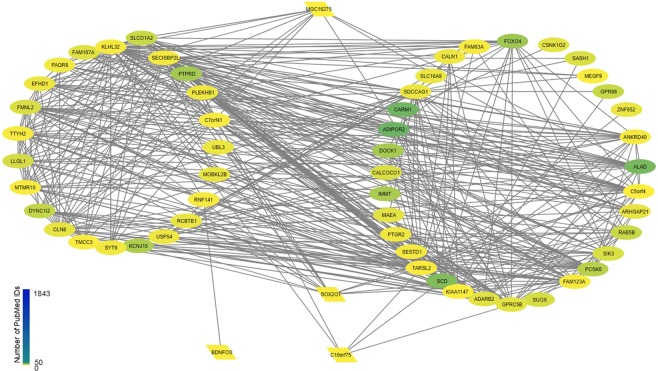
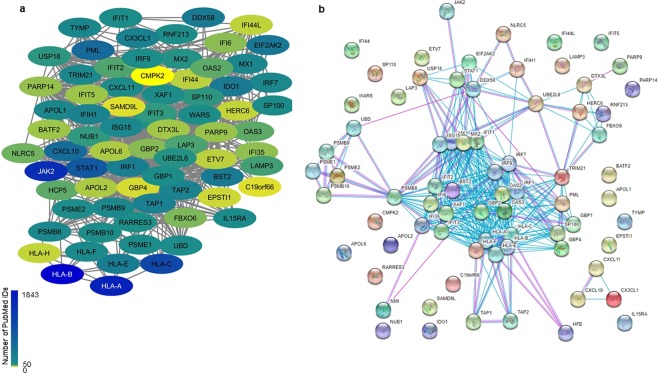
Cancer is a comparatively well-studied disease, yet despite decades of intense focus, we demonstrate here using data from The Cancer Genome Atlas that a substantial number of genes implicated in cancer are relatively poorly studied. Those genes will likely be missed by any data analysis pipeline, such as enrichment analysis, that depends exclusively on annotations for understanding biological function. There is no indication that the amount of research - indicated by number of publications - is correlated with any objective metric of gene significance. Moreover, these genes are not missing at random but reflect that our information about genes is gathered in a biased manner: poorly studied genes are more likely to be primate-specific and less likely to have a Mendelian inheritance pattern, and they tend to cluster in some biological processes and not others. While this likely reflects both technological limitations as well as the fact that well-known genes tend to gather more interest from the research community, in the absence of a concerted effort to study genes in an unbiased way, many genes (and biological processes) will remain opaque.
癌症是一种研究得比较透彻的疾病,但尽管我们已经进行了数十年的深入研究,在这里,我们利用癌症基因组图谱的数据表明,大量与癌症相关的基因仍未得到充分研究。这些基因很可能会被任何完全依赖注释来理解生物功能的数据分析管道(如富集分析)所遗漏。没有迹象表明研究的数量(以出版物数量为指标)与基因重要性的任何客观指标相关。此外,这些基因并不是随机缺失的,而是反映了我们获取基因信息的方式存在偏差:研究较少的基因更有可能是灵长类动物所特有的,并且不太可能具有孟德尔遗传模式,而且它们往往在某些生物过程中聚集,而在其他过程中则不聚集。虽然这可能反映了技术限制以及众所周知的基因往往会从研究界获得更多关注的事实,但如果没有一致的努力以无偏倚的方式研究基因,许多基因(和生物过程)将仍然不为人知。