Wood Ryan L, Jensen Tanner, Wadsworth Cindi, Clement Mark, Nagpal Prashant, Pitt William G
Chemical Engineering, Brigham Young University, Provo, UT, United States.
Computer Science, Brigham Young University, Provo, UT, United States.
Front Microbiol. 2020 Feb 20;11:257. doi: 10.3389/fmicb.2020.00257. eCollection 2020.
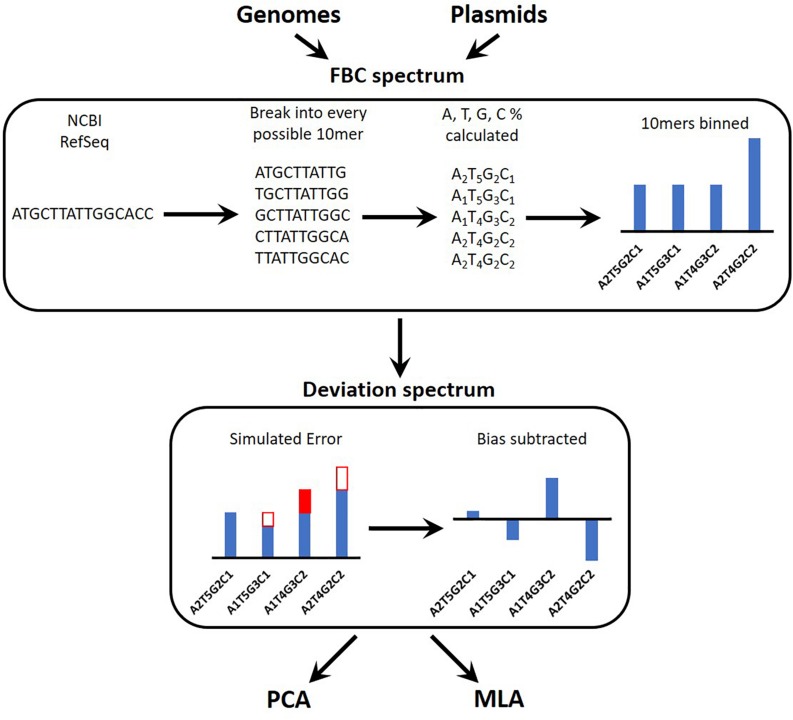
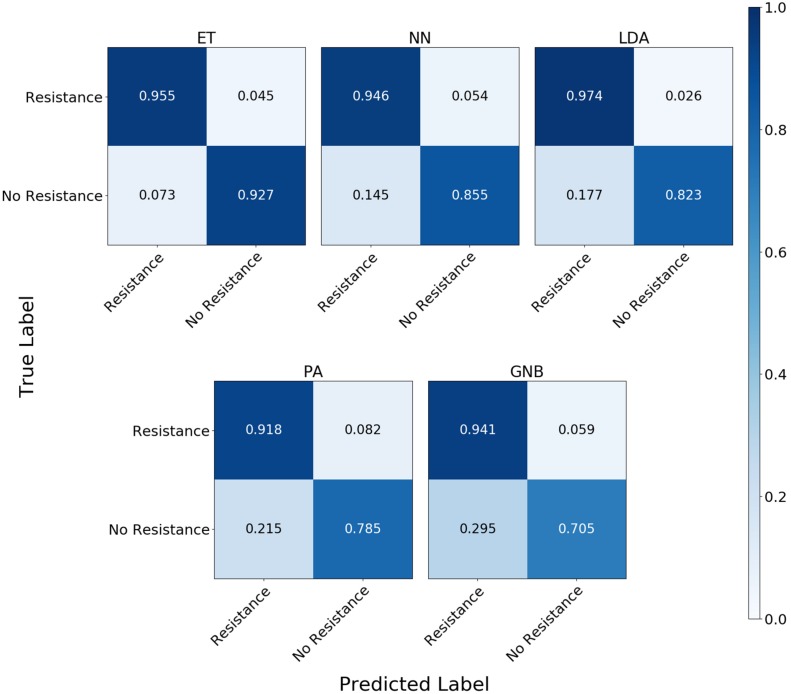
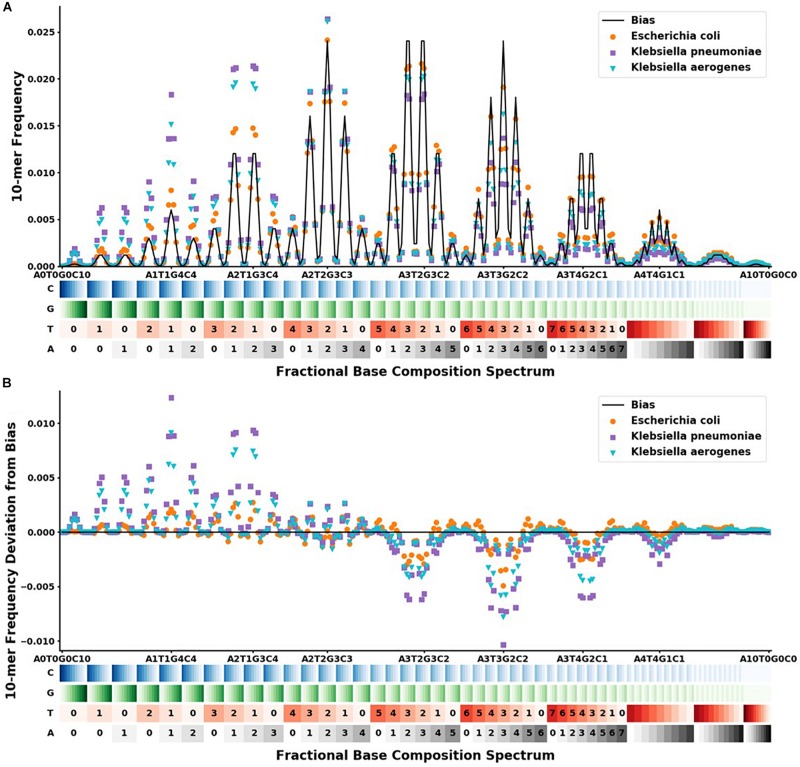
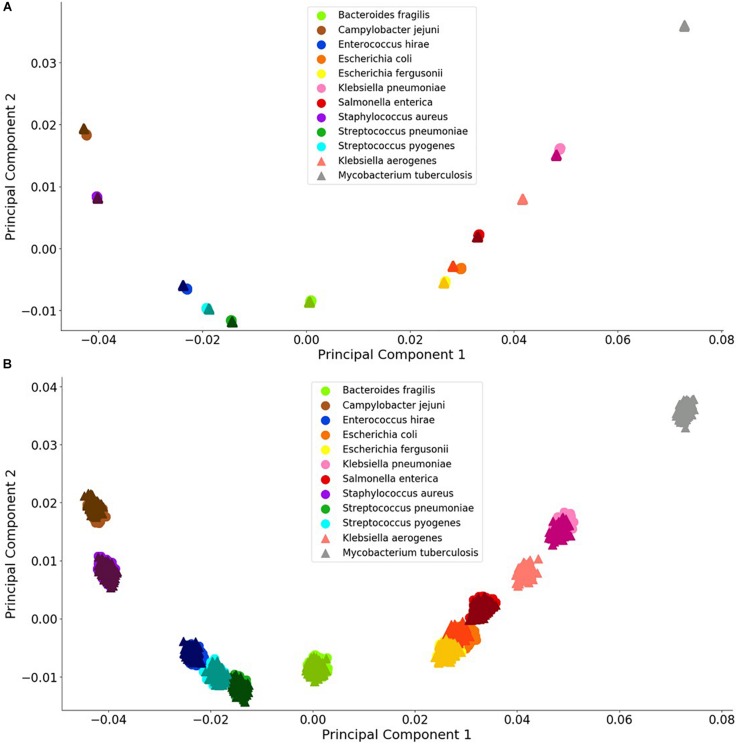
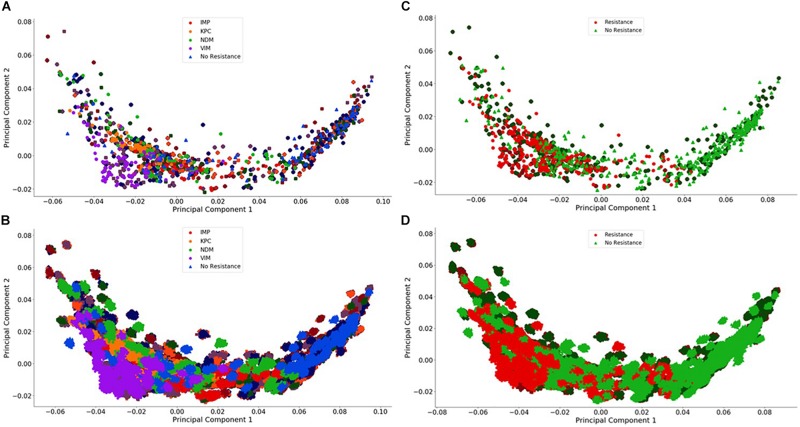
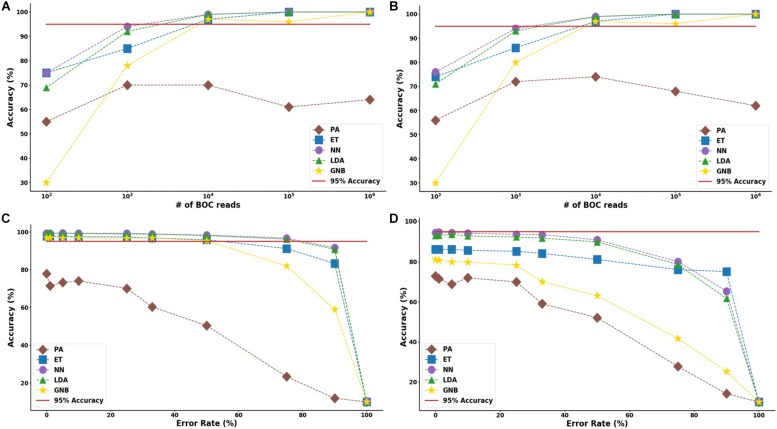
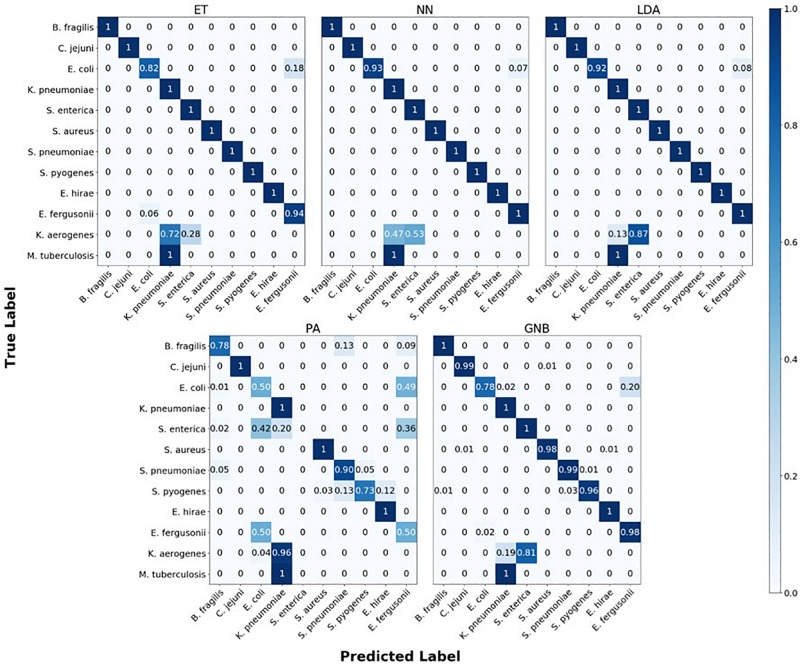
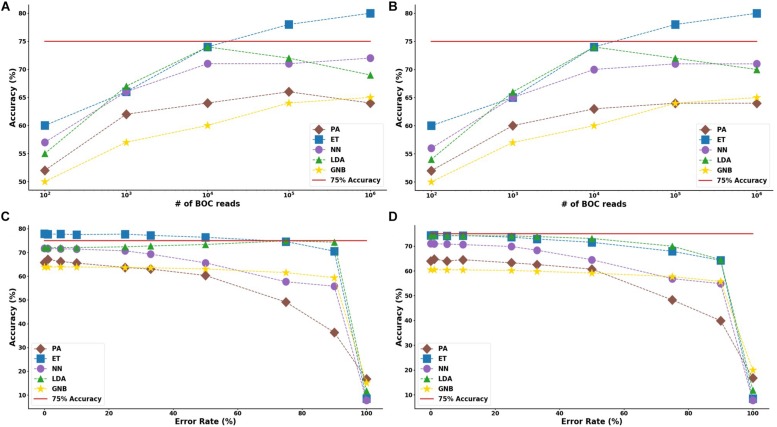
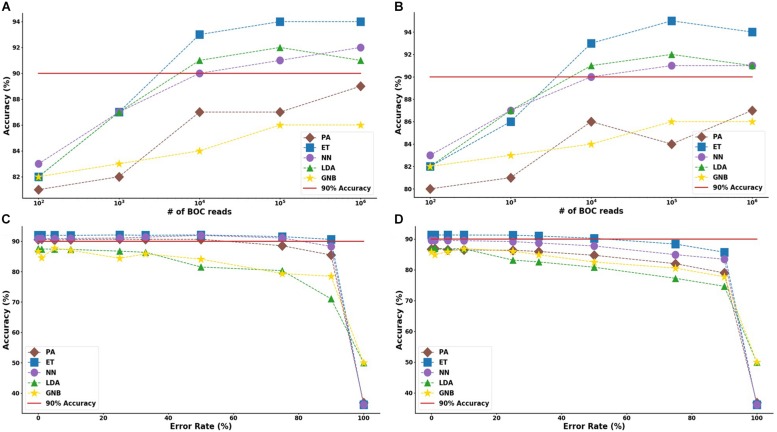
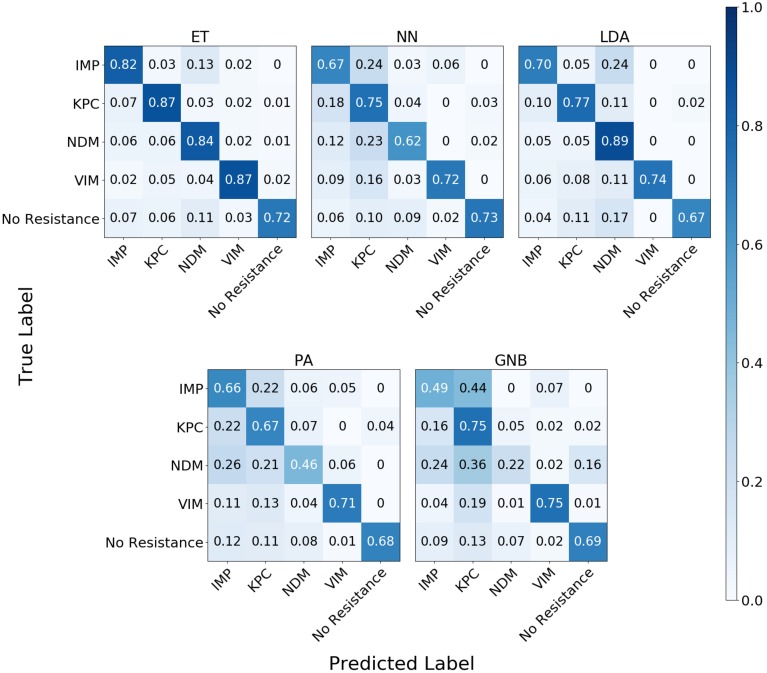
Bacterial antibiotic resistance is becoming a significant health threat, and rapid identification of antibiotic-resistant bacteria is essential to save lives and reduce the spread of antibiotic resistance. This paper analyzes the ability of machine learning algorithms (MLAs) to process data from a novel spectroscopic diagnostic device to identify antibiotic-resistant genes and bacterial species by comparison to available bacterial DNA sequences. Simulation results show that the algorithms attain from 92% accuracy (for genes) up to 99% accuracy (for species). This novel approach identifies genes and species by optically reading the percentage of A, C, G, T bases in 1000s of short 10-base DNA oligomers instead of relying on conventional DNA sequencing in which the sequence of bases in long oligomers provides genetic information. The identification algorithms are robust in the presence of simulated random genetic mutations and simulated random experimental errors. Thus, these algorithms can be used to identify bacterial species, to reveal antibiotic resistance genes, and to perform other genomic analyses. Some MLAs evaluated here are shown to be better than others at accurate gene identification and avoidance of false negative identification of antibiotic resistance.
细菌对抗生素的耐药性正成为一个重大的健康威胁,快速识别耐药细菌对于拯救生命和减少抗生素耐药性的传播至关重要。本文分析了机器学习算法(MLA)处理来自新型光谱诊断设备的数据的能力,通过与可用的细菌DNA序列进行比较来识别抗生素耐药基因和细菌种类。模拟结果表明,这些算法的准确率从92%(针对基因)到99%(针对种类)不等。这种新颖的方法通过光学读取数千个10碱基短DNA寡聚物中A、C、G、T碱基的百分比来识别基因和种类,而不是依赖于传统的DNA测序,在传统测序中,长寡聚物中的碱基序列提供遗传信息。识别算法在存在模拟随机基因突变和模拟随机实验误差的情况下具有鲁棒性。因此,这些算法可用于识别细菌种类、揭示抗生素耐药基因以及进行其他基因组分析。本文评估的一些机器学习算法在准确的基因识别和避免抗生素耐药性的假阴性识别方面表现优于其他算法。