Aziz Firdaus, Malek Sorayya, Mhd Ali Adliah, Wong Mee Sieng, Mosleh Mogeeb, Milow Pozi
Bioinformatics Science Programme, Institute of Biological Sciences, University of Malaya, Kuala Lumpur, Malaysia.
Quality Use of Medicines Research Group, Faculty of Pharmacy, Universiti Kebangsaan Malaysia, Kuala Lumpur, Malaysia.
PeerJ. 2020 Mar 13;8:e8286. doi: 10.7717/peerj.8286. eCollection 2020.
This study assesses the feasibility of using machine learning methods such as Random Forests (RF), Artificial Neural Networks (ANN), Support Vector Regression (SVR) and Self-Organizing Feature Maps (SOM) to identify and determine factors associated with hypertensive patients' adherence levels. Hypertension is the medical term for systolic and diastolic blood pressure higher than 140/90 mmHg. A conventional medication adherence scale was used to identify patients' adherence to their prescribed medication. Using machine learning applications to predict precise numeric adherence scores in hypertensive patients has not yet been reported in the literature.
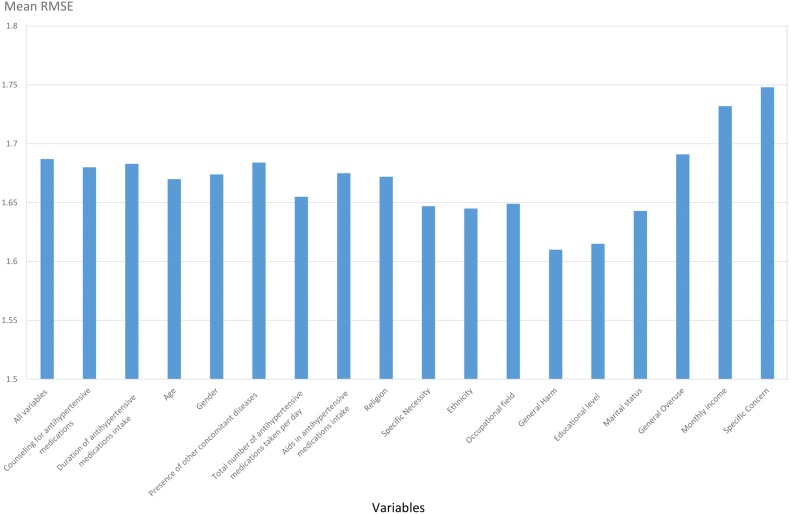
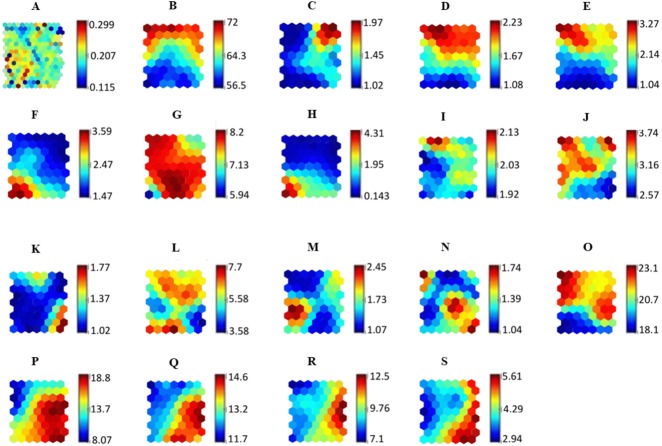
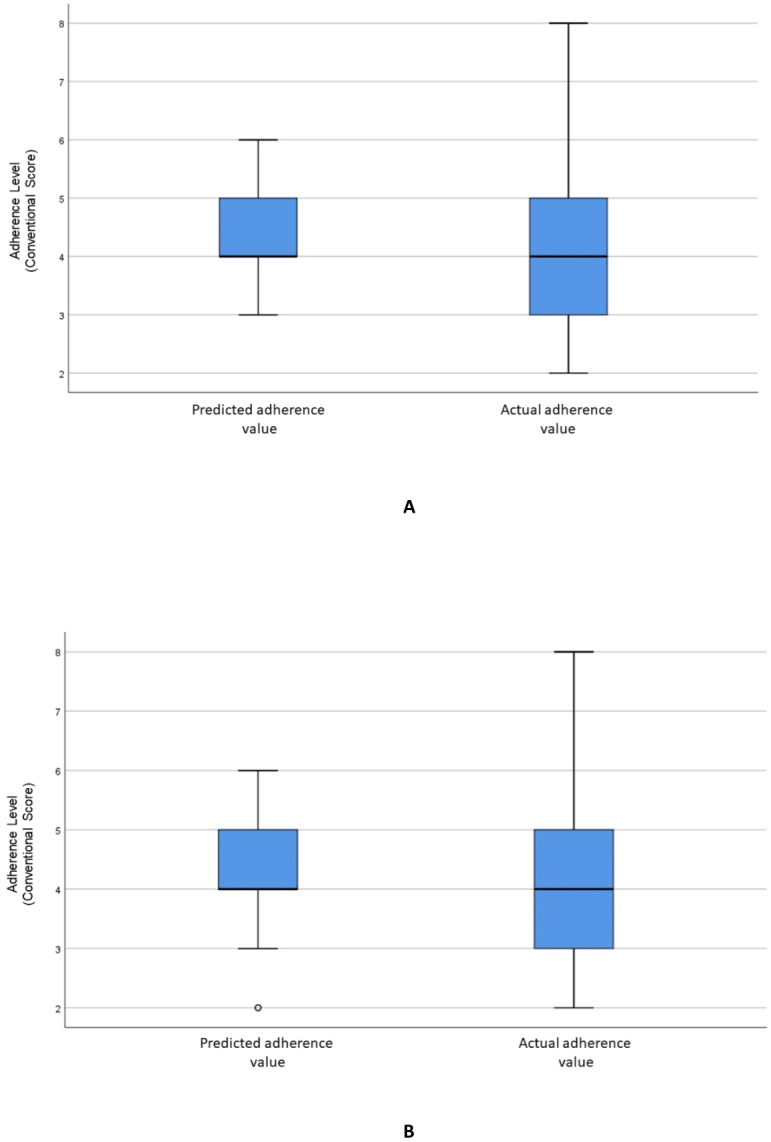
Data from 160 hypertensive patients from a tertiary hospital in Kuala Lumpur, Malaysia, were used in this study. Variables were ranked based on their significance to adherence levels using the RF variable importance method. The backward elimination method was then performed using RF to obtain the variables significantly associated with the patients' adherence levels. RF, SVR and ANN models were developed to predict adherence using the identified significant variables. Visualizations of the relationships between hypertensive patients' adherence levels and variables were generated using SOM.
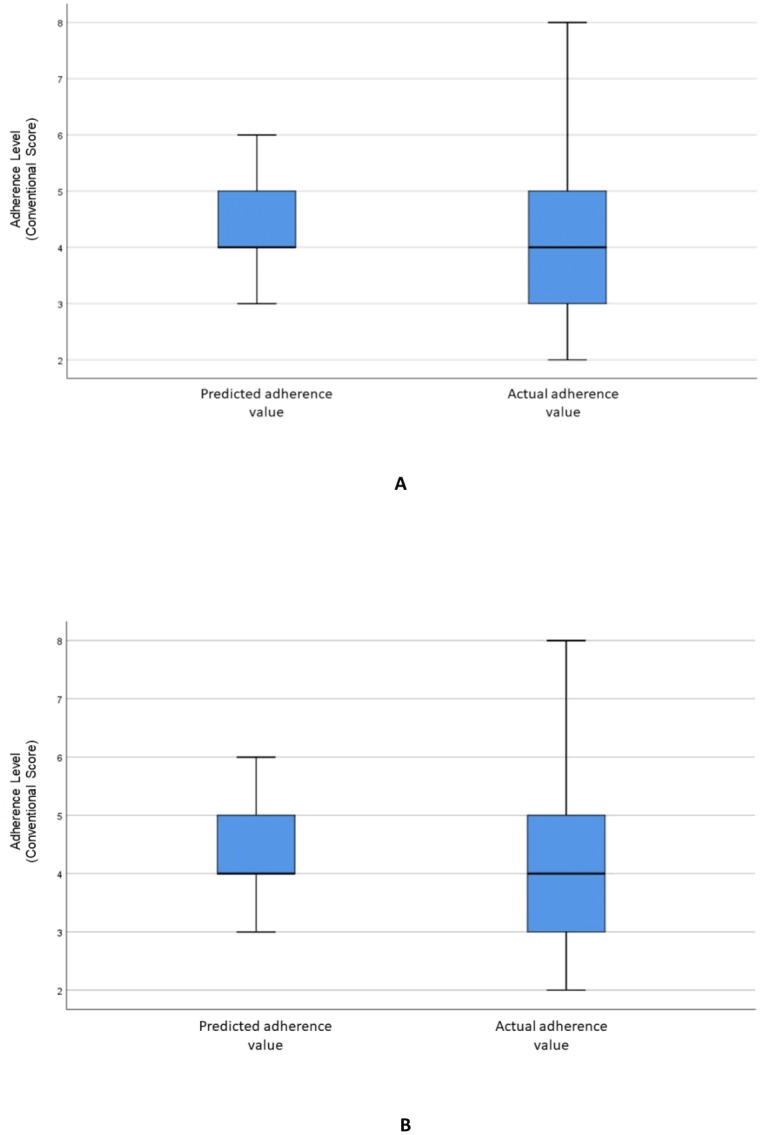
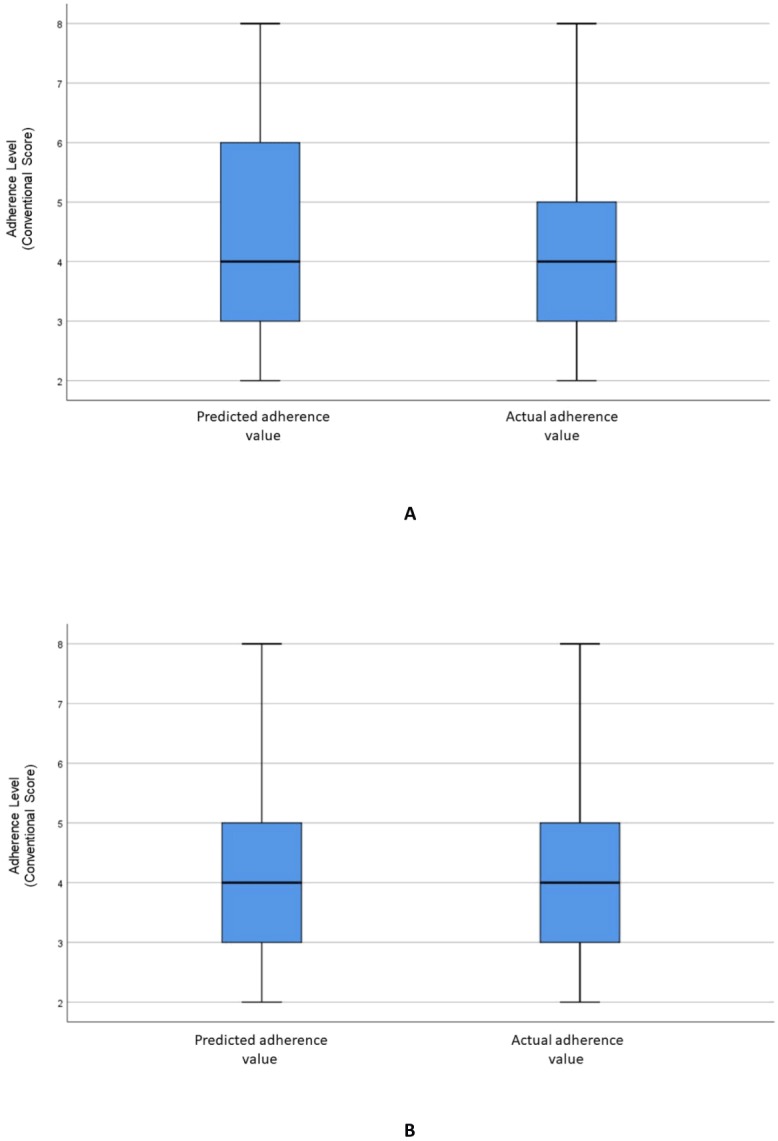
Machine learning models constructed using the selected variables reported RMSE values of 1.42 for ANN, 1.53 for RF, and 1.55 for SVR. The accuracy of the dichotomised scores, calculated based on a percentage of correctly identified adherence values, was used as an additional model performance measure, resulting in accuracies of 65% (ANN), 78% (RF) and 79% (SVR), respectively. The Wilcoxon signed ranked test reported that there was no significant difference between the predictions of the machine learning models and the actual scores. The significant variables identified from the RF variable importance method were educational level, marital status, General Overuse, monthly income, and Specific Concern.
This study suggests an effective alternative to conventional methods in identifying the key variables to understand hypertensive patients' adherence levels. This can be used as a tool to educate patients on the importance of medication in managing hypertension.
本研究评估使用随机森林(RF)、人工神经网络(ANN)、支持向量回归(SVR)和自组织特征映射(SOM)等机器学习方法来识别和确定与高血压患者依从性水平相关因素的可行性。高血压是指收缩压和舒张压高于140/90 mmHg的医学术语。使用传统的药物依从性量表来确定患者对其处方药物的依从性。在高血压患者中使用机器学习应用来预测精确的数值依从性得分在文献中尚未见报道。
本研究使用了来自马来西亚吉隆坡一家三级医院的160名高血压患者的数据。使用RF变量重要性方法根据变量对依从性水平的重要性进行排序。然后使用RF进行向后消除法以获得与患者依从性水平显著相关的变量。使用识别出的显著变量开发RF、SVR和ANN模型来预测依从性。使用SOM生成高血压患者依从性水平与变量之间关系的可视化。
使用所选变量构建的机器学习模型报告的RMSE值,ANN为1.42,RF为1.53,SVR为1.55。基于正确识别的依从性值的百分比计算的二分得分的准确性用作额外的模型性能指标,结果准确率分别为65%(ANN)、78%(RF)和79%(SVR)。Wilcoxon符号秩检验报告机器学习模型的预测与实际得分之间没有显著差异。从RF变量重要性方法中识别出的显著变量为教育水平、婚姻状况、一般过度使用、月收入和特定关注。
本研究表明在识别理解高血压患者依从性水平的关键变量方面,是传统方法的一种有效替代方法。这可作为一种工具,用于教育患者药物治疗对控制高血压的重要性。