Jin Huan, Moseley Hunter N B
Department of Toxicology and Cancer Biology, University of Kentucky, Lexington, KY 40536, USA.
Department of Molecular & Cellular Biochemistry, University of Kentucky, Lexington, KY 40536, USA.
Metabolites. 2020 Mar 21;10(3):118. doi: 10.3390/metabo10030118.
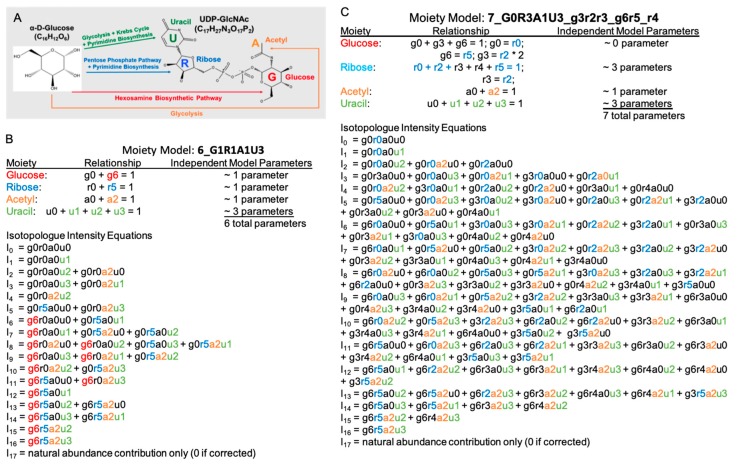
Stable isotope resolved metabolomics (SIRM) experiments use stable isotope tracers to provide superior metabolomics datasets for metabolic flux analysis and metabolic modeling. Since assumptions of model correctness can seriously compromise interpretation of metabolic flux results, we have developed a metabolic modeling software package specifically designed for moiety model comparison and selection based on the metabolomics data provided. Here, we tested the effectiveness of model selection with two time-series mass spectrometry (MS) isotopologue datasets for uridine diphosphate N-acetyl-d-glucosamine (UDP-GlcNAc) generated from different platforms utilizing direct infusion nanoelectrospray and liquid chromatography. Analysis results demonstrate the robustness of our model selection methods by the successful selection of the optimal model from over 40 models provided. Moreover, the effects of specific optimization methods, degree of optimization, selection criteria, and specific objective functions on model selection are illustrated. Overall, these results indicate that over-optimization can lead to model selection failure, but combining multiple datasets can help control this overfitting effect. The implication is that SIRM datasets in public repositories of reasonable quality can be combined with newly acquired datasets to improve model selection. Furthermore, curation efforts of public metabolomics repositories to maintain high data quality could have a huge impact on future metabolic modeling efforts.
稳定同位素分辨代谢组学(SIRM)实验使用稳定同位素示踪剂来提供用于代谢通量分析和代谢建模的优质代谢组学数据集。由于模型正确性的假设可能会严重影响对代谢通量结果的解释,我们开发了一个代谢建模软件包,专门用于根据所提供的代谢组学数据进行部分模型比较和选择。在此,我们利用直接进样纳喷电喷雾和液相色谱等不同平台生成的两个尿苷二磷酸N - 乙酰 - d - 葡萄糖胺(UDP - GlcNAc)的时间序列质谱(MS)同位素异构体数据集,测试了模型选择的有效性。分析结果表明,通过从提供的40多个模型中成功选择最优模型,我们的模型选择方法具有稳健性。此外,还说明了特定优化方法、优化程度、选择标准和特定目标函数对模型选择的影响。总体而言,这些结果表明过度优化可能导致模型选择失败,但组合多个数据集有助于控制这种过拟合效应。这意味着可以将质量合理的公共存储库中的SIRM数据集与新获取的数据集相结合,以改善模型选择。此外,公共代谢组学存储库为保持高数据质量所做的整理工作可能会对未来的代谢建模工作产生巨大影响。