Fernandes Jason D, Zamudio-Hurtado Armando, Clawson Hiram, Kent W James, Haussler David, Salama Sofie R, Haeussler Maximilian
1Genomics Institute, University of California, Santa Cruz, USA.
2Department of Biomolecular Engineering, University of California, Santa Cruz, USA.
Mob DNA. 2020 Mar 31;11:13. doi: 10.1186/s13100-020-00208-w. eCollection 2020.
Nearly half the human genome consists of repeat elements, most of which are retrotransposons, and many of which play important biological roles. However repeat elements pose several unique challenges to current bioinformatic analyses and visualization tools, as short repeat sequences can map to multiple genomic loci resulting in their misclassification and misinterpretation. In fact, sequence data mapping to repeat elements are often discarded from analysis pipelines. Therefore, there is a continued need for standardized tools and techniques to interpret genomic data of repeats.
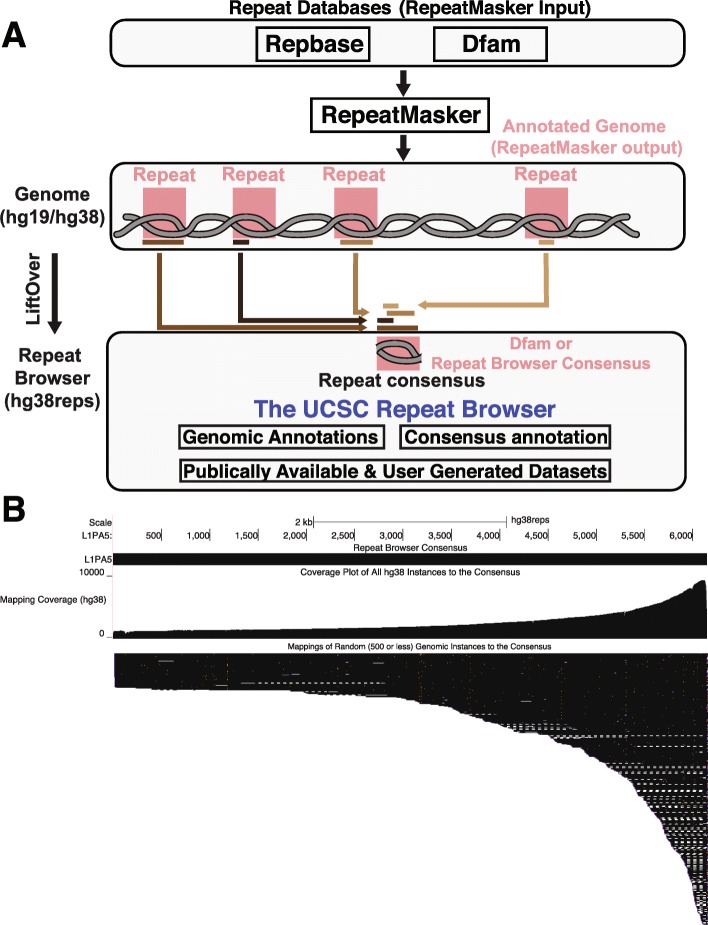
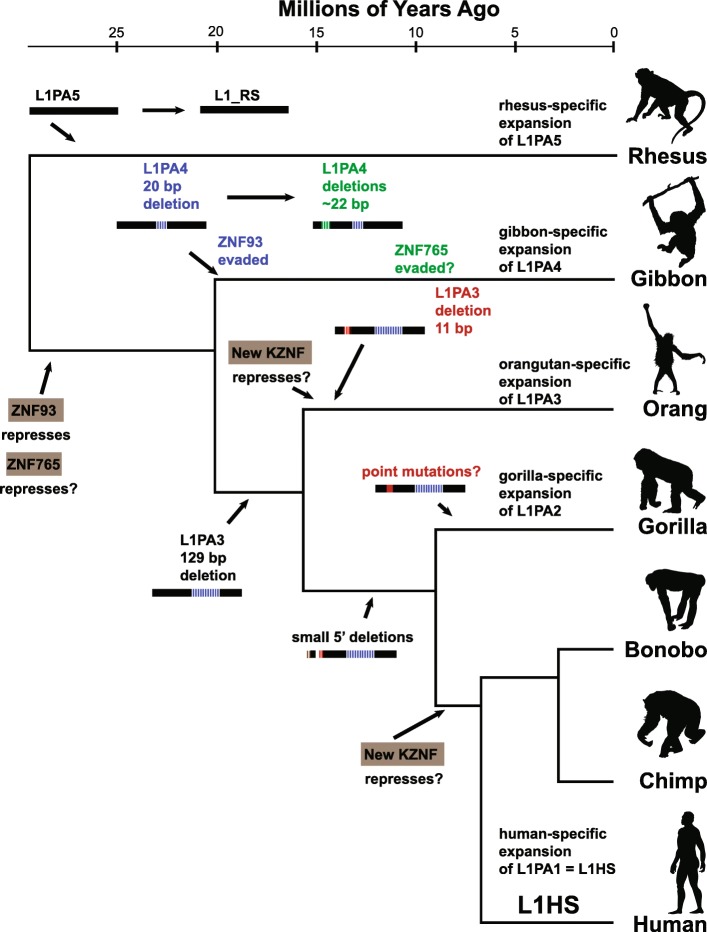
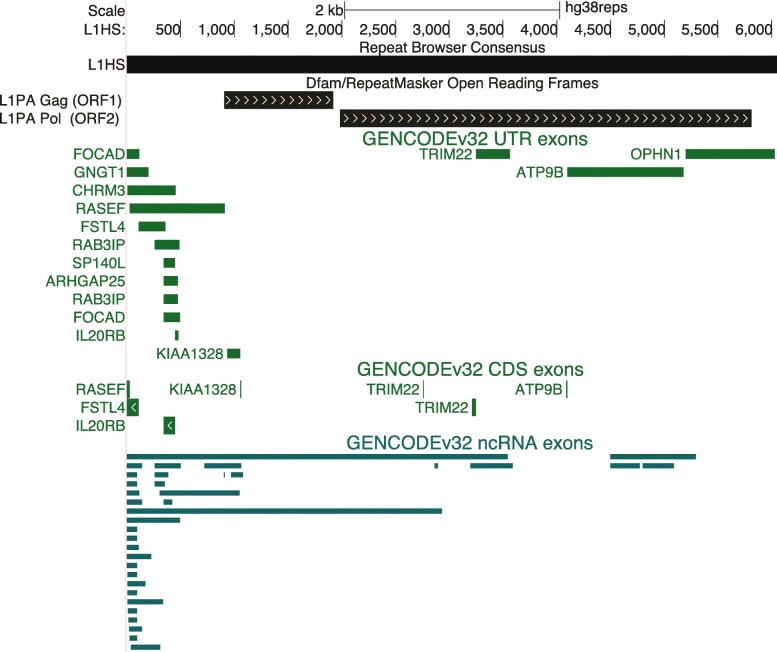
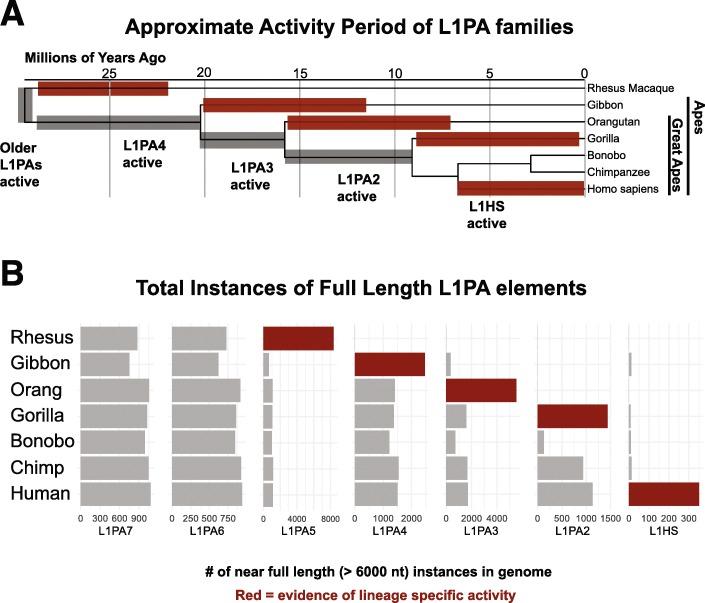
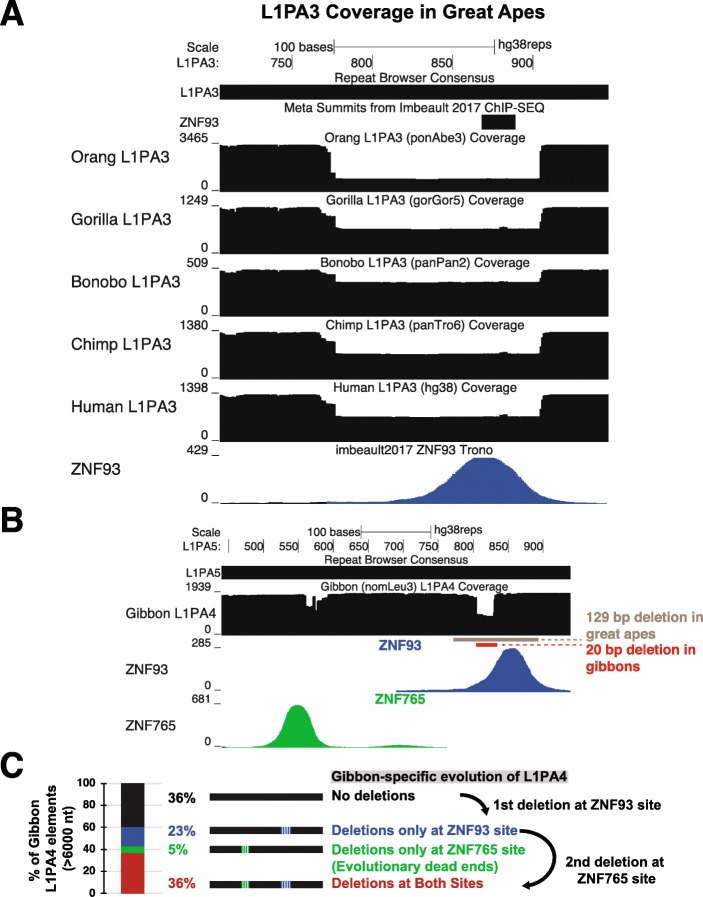
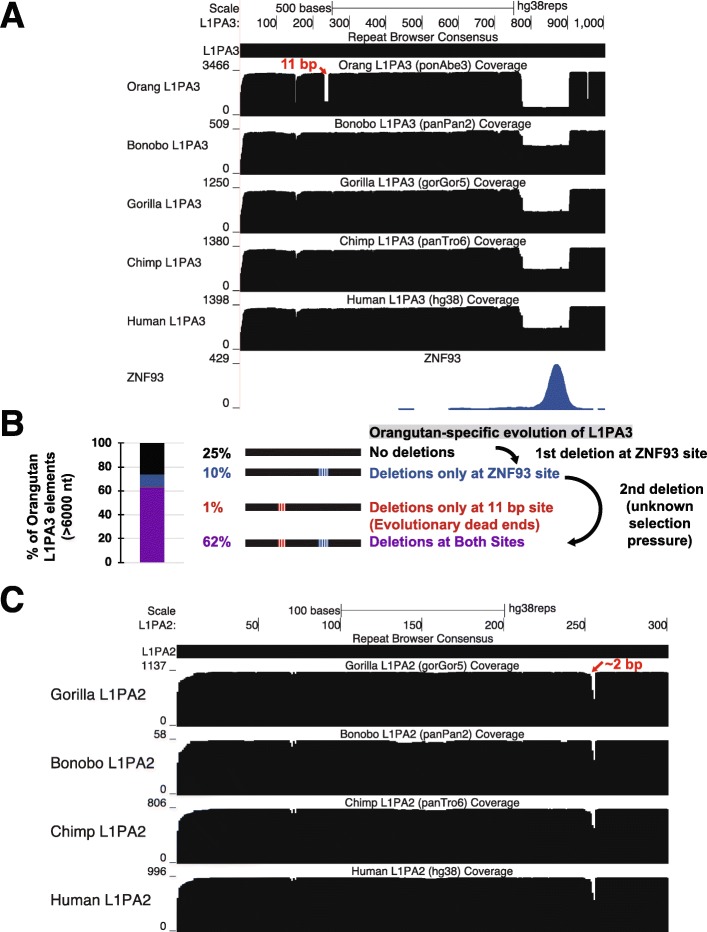
We present the UCSC Repeat Browser, which consists of a complete set of human repeat reference sequences derived from annotations made by the commonly used program RepeatMasker. The UCSC Repeat Browser also provides an alignment from the human genome to these references, uses it to map the standard human genome annotation tracks, and presents all of them as a comprehensive interface to facilitate work with repetitive elements. It also provides processed tracks of multiple publicly available datasets of particular interest to the repeat community, including ChIP-seq datasets for KRAB Zinc Finger Proteins (KZNFs) - a family of proteins known to bind and repress certain classes of repeats. We used the UCSC Repeat Browser in combination with these datasets, as well as RepeatMasker annotations in several non-human primates, to trace the independent trajectories of species-specific evolutionary battles between LINE 1 retroelements and their repressors. Furthermore, we document at https://repeatbrowser.ucsc.edu how researchers can map their own human genome annotations to these reference repeat sequences.
The UCSC Repeat Browser allows easy and intuitive visualization of genomic data on consensus repeat elements, circumventing the problem of multi-mapping, in which sequencing reads of repeat elements map to multiple locations on the human genome. By developing a reference consensus, multiple datasets and annotation tracks can easily be overlaid to reveal complex evolutionary histories of repeats in a single interactive window. Specifically, we use this approach to retrace the history of several primate specific LINE-1 families across apes, and discover several species-specific routes of evolution that correlate with the emergence and binding of KZNFs.
近一半的人类基因组由重复元件组成,其中大部分是逆转录转座子,许多重复元件发挥着重要的生物学作用。然而,重复元件给当前的生物信息分析和可视化工具带来了几个独特的挑战,因为短重复序列可以映射到多个基因组位点,导致它们被错误分类和错误解读。事实上,映射到重复元件的序列数据在分析流程中常常被丢弃。因此,持续需要标准化的工具和技术来解读重复序列的基因组数据。
我们展示了加州大学圣克鲁兹分校重复序列浏览器(UCSC Repeat Browser),它由一组完整的人类重复序列参考序列组成,这些序列源自常用程序RepeatMasker所做的注释。UCSC重复序列浏览器还提供了从人类基因组到这些参考序列的比对,利用它来映射标准的人类基因组注释轨道,并将所有这些作为一个综合界面呈现出来,以便于处理重复元件。它还提供了重复序列研究群体特别感兴趣的多个公开可用数据集的处理轨道,包括KRAB锌指蛋白(KZNFs)的染色质免疫沉淀测序(ChIP-seq)数据集——这是一类已知能结合并抑制某些重复序列类别的蛋白质家族。我们将UCSC重复序列浏览器与这些数据集以及几种非人类灵长类动物中的RepeatMasker注释结合使用,以追踪LINE 1逆转录元件与其抑制因子之间物种特异性进化斗争的独立轨迹。此外,我们在https://repeatbrowser.ucsc.edu上记录了研究人员如何将他们自己的人类基因组注释映射到这些参考重复序列上。
UCSC重复序列浏览器允许轻松直观地可视化共有重复元件上的基因组数据,规避了多重映射问题,即重复元件的测序读数映射到人类基因组上的多个位置的问题。通过开发一个参考共有序列,可以轻松叠加多个数据集和注释轨道,在单个交互式窗口中揭示重复序列复杂的进化历史。具体来说,我们使用这种方法追溯了几种灵长类特异性LINE-1家族在猿类中的历史,并发现了几条与KZNFs的出现和结合相关的物种特异性进化途径。