Prakapenka Dzianis, Wang Chunkao, Liang Zuoxiang, Bian Cheng, Tan Cheng, Da Yang
Department of Animal Science, University of Minnesota, Saint Paul, MN, United States.
State Key Laboratory for Agrobiotechnology, China Agricultural University, Beijing, China.
Front Genet. 2020 Apr 7;11:282. doi: 10.3389/fgene.2020.00282. eCollection 2020.
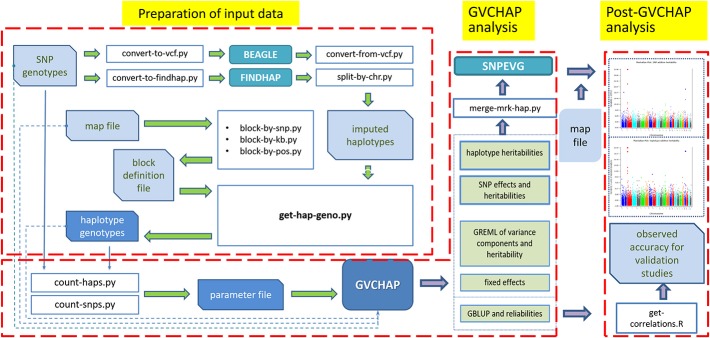
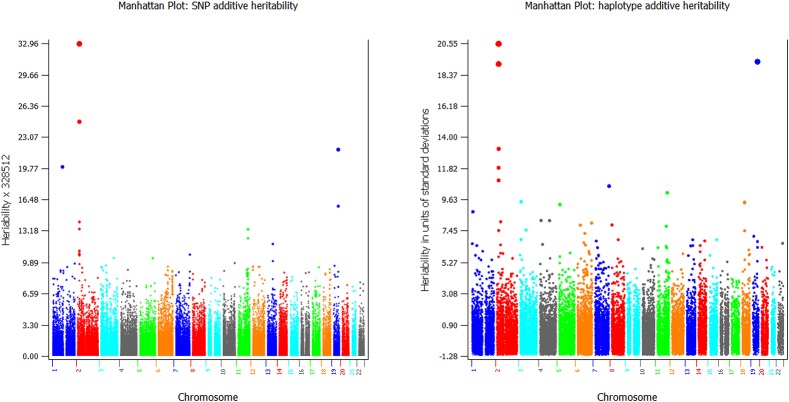
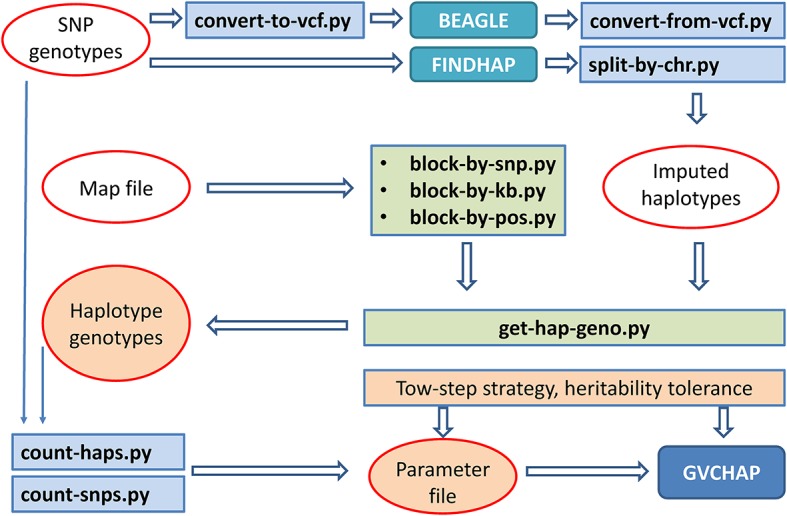
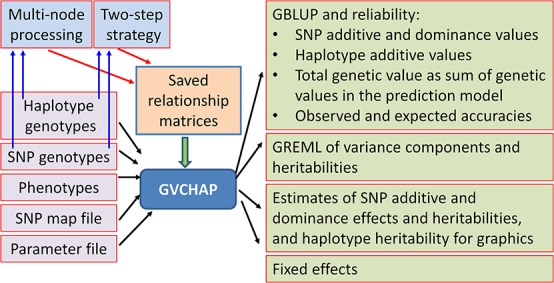
Haplotype prediction models open many possibilities to improve the accuracy of genomic selection but require more data processing and computing time than single-SNP prediction models. To facilitate haplotype analysis for genomic prediction and estimation using structural and functional genomic information, we developed a computing pipeline to implement haplotype analysis with capabilities for preparation of input data for haplotype analysis, genomic prediction and estimation using GVCHAP, and analysis of GVCHAP results. Data preparation includes utility programs for haplotype imputing; defining haplotype blocks by a fixed number of SNPs, a fixed distance in base pairs per block, or user defined block lengths based on structural or functional genomic information or a mixture of both types of information; and defining haplotype genotypes within each haplotype block. GVCHAP is the main program for genomic prediction and estimation, calculates GREML (genomic restricted maximum likelihood) estimates of variance components and heritabilities, and calculates GBLUP (genomic best linear unbiased prediction) for additive and dominance values of single SNPs as well as additive values of haplotypes with reliability estimates for training and validation populations. A two-step strategy and a method of multi-node processing are implemented to remove the computing bottleneck due to the creation of genomic relationship matrices for large samples. The analysis of GVCHAP results includes calculation of observed prediction accuracies from validation studies and preparation of input files for graphical visualization of heritability estimates of haplotype blocks as well as estimates of SNP effects and heritabilities. The entire pipeline provides an efficient and versatile computing tool for identifying the most accurate haplotype model among many candidate haplotype models utilizing structural and functional genomic information for genomic selection.
单倍型预测模型为提高基因组选择的准确性开辟了许多可能性,但比单核苷酸多态性(SNP)预测模型需要更多的数据处理和计算时间。为了利用结构和功能基因组信息促进基因组预测和估计的单倍型分析,我们开发了一个计算流程,以实现单倍型分析,具备为单倍型分析准备输入数据、使用GVCHAP进行基因组预测和估计以及分析GVCHAP结果的能力。数据准备包括用于单倍型填充的实用程序;通过固定数量的SNP、每个块固定的碱基对距离或基于结构或功能基因组信息或两种信息混合的用户定义块长度来定义单倍型块;以及在每个单倍型块内定义单倍型基因型。GVCHAP是基因组预测和估计的主要程序,计算方差分量和遗传力的基因组限制最大似然(GREML)估计值,并计算单SNP的加性和显性值以及单倍型加性值的基因组最佳线性无偏预测(GBLUP),同时给出训练和验证群体的可靠性估计值。实施了两步策略和多节点处理方法,以消除由于为大样本创建基因组关系矩阵而导致的计算瓶颈。GVCHAP结果分析包括根据验证研究计算观察到的预测准确性,以及准备输入文件,用于以图形方式可视化单倍型块的遗传力估计值以及SNP效应和遗传力估计值。整个流程提供了一个高效且通用的计算工具,用于在利用结构和功能基因组信息进行基因组选择的众多候选单倍型模型中识别最准确的单倍型模型。