Huang Feng, Qiu Yang, Li Qiaojun, Liu Shichao, Ni Fuchuan
College of Informatics, Huazhong Agricultural University, Wuhan, China.
School of Electronic and Information Engineering, Henan Polytechnic Institute, Henan Nanyang, China.
Front Bioeng Biotechnol. 2020 Apr 9;8:218. doi: 10.3389/fbioe.2020.00218. eCollection 2020.
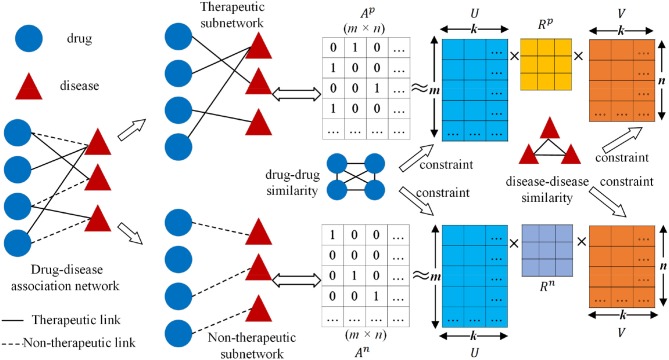
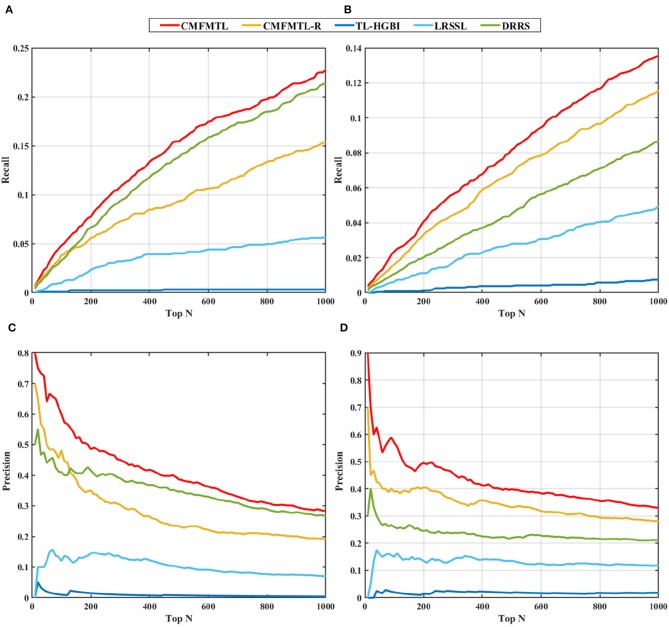
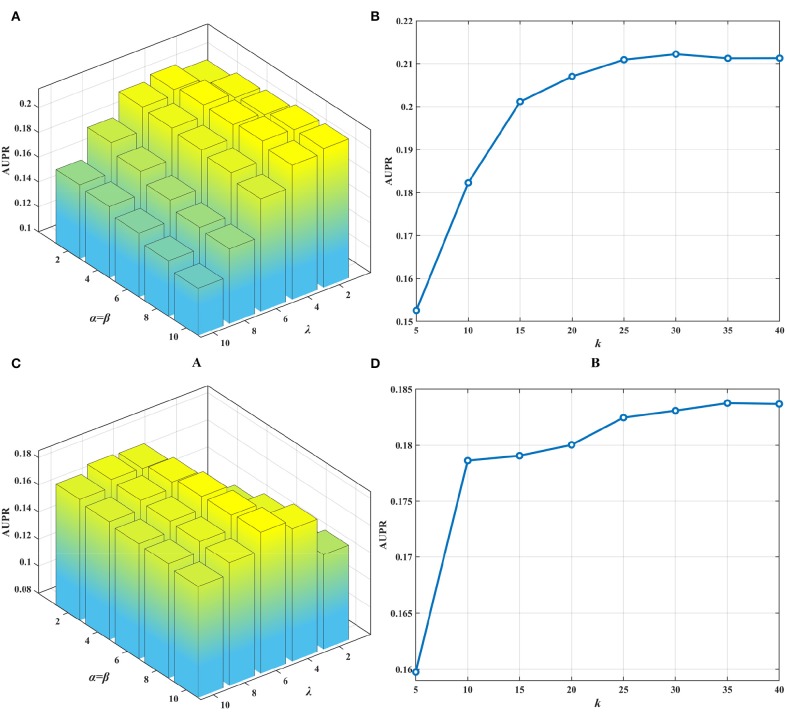
Identifying drug-disease associations is integral to drug development. Computationally prioritizing candidate drug-disease associations has attracted growing attention due to its contribution to reducing the cost of laboratory screening. Drug-disease associations involve different association types, such as drug indications and drug side effects. However, the existing models for predicting drug-disease associations merely concentrate on independent tasks: recommending novel indications to benefit drug repositioning, predicting potential side effects to prevent drug-induced risk, or only determining the existence of drug-disease association. They ignore crucial prior knowledge of the correlations between different association types. Since the Comparative Toxicogenomics Database (CTD) annotates the drug-disease associations as therapeutic or marker/mechanism, we consider predicting the two types of association. To this end, we propose a collective matrix factorization-based multi-task learning method (CMFMTL) in this paper. CMFMTL handles the problem as multi-task learning where each task is to predict one type of association, and two tasks complement and improve each other by capturing the relatedness between them. First, drug-disease associations are represented as a bipartite network with two types of links representing therapeutic effects and non-therapeutic effects. Then, CMFMTL, respectively, approximates the association matrix regarding each link type by matrix tri-factorization, and shares the low-dimensional latent representations for drugs and diseases in the two related tasks for the goal of collective learning. Finally, CMFMTL puts the two tasks into a unified framework and an efficient algorithm is developed to solve our proposed optimization problem. In the computational experiments, CMFMTL outperforms several state-of-the-art methods both in the two tasks. Moreover, case studies show that CMFMTL helps to find out novel drug-disease associations that are not included in CTD, and simultaneously predicts their association types.
识别药物与疾病的关联是药物研发的重要组成部分。通过计算对候选药物与疾病的关联进行优先级排序,因其有助于降低实验室筛查成本而受到越来越多的关注。药物与疾病的关联涉及不同的关联类型,如药物适应症和药物副作用。然而,现有的预测药物与疾病关联的模型仅专注于独立任务:推荐新的适应症以促进药物重新定位,预测潜在的副作用以预防药物诱导的风险,或者仅确定药物与疾病关联的存在。它们忽略了不同关联类型之间相关性的关键先验知识。由于比较毒理基因组学数据库(CTD)将药物与疾病的关联注释为治疗性或标志物/机制性,我们考虑预测这两种关联类型。为此,我们在本文中提出了一种基于集体矩阵分解的多任务学习方法(CMFMTL)。CMFMTL将该问题作为多任务学习来处理,其中每个任务是预测一种关联类型,并且两个任务通过捕捉它们之间的相关性相互补充和改进。首先,药物与疾病的关联被表示为一个二分网络,其中两种类型的链接分别代表治疗效果和非治疗效果。然后,CMFMTL通过矩阵三分解分别逼近关于每种链接类型的关联矩阵,并在两个相关任务中共享药物和疾病的低维潜在表示,以实现集体学习的目标。最后,CMFMTL将两个任务放入一个统一的框架中,并开发了一种高效算法来解决我们提出的优化问题。在计算实验中,CMFMTL在这两个任务中均优于几种现有最先进的方法。此外,案例研究表明,CMFMTL有助于发现CTD中未包含的新型药物与疾病的关联,并同时预测它们的关联类型。