School of Computer Science, Wuhan University, Wuhan, 430072, China.
School of Electronic Information, Wuhan University, Wuhan, 430072, China.
BMC Bioinformatics. 2018 Jun 19;19(1):233. doi: 10.1186/s12859-018-2220-4.
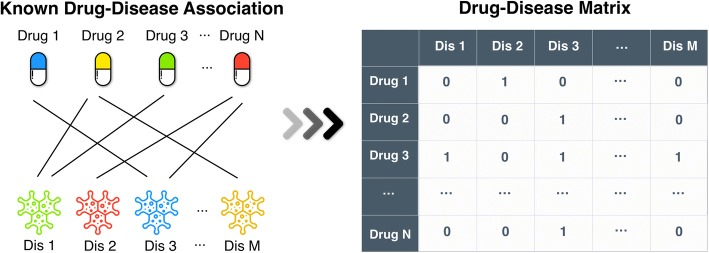
Drug-disease associations provide important information for the drug discovery. Wet experiments that identify drug-disease associations are time-consuming and expensive. However, many drug-disease associations are still unobserved or unknown. The development of computational methods for predicting unobserved drug-disease associations is an important and urgent task.
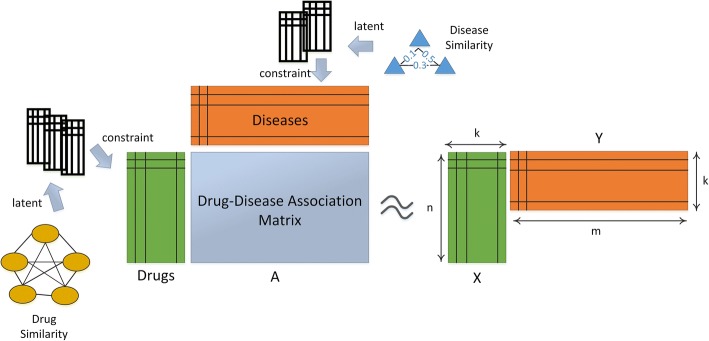
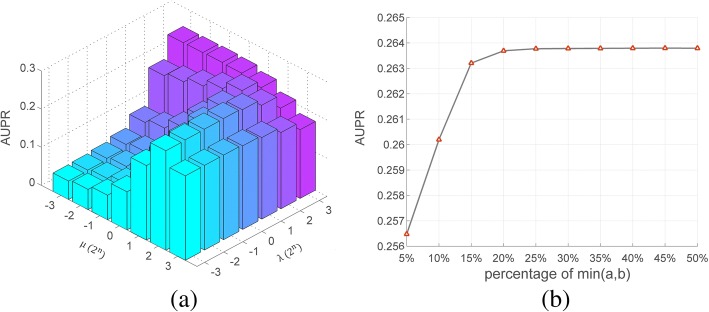
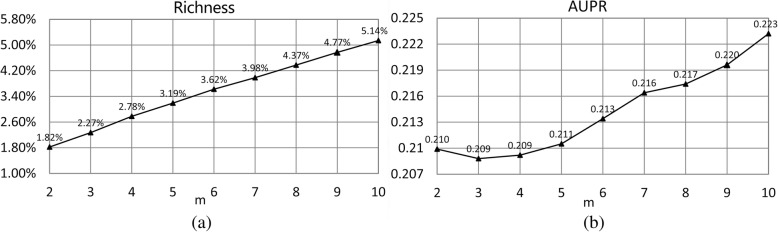
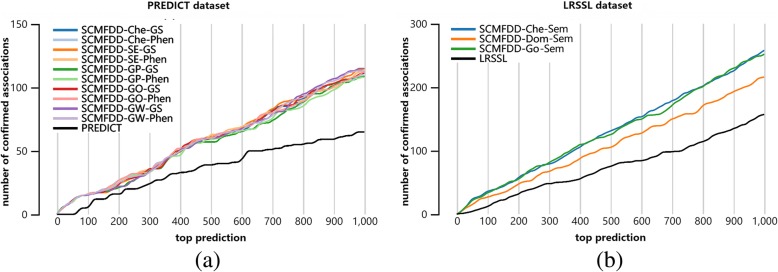
In this paper, we proposed a similarity constrained matrix factorization method for the drug-disease association prediction (SCMFDD), which makes use of known drug-disease associations, drug features and disease semantic information. SCMFDD projects the drug-disease association relationship into two low-rank spaces, which uncover latent features for drugs and diseases, and then introduces drug feature-based similarities and disease semantic similarity as constraints for drugs and diseases in low-rank spaces. Different from the classic matrix factorization technique, SCMFDD takes the biological context of the problem into account. In computational experiments, the proposed method can produce high-accuracy performances on benchmark datasets, and outperform existing state-of-the-art prediction methods when evaluated by five-fold cross validation and independent testing.
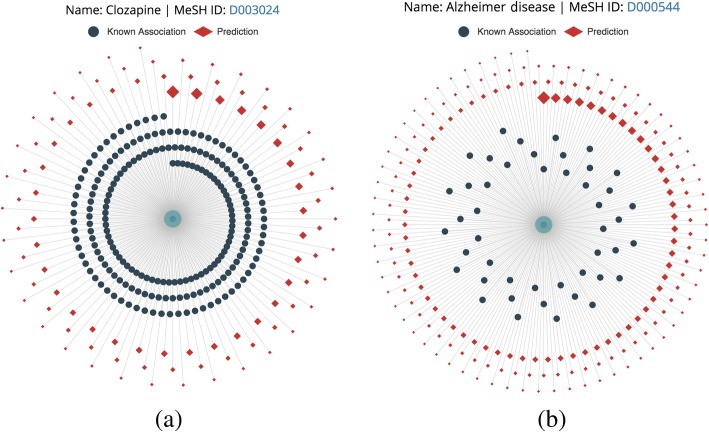
We developed a user-friendly web server by using known associations collected from the CTD database, available at http://www.bioinfotech.cn/SCMFDD/ . The case studies show that the server can find out novel associations, which are not included in the CTD database.
药物-疾病关联为药物发现提供了重要信息。然而,许多药物-疾病关联仍然未被观察到或未知。开发用于预测未观察到的药物-疾病关联的计算方法是一项重要而紧迫的任务。
在本文中,我们提出了一种基于相似性约束矩阵分解的药物-疾病关联预测方法(SCMFDD),该方法利用已知的药物-疾病关联、药物特征和疾病语义信息。SCMFDD 将药物-疾病关联关系投影到两个低秩空间中,揭示药物和疾病的潜在特征,然后引入基于药物特征的相似度和疾病语义相似度作为低秩空间中药物和疾病的约束。与经典矩阵分解技术不同,SCMFDD 考虑了问题的生物学背景。在计算实验中,该方法在基准数据集上可以产生高精度的性能,并且在五重交叉验证和独立测试评估中优于现有的最先进的预测方法。
我们利用从 CTD 数据库中收集的已知关联开发了一个用户友好的网络服务器,网址为 http://www.bioinfotech.cn/SCMFDD/。案例研究表明,该服务器可以发现 CTD 数据库中未包含的新关联。