TNO, Zeist, The Netherlands.
PLoS One. 2020 May 6;15(5):e0232680. doi: 10.1371/journal.pone.0232680. eCollection 2020.
N-of-1 designs gain popularity in nutritional research because of the improving technological possibilities, practical applicability and promise of increased accuracy and sensitivity, especially in the field of personalized nutrition. This move asks for a search of applicable statistical methods.
To demonstrate the differences of three popular statistical methods in analyzing treatment effects of data obtained in N-of-1 designs.
We compare Individual-participant data meta-analysis, frequentist and Bayesian linear mixed effect models using a simulation experiment. Furthermore, we demonstrate the merits of the Bayesian model including prior information by analyzing data of an empirical study on weight loss.
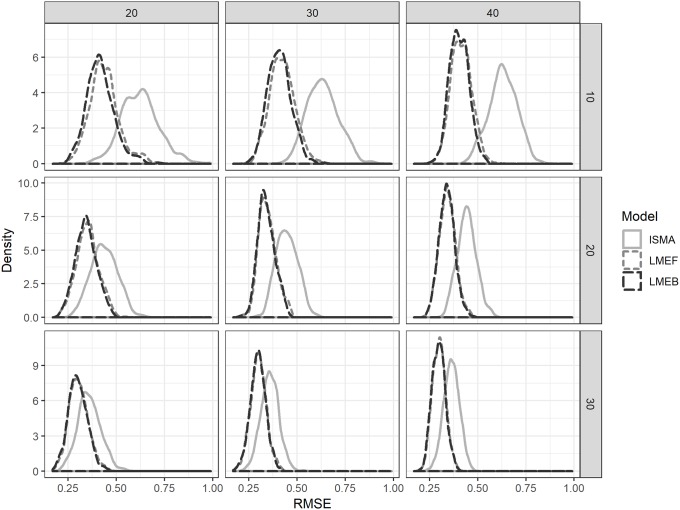
The linear mixed effect models are to be preferred over the meta-analysis method, since the individual effects are estimated more accurately as evidenced by the lower errors, especially with lower sample sizes. Differences between Bayesian and frequentist mixed models were found to be small, indicating that they will lead to the same results without including an informative prior.
For empirical data, the Bayesian mixed model allows the inclusion of prior knowledge and gives potential for population based and personalized inference.
由于技术可能性的提高、实用性和提高准确性和灵敏度的承诺,尤其是在个性化营养领域,N-of-1 设计在营养研究中越来越受欢迎。这一举措需要寻找适用的统计方法。
展示三种流行的统计方法在分析 N-of-1 设计中获得的数据的治疗效果方面的差异。
我们使用模拟实验比较个体参与者数据荟萃分析、频率论和贝叶斯线性混合效应模型。此外,我们通过分析减肥实证研究的数据,展示了贝叶斯模型包括先验信息的优点。
线性混合效应模型优于荟萃分析方法,因为个体效应的估计更准确,误差更低,尤其是在样本量较低的情况下。发现贝叶斯和频率论混合模型之间的差异很小,表明在不包含信息先验的情况下,它们将得出相同的结果。
对于实证数据,贝叶斯混合模型允许包含先验知识,并为基于人群和个性化推断提供了可能性。