Loschmidt Laboratories, Department of Experimental Biology and Research Center for Toxic Compounds in the Environment RECETOX, Faculty of Science, Masaryk University, Brno, Czech Republic.
IT4Innovations Centre of Excellence, Faculty of Information Technology, Brno University of Technology, Bozetechova 2, Brno, Czech Republic.
Nucleic Acids Res. 2020 Jul 2;48(W1):W104-W109. doi: 10.1093/nar/gkaa372.
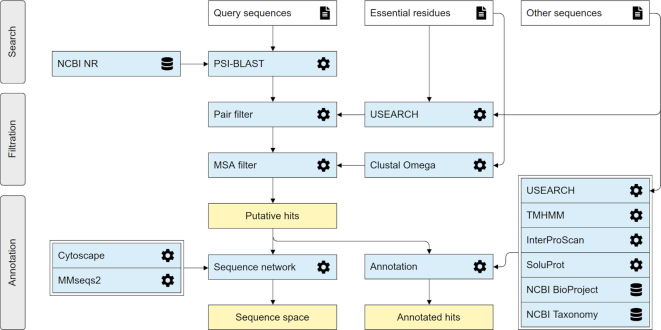
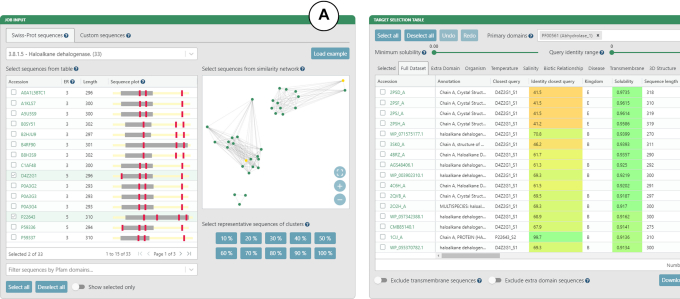
Millions of protein sequences are being discovered at an incredible pace, representing an inexhaustible source of biocatalysts. Despite genomic databases growing exponentially, classical biochemical characterization techniques are time-demanding, cost-ineffective and low-throughput. Therefore, computational methods are being developed to explore the unmapped sequence space efficiently. Selection of putative enzymes for biochemical characterization based on rational and robust analysis of all available sequences remains an unsolved problem. To address this challenge, we have developed EnzymeMiner-a web server for automated screening and annotation of diverse family members that enables selection of hits for wet-lab experiments. EnzymeMiner prioritizes sequences that are more likely to preserve the catalytic activity and are heterologously expressible in a soluble form in Escherichia coli. The solubility prediction employs the in-house SoluProt predictor developed using machine learning. EnzymeMiner reduces the time devoted to data gathering, multi-step analysis, sequence prioritization and selection from days to hours. The successful use case for the haloalkane dehalogenase family is described in a comprehensive tutorial available on the EnzymeMiner web page. EnzymeMiner is a universal tool applicable to any enzyme family that provides an interactive and easy-to-use web interface freely available at https://loschmidt.chemi.muni.cz/enzymeminer/.
数以百万计的蛋白质序列正在以前所未有的速度被发现,它们代表着取之不尽的生物催化剂来源。尽管基因组数据库呈指数级增长,但经典的生化特征分析技术既费时、成本又高,而且通量低。因此,人们正在开发计算方法来有效地探索未映射的序列空间。基于对所有可用序列的合理和稳健分析,选择具有潜在酶活性的候选序列进行生化特征分析仍然是一个未解决的问题。为了解决这一挑战,我们开发了 EnzymeMiner——一个用于自动筛选和注释多种家族成员的网络服务器,它可以选择用于湿实验室实验的命中。EnzymeMiner 优先选择更有可能保留催化活性且能够以可溶形式在大肠杆菌中异源表达的序列。该可溶预测使用了内部开发的基于机器学习的 SoluProt 预测器。EnzymeMiner 将用于数据收集、多步骤分析、序列优先级排序和选择的时间从数天减少到数小时。卤代烷烃脱卤酶家族的成功用例在 EnzymeMiner 网页上提供的综合教程中进行了描述。EnzymeMiner 是一种通用工具,适用于任何酶家族,它提供了一个交互式和易于使用的网络界面,可在 https://loschmidt.chemi.muni.cz/enzymeminer/ 免费获得。