School of Biological Sciences, Seoul National University, Seoul, 08826, South Korea.
Center for Computational Biology, Whiting School of Engineering, Johns Hopkins University, Baltimore, 21218, Maryland, USA.
Genome Biol. 2020 May 12;21(1):115. doi: 10.1186/s13059-020-02023-1.
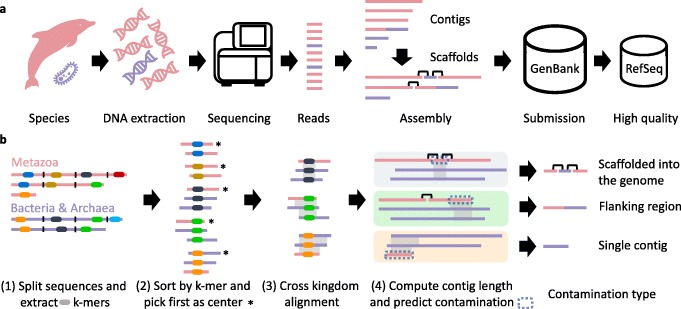
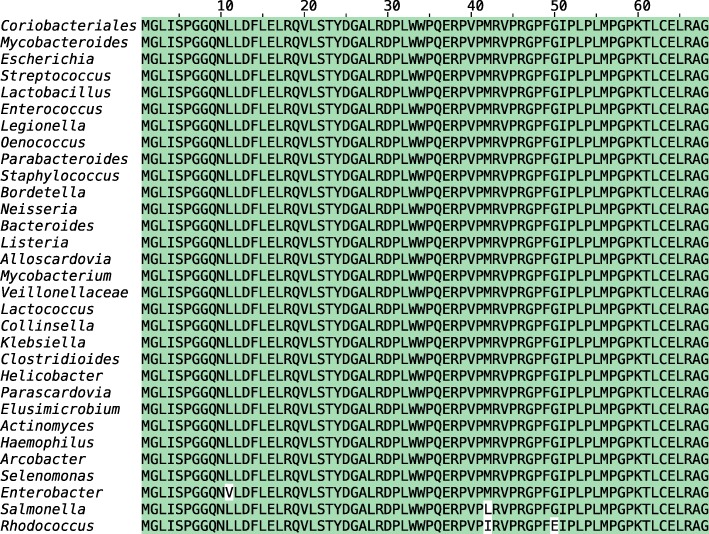
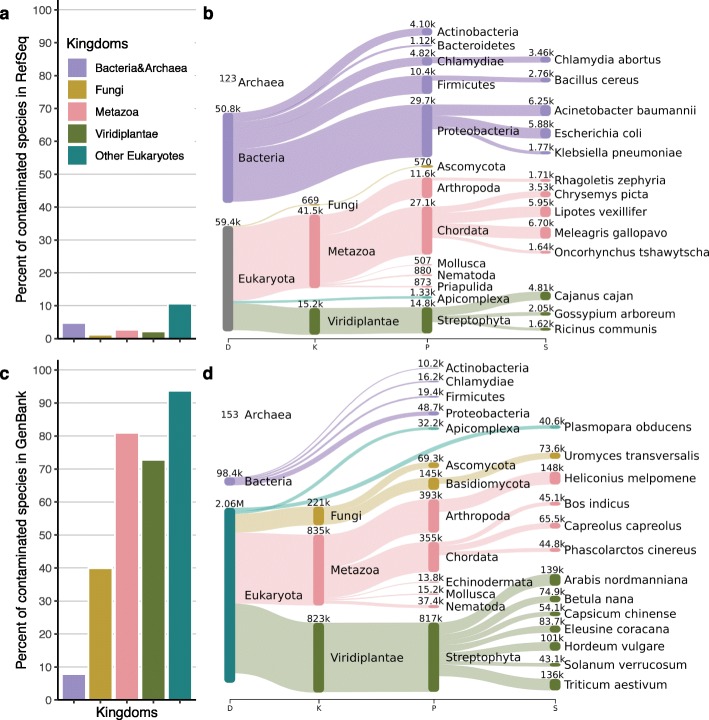
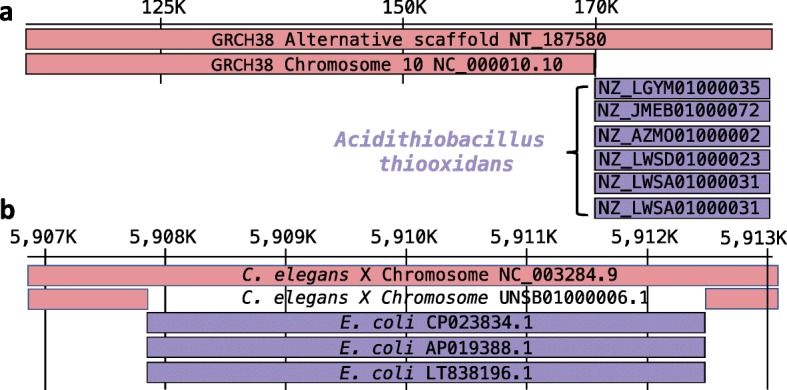
Genomic analyses are sensitive to contamination in public databases caused by incorrectly labeled reference sequences. Here, we describe Conterminator, an efficient method to detect and remove incorrectly labeled sequences by an exhaustive all-against-all sequence comparison. Our analysis reports contamination of 2,161,746, 114,035, and 14,148 sequences in the RefSeq, GenBank, and NR databases, respectively, spanning the whole range from draft to "complete" model organism genomes. Our method scales linearly with input size and can process 3.3 TB in 12 days on a 32-core computer. Conterminator can help ensure the quality of reference databases. Source code (GPLv3): https://github.com/martin-steinegger/conterminator.
基因组分析对公共数据库中因参考序列标签错误而导致的污染非常敏感。在这里,我们描述了 Conterminator,这是一种通过全面的序列两两比较来检测和去除错误标记序列的有效方法。我们的分析报告称,RefSeq、GenBank 和 NR 数据库中分别有 2161746、114035 和 14148 个序列受到污染,涵盖了从草案到“完整”模式生物基因组的整个范围。我们的方法与输入大小呈线性比例关系,在 32 核计算机上每天可处理 3.3 TB。Conterminator 可以帮助确保参考数据库的质量。源代码(GPLv3):https://github.com/martin-steinegger/conterminator。