Departamento de Ciencia y Tecnología, Universidad Nacional de Quilmes, CONICET, Roque Saenz Peña 352, Bernal, Buenos Aires B1876BXD, Argentina.
Fundación Instituto Leloir, Instituto de Investigaciones Bioquímicas de Buenos Aires, CONICET, Av. Patricias Argentinas 435, Ciudad de Buenos Aires C1405BWE, Argentina.
Database (Oxford). 2020 Jan 1;2020. doi: 10.1093/database/baaa040.
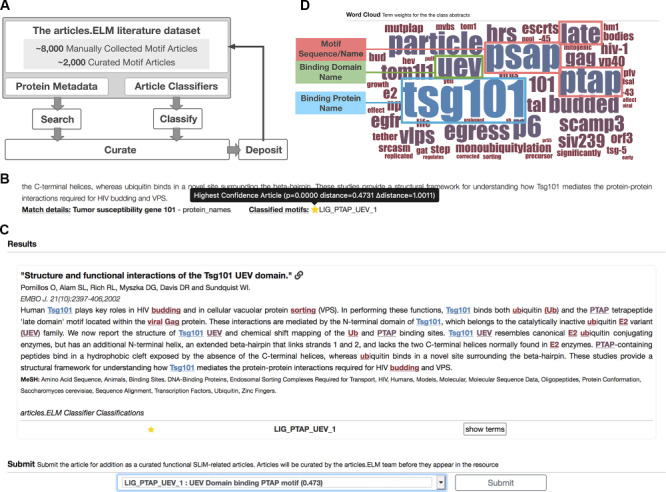
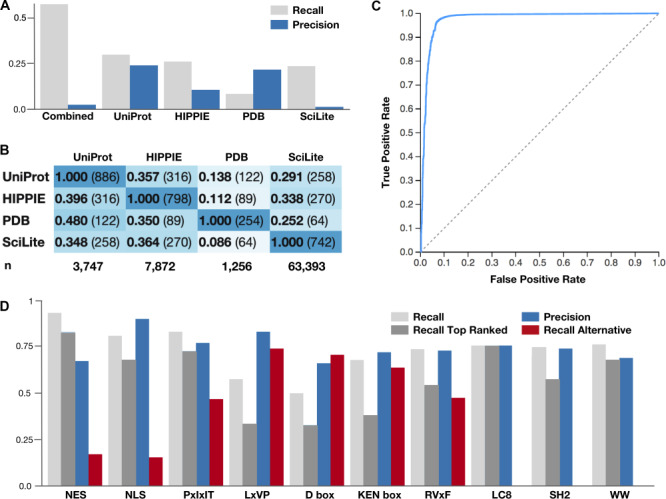
Modern biology produces data at a staggering rate. Yet, much of these biological data is still isolated in the text, figures, tables and supplementary materials of articles. As a result, biological information created at great expense is significantly underutilised. The protein motif biology field does not have sufficient resources to curate the corpus of motif-related literature and, to date, only a fraction of the available articles have been curated. In this study, we develop a set of tools and a web resource, 'articles.ELM', to rapidly identify the motif literature articles pertinent to a researcher's interest. At the core of the resource is a manually curated set of about 8000 motif-related articles. These articles are automatically annotated with a range of relevant biological data allowing in-depth search functionality. Machine-learning article classification is used to group articles based on their similarity to manually curated motif classes in the Eukaryotic Linear Motif resource. Articles can also be manually classified within the resource. The 'articles.ELM' resource permits the rapid and accurate discovery of relevant motif articles thereby improving the visibility of motif literature and simplifying the recovery of valuable biological insights sequestered within scientific articles. Consequently, this web resource removes a critical bottleneck in scientific productivity for the motif biology field. Database URL: http://slim.icr.ac.uk/articles/.
现代生物学以惊人的速度产生数据。然而,这些生物数据中的很大一部分仍然孤立在文章的文本、图表、表格和补充材料中。因此,花费巨大代价创造的生物信息被严重低估了。蛋白质基序生物学领域没有足够的资源来整理与基序相关的文献,迄今为止,只有一小部分可用的文章被整理了。在这项研究中,我们开发了一套工具和一个网络资源“articles.ELM”,以快速识别与研究人员兴趣相关的基序文献文章。该资源的核心是一组大约 8000 篇经过手动整理的基序相关文章。这些文章被自动注释了一系列相关的生物学数据,允许进行深入的搜索功能。机器学习的文章分类用于根据与真核线性基序资源中的手动整理的基序类的相似性对文章进行分组。文章也可以在资源内进行手动分类。“articles.ELM”资源允许快速准确地发现相关的基序文章,从而提高基序文献的可见度,并简化从科学文章中获取有价值的生物见解的过程。因此,这个网络资源消除了基序生物学领域科学生产力的一个关键瓶颈。数据库网址:http://slim.icr.ac.uk/articles/。