Department of Biology, North Carolina State University, Raleigh, North Carolina, United States of America.
PLoS One. 2013 Apr 17;8(4):e58201. doi: 10.1371/journal.pone.0058201. Print 2013.
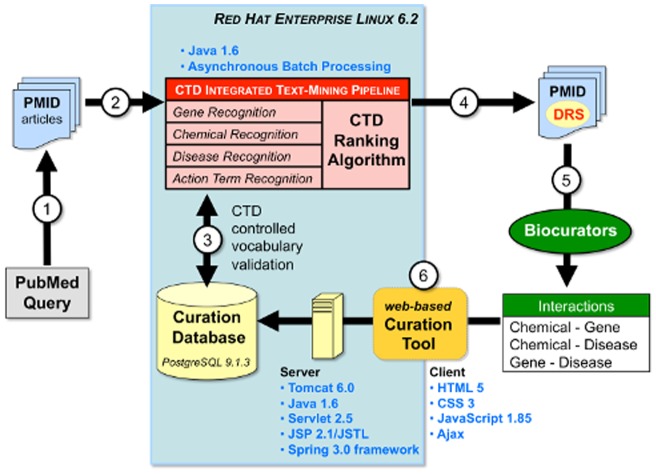
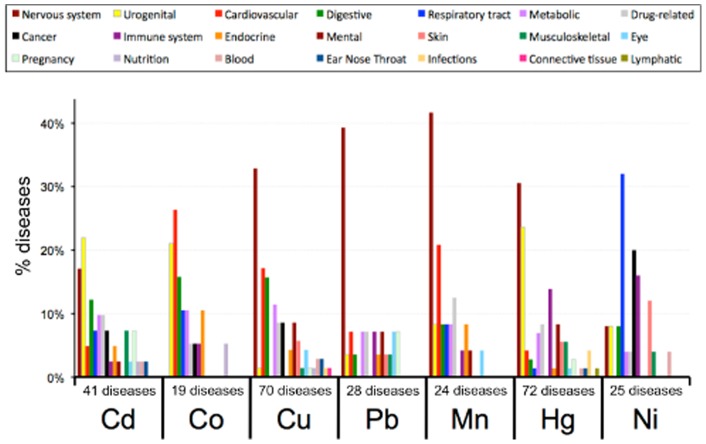
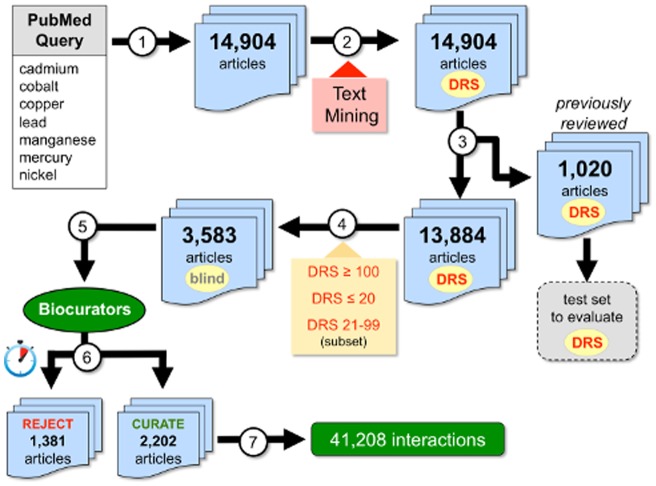
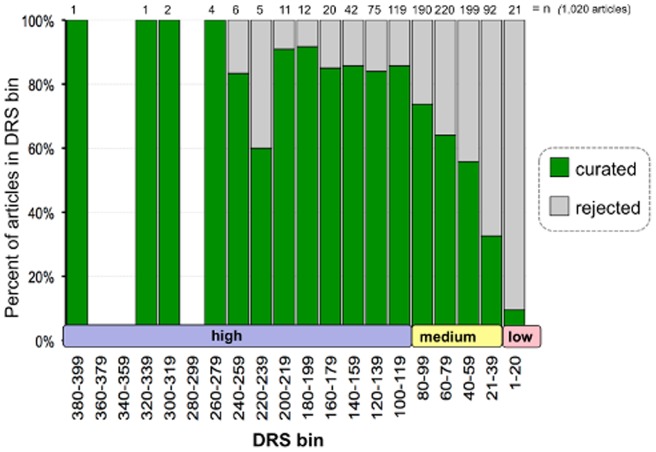
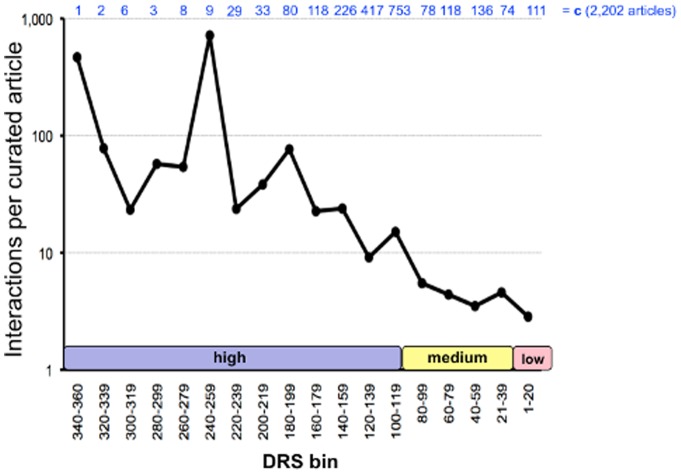
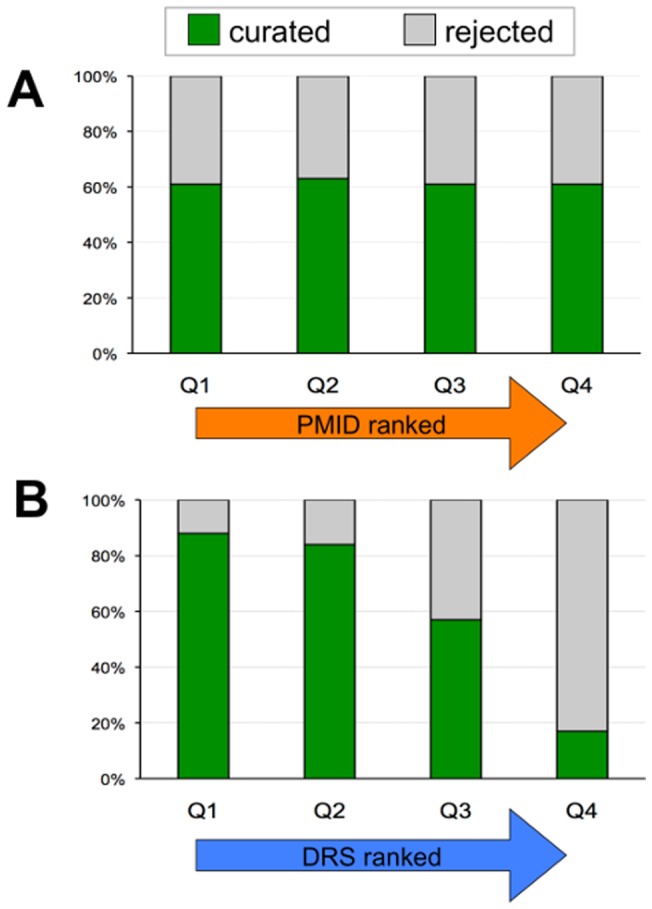
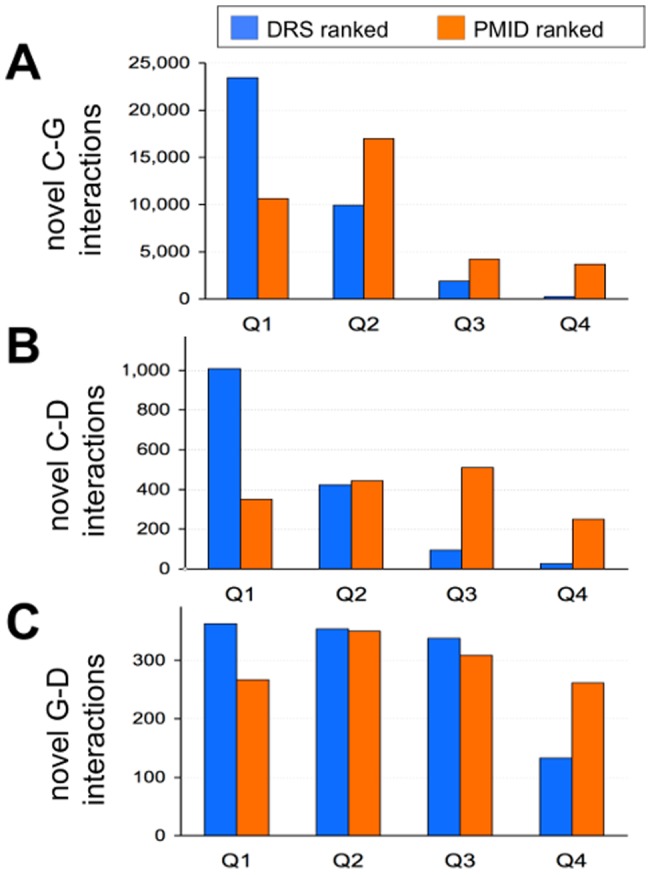
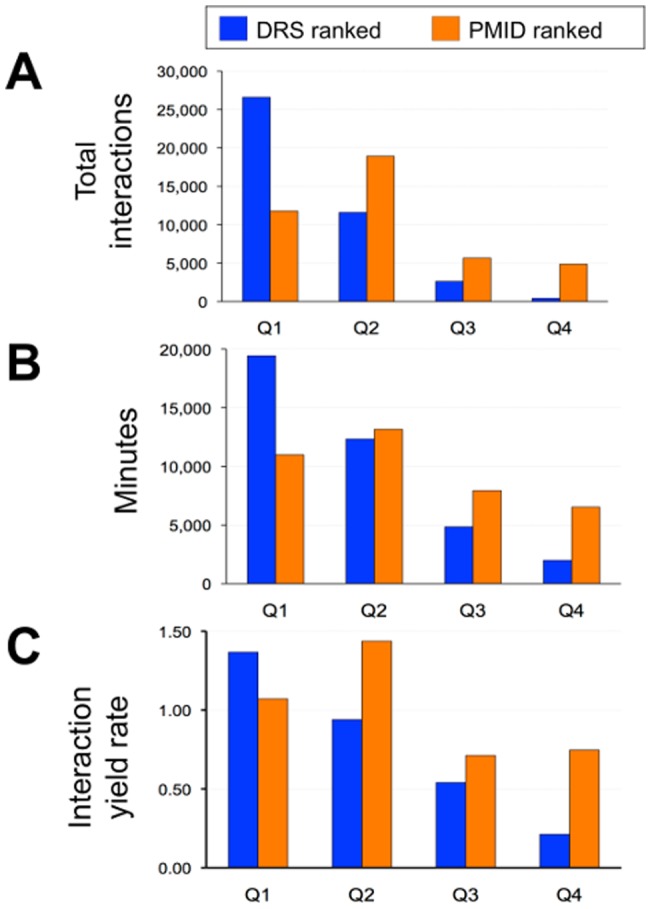
The Comparative Toxicogenomics Database (CTD; http://ctdbase.org/) is a public resource that curates interactions between environmental chemicals and gene products, and their relationships to diseases, as a means of understanding the effects of environmental chemicals on human health. CTD provides a triad of core information in the form of chemical-gene, chemical-disease, and gene-disease interactions that are manually curated from scientific articles. To increase the efficiency, productivity, and data coverage of manual curation, we have leveraged text mining to help rank and prioritize the triaged literature. Here, we describe our text-mining process that computes and assigns each article a document relevancy score (DRS), wherein a high DRS suggests that an article is more likely to be relevant for curation at CTD. We evaluated our process by first text mining a corpus of 14,904 articles triaged for seven heavy metals (cadmium, cobalt, copper, lead, manganese, mercury, and nickel). Based upon initial analysis, a representative subset corpus of 3,583 articles was then selected from the 14,094 articles and sent to five CTD biocurators for review. The resulting curation of these 3,583 articles was analyzed for a variety of parameters, including article relevancy, novel data content, interaction yield rate, mean average precision, and biological and toxicological interpretability. We show that for all measured parameters, the DRS is an effective indicator for scoring and improving the ranking of literature for the curation of chemical-gene-disease information at CTD. Here, we demonstrate how fully incorporating text mining-based DRS scoring into our curation pipeline enhances manual curation by prioritizing more relevant articles, thereby increasing data content, productivity, and efficiency.
比较毒理学基因组学数据库(CTD;http://ctdbase.org/)是一个公共资源,它整理环境化学物质与基因产物之间的相互作用及其与疾病的关系,以此来了解环境化学物质对人类健康的影响。CTD 以化学物质-基因、化学物质-疾病和基因-疾病相互作用的形式提供了核心信息的三元组,这些信息是从科学文章中手动整理的。为了提高手动整理的效率、生产力和数据覆盖范围,我们利用文本挖掘来帮助对分类文献进行排名和优先级排序。在这里,我们描述了我们的文本挖掘过程,该过程计算并为每篇文章分配一个文档相关性评分(DRS),其中 DRS 较高表明该文章更有可能与 CTD 的整理相关。我们首先对 14904 篇针对七种重金属(镉、钴、铜、铅、锰、汞和镍)进行分类的文章进行了文本挖掘,从而对我们的过程进行了评估。根据初步分析,从 14094 篇文章中选择了一个具有代表性的 3583 篇文章子集,并将其发送给五名 CTD 生物编纂者进行审查。对这 3583 篇文章的整理结果进行了各种参数的分析,包括文章相关性、新颖数据内容、相互作用产率、平均精度、生物学和毒理学可解释性。我们表明,对于所有测量的参数,DRS 是一种有效的指标,可以对文献进行评分和排名,从而提高 CTD 化学物质-基因-疾病信息整理的排名。在这里,我们展示了如何将基于文本挖掘的 DRS 评分完全纳入我们的编纂过程,通过优先考虑更相关的文章来增强手动编纂,从而增加数据内容、生产力和效率。