Fujiwara Koichi, Huang Yukun, Hori Kentaro, Nishioji Kenichi, Kobayashi Masao, Kamaguchi Mai, Kano Manabu
Department of Material Process Engineering, Nagoya University, Nagoya, Japan.
Department of Systems Science, Kyoto University, Kyoto, Japan.
Front Public Health. 2020 May 19;8:178. doi: 10.3389/fpubh.2020.00178. eCollection 2020.
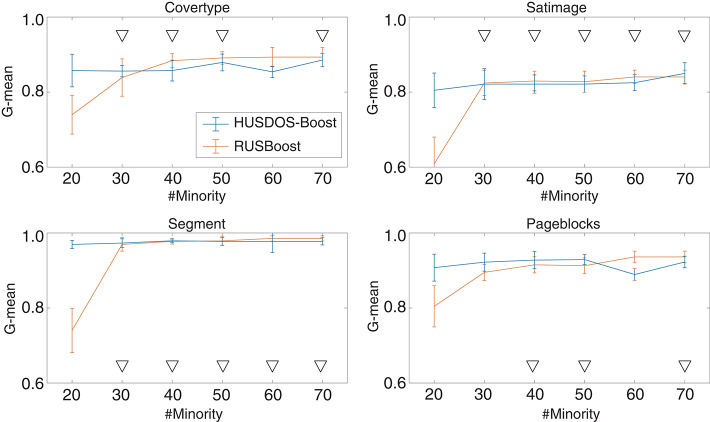
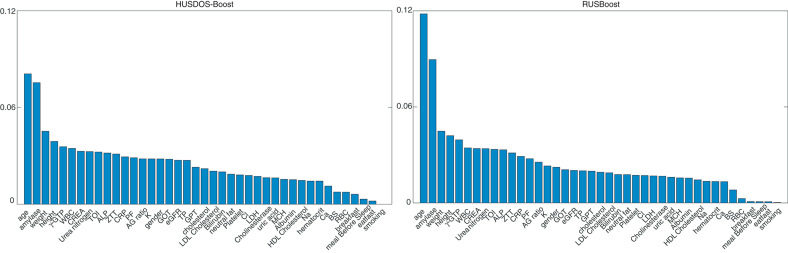
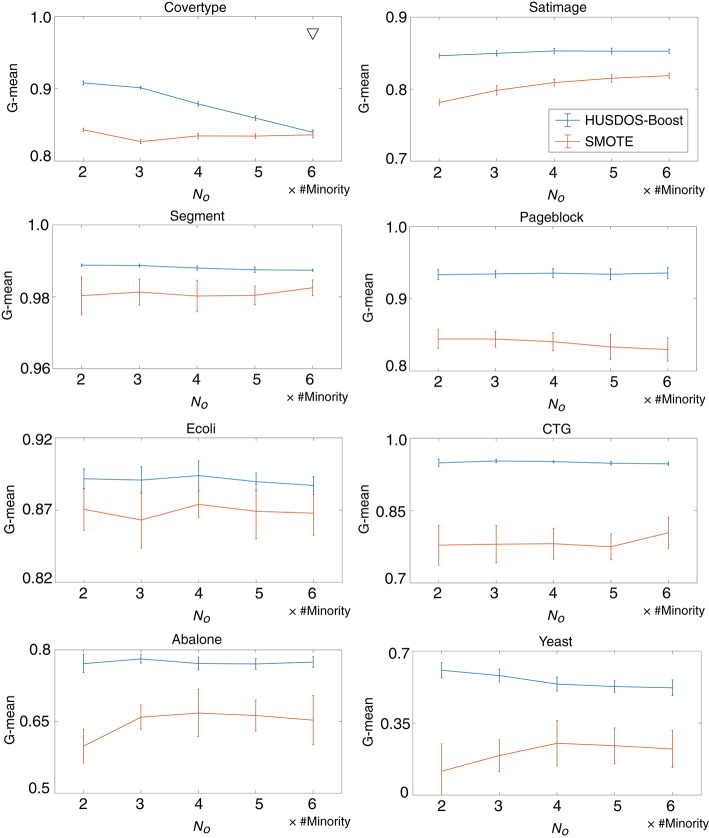
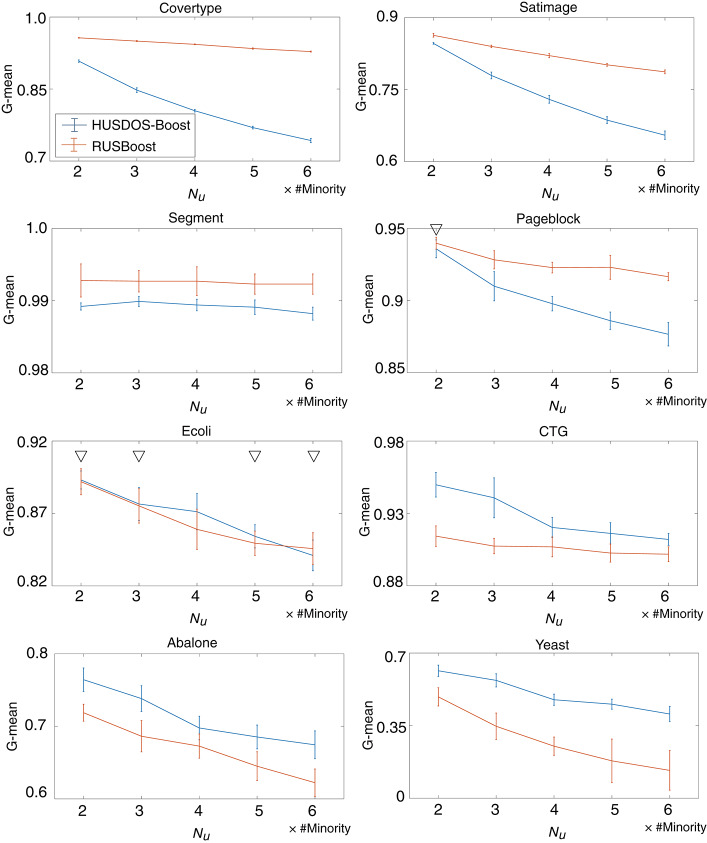
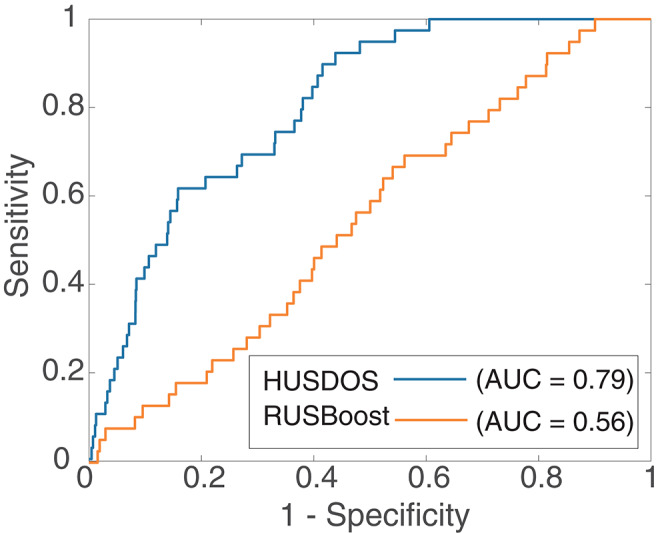
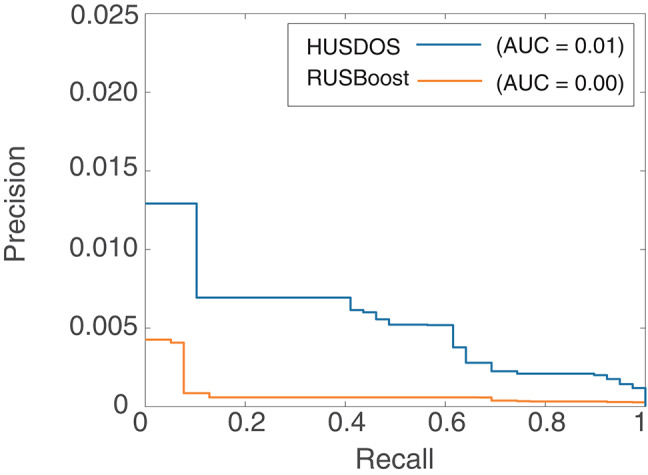
A considerable amount of health record (HR) data has been stored due to recent advances in the digitalization of medical systems. However, it is not always easy to analyze HR data, particularly when the number of persons with a target disease is too small in comparison with the population. This situation is called the imbalanced data problem. Over-sampling and under-sampling are two approaches for redressing an imbalance between minority and majority examples, which can be combined into ensemble algorithms. However, these approaches do not function when the absolute number of minority examples is small, which is called the extremely imbalanced and small minority (EISM) data problem. The present work proposes a new algorithm called boosting combined with heuristic under-sampling and distribution-based sampling (HUSDOS-Boost) to solve the EISM data problem. To make an artificially balanced dataset from the original imbalanced datasets, HUSDOS-Boost uses both under-sampling and over-sampling to eliminate redundant majority examples based on prior boosting results and to generate artificial minority examples by following the minority class distribution. The performance and characteristics of HUSDOS-Boost were evaluated through application to eight imbalanced datasets. In addition, the algorithm was applied to original clinical HR data to detect patients with stomach cancer. These results showed that HUSDOS-Boost outperformed current imbalanced data handling methods, particularly when the data are EISM. Thus, the proposed HUSDOS-Boost is a useful methodology of HR data analysis.
由于医疗系统数字化的最新进展,大量的健康记录(HR)数据得以存储。然而,分析HR数据并非总是易事,尤其是当患有目标疾病的人数与总体相比过少时。这种情况被称为数据不平衡问题。过采样和欠采样是纠正少数和多数样本之间不平衡的两种方法,它们可以组合成集成算法。然而,当少数样本的绝对数量很少时,这些方法就不起作用了,这被称为极度不平衡和少数样本(EISM)数据问题。本研究提出了一种新的算法,称为结合启发式欠采样和基于分布采样的提升算法(HUSDOS-Boost),以解决EISM数据问题。为了从原始的不平衡数据集中创建一个人工平衡的数据集,HUSDOS-Boost同时使用欠采样和过采样,根据先前的提升结果消除冗余的多数样本,并按照少数类分布生成人工少数样本。通过将HUSDOS-Boost应用于八个不平衡数据集,对其性能和特点进行了评估。此外,该算法还应用于原始临床HR数据,以检测胃癌患者。这些结果表明,HUSDOS-Boost优于当前的数据不平衡处理方法,特别是在数据为EISM的情况下。因此,所提出的HUSDOS-Boost是一种有用的HR数据分析方法。