Department of Statistics, University of Oxford, 24-29 St Giles, Oxford OX1 3LB, U.K.
BenevolentAI, 4-8 Maple Street, London W1T 5HD, U.K.
J Chem Inf Model. 2020 Aug 24;60(8):3722-3730. doi: 10.1021/acs.jcim.0c00263. Epub 2020 Aug 4.
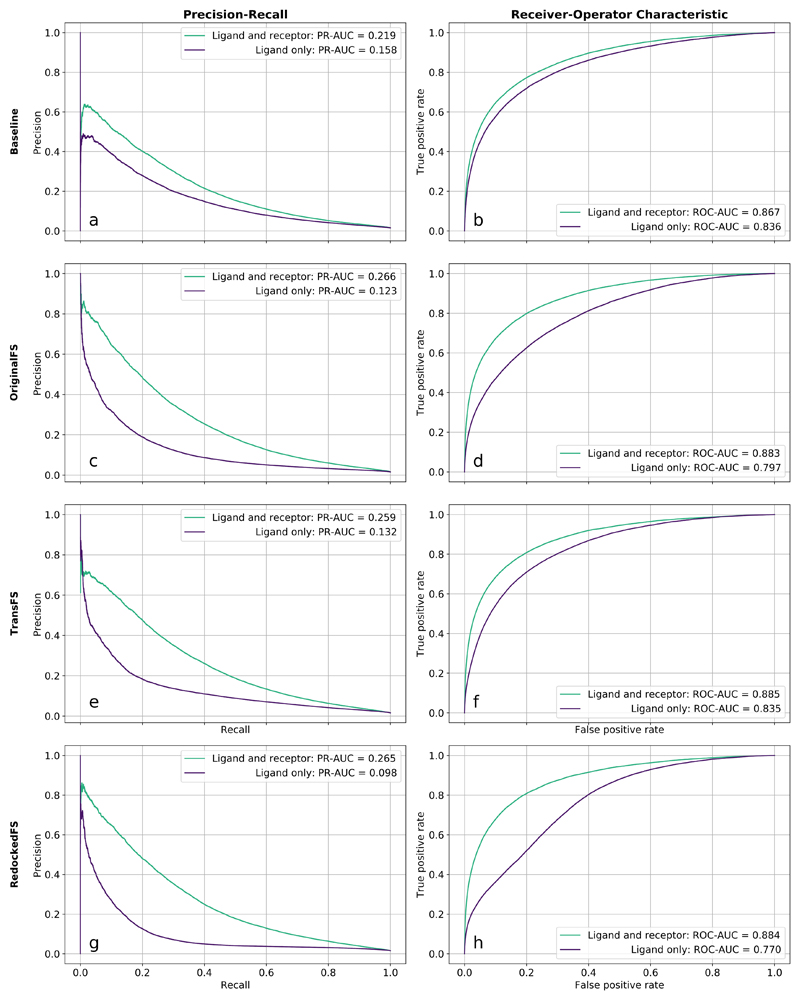
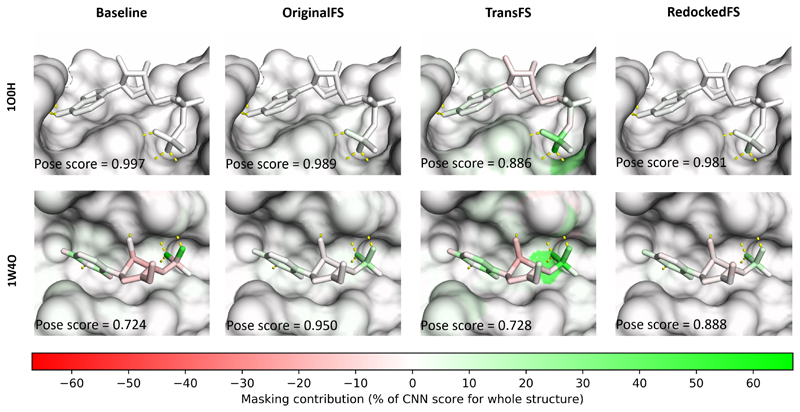
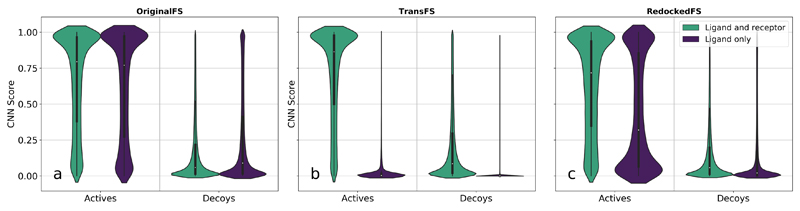
Current deep learning methods for structure-based virtual screening take the structures of both the protein and the ligand as input but make little or no use of the protein structure when predicting ligand binding. Here, we show how a relatively simple method of data set augmentation forces such deep learning methods to take into account information from the protein. Models trained in this way are more generalizable (make better predictions on protein/ligand complexes from a different distribution to the training data). They also assign more meaningful importance to the protein and ligand atoms involved in binding. Overall, our results show that data set augmentation can help deep learning-based virtual screening to learn physical interactions rather than data set biases.
目前基于结构的虚拟筛选的深度学习方法将蛋白质和配体的结构都作为输入,但在预测配体结合时很少或根本不利用蛋白质结构。在这里,我们展示了一种相对简单的数据增强方法,迫使这些深度学习方法考虑来自蛋白质的信息。以这种方式训练的模型具有更好的通用性(在来自与训练数据不同分布的蛋白质/配体复合物上做出更好的预测)。它们还赋予了在结合中涉及的蛋白质和配体原子更有意义的重要性。总的来说,我们的结果表明,数据集增强可以帮助基于深度学习的虚拟筛选学习物理相互作用,而不是数据集偏差。