Stanford Center for Biomedical Informatics Research, Department of Medicine, Stanford University, Stanford, CA 94305, USA.
Department of Electrical Engineering, Stanford University, Stanford, CA 94305, USA.
Gigascience. 2020 Aug 1;9(8). doi: 10.1093/gigascience/giaa082.
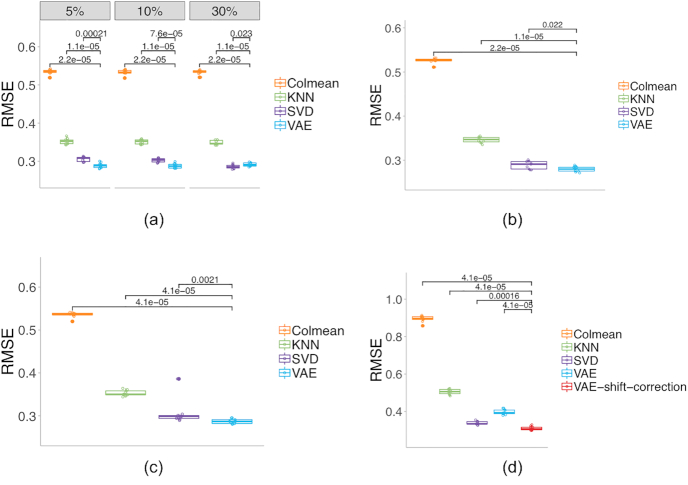
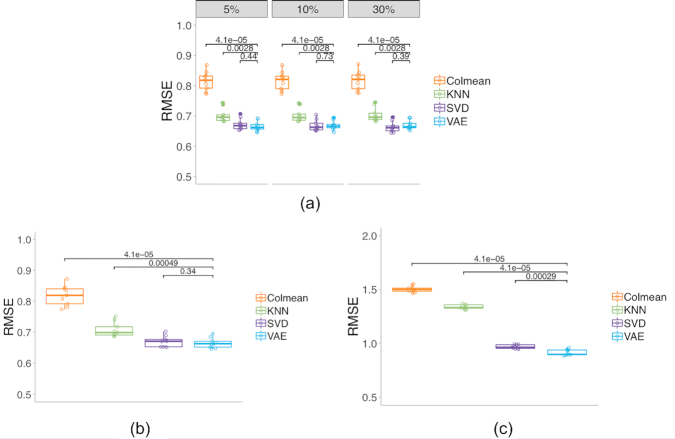
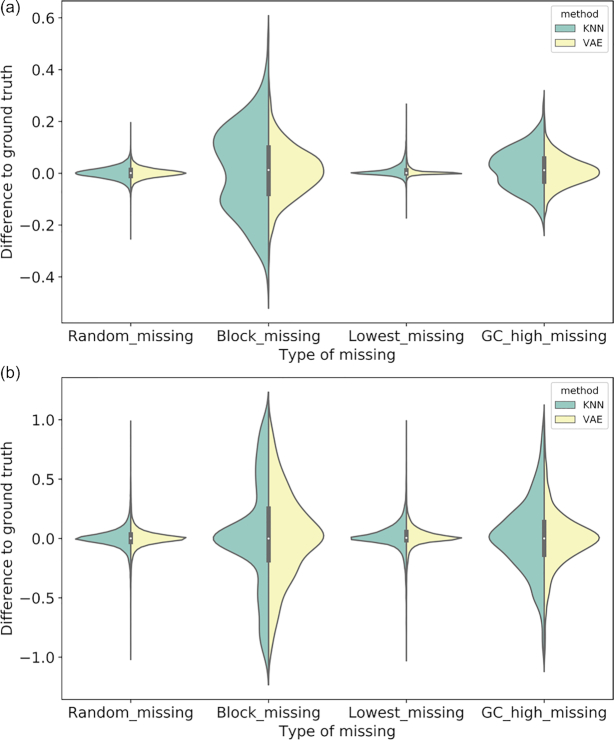
As missing values are frequently present in genomic data, practical methods to handle missing data are necessary for downstream analyses that require complete data sets. State-of-the-art imputation techniques, including methods based on singular value decomposition and K-nearest neighbors, can be computationally expensive for large data sets and it is difficult to modify these algorithms to handle certain cases not missing at random.
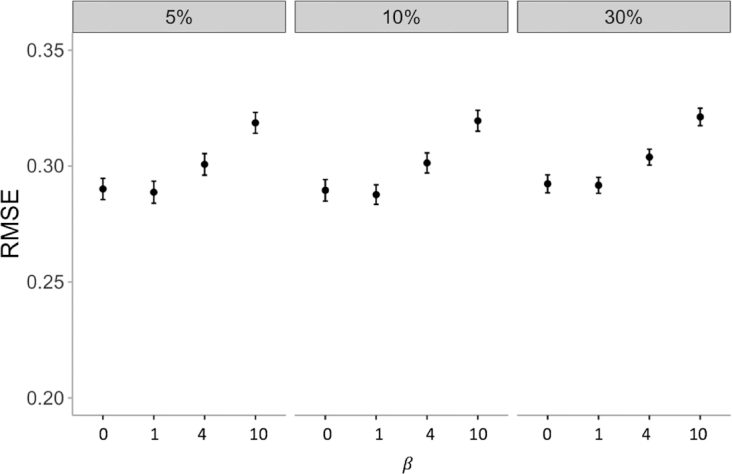
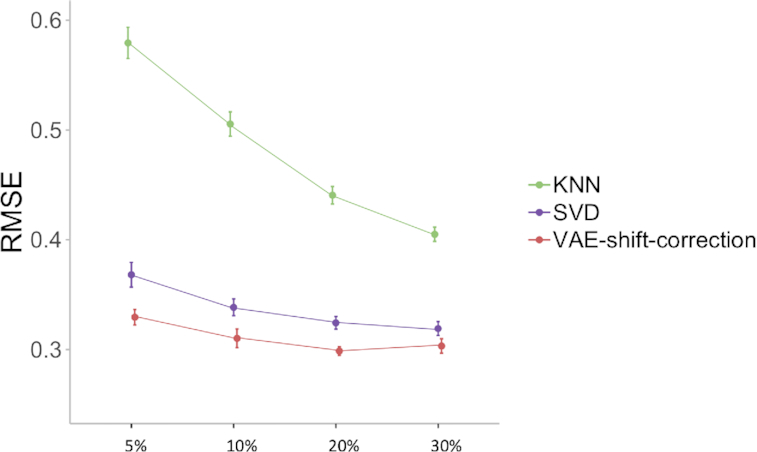
In this work, we use a deep-learning framework based on the variational auto-encoder (VAE) for genomic missing value imputation and demonstrate its effectiveness in transcriptome and methylome data analysis. We show that in the vast majority of our testing scenarios, VAE achieves similar or better performances than the most widely used imputation standards, while having a computational advantage at evaluation time. When dealing with data missing not at random (e.g., few values are missing), we develop simple yet effective methodologies to leverage the prior knowledge about missing data. Furthermore, we investigate the effect of varying latent space regularization strength in VAE on the imputation performances and, in this context, show why VAE has a better imputation capacity compared to a regular deterministic auto-encoder.
We describe a deep learning imputation framework for transcriptome and methylome data using a VAE and show that it can be a preferable alternative to traditional methods for data imputation, especially in the setting of large-scale data and certain missing-not-at-random scenarios.
由于基因组数据中经常存在缺失值,因此对于需要完整数据集的下游分析,需要实用的方法来处理缺失数据。最先进的缺失值插补技术,包括基于奇异值分解和 K-最近邻的方法,对于大型数据集来说计算成本很高,并且很难修改这些算法来处理某些非随机缺失的情况。
在这项工作中,我们使用基于变分自动编码器(VAE)的深度学习框架进行基因组缺失值插补,并证明其在转录组和甲基组数据分析中的有效性。我们表明,在绝大多数测试场景中,VAE 的性能与最广泛使用的插补标准相似或更好,而在评估时具有计算优势。当处理非随机缺失的数据(例如,少数值缺失)时,我们开发了简单而有效的方法来利用关于缺失数据的先验知识。此外,我们研究了 VAE 中潜在空间正则化强度对插补性能的影响,并在这种情况下,说明了为什么 VAE 比常规确定性自动编码器具有更好的插补能力。
我们描述了一种使用 VAE 的转录组和甲基组数据的深度学习插补框架,并表明它可以替代传统的数据插补方法,尤其是在大规模数据和某些非随机缺失情况下。