Little Damon P
Lewis B. and Dorothy Cullman Program for Molecular Systematics New York Botanical Garden Bronx New York 10458-5126 USA.
PhD Program in Plant Biology Graduate Center City University of New York New York New York 10016-4309 USA.
Appl Plant Sci. 2020 Jul 31;8(7):e11378. doi: 10.1002/aps3.11378. eCollection 2020 Jul.
The automated recognition of Latin scientific names within vernacular text has many applications, including text mining, search indexing, and automated specimen-label processing. Most published solutions are computationally inefficient, incapable of running within a web browser, and focus on texts in English, thus omitting a substantial portion of biodiversity literature.
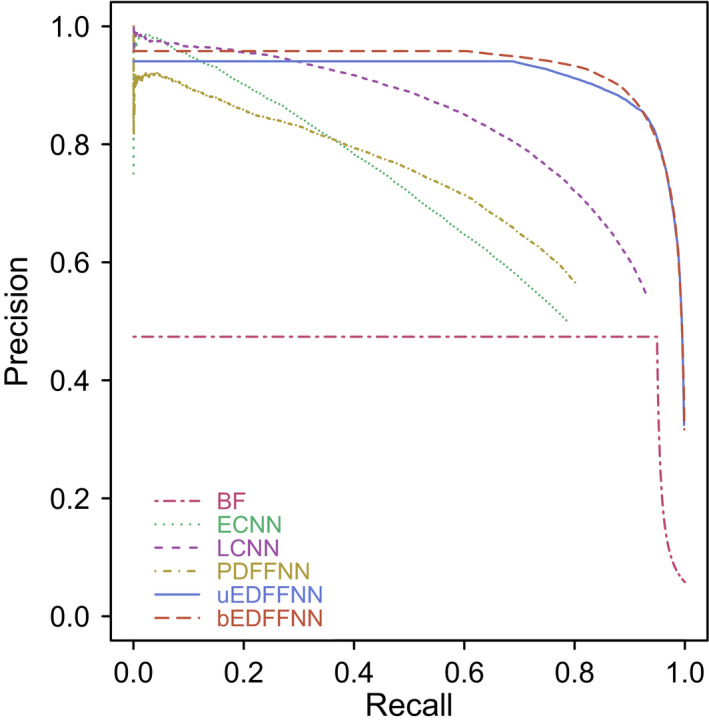
An open-source browser-executable solution, Quaesitor, is presented here. It uses pattern matching (regular expressions) in combination with an ensembled classifier composed of an inclusion dictionary search (Bloom filter), a trio of complementary neural networks that differ in their approach to encoding text, and word length to automatically identify Latin scientific names in the 16 most common languages for biodiversity articles.
In combination, the classifiers can recognize Latin scientific names in isolation or embedded within the languages used for >96% of biodiversity literature titles. For three different data sets, they resulted in a 0.80-0.97 recall and a 0.69-0.84 precision at a rate of 8.6 ms/word.
在白话文本中自动识别拉丁学名有许多应用,包括文本挖掘、搜索索引和自动标本标签处理。大多数已发表的解决方案计算效率低下,无法在网络浏览器中运行,并且专注于英文文本,从而遗漏了很大一部分生物多样性文献。
本文介绍了一种开源的浏览器可执行解决方案Quaesitor。它使用模式匹配(正则表达式),并结合一个集成分类器,该分类器由包含字典搜索(布隆过滤器)、三个在文本编码方法上不同的互补神经网络以及单词长度组成,以自动识别生物多样性文章中16种最常用语言的拉丁学名。
这些分类器相结合,可以单独识别拉丁学名,也可以识别嵌入在超过96%的生物多样性文献标题所用语言中的拉丁学名。对于三个不同的数据集,它们在8.6毫秒/单词的速度下,召回率为0.80 - 0.97,精确率为0.69 - 0.84。