Kotwal Atul, Yadav Arun Kumar, Yadav Jyoti, Kotwal Jyoti, Khune Sudhir
MG (Med), South Western Command, C/o 56 APO, India.
Associate Professor, Department of Community Medicine, Armed Forces Medical College, Pune, India.
Med J Armed Forces India. 2020 Oct;76(4):377-386. doi: 10.1016/j.mjafi.2020.06.001. Epub 2020 Jun 17.
The mathematical modelling of coronavirus disease-19 (COVID-19) pandemic has been attempted by a wide range of researchers from the very beginning of cases in India. Initial analysis of available models revealed large variations in scope, assumptions, predictions, course, effect of interventions, effect on health-care services, and so on. Thus, a rapid review was conducted for narrative synthesis and to assess correlation between predicted and actual values of cases in India.
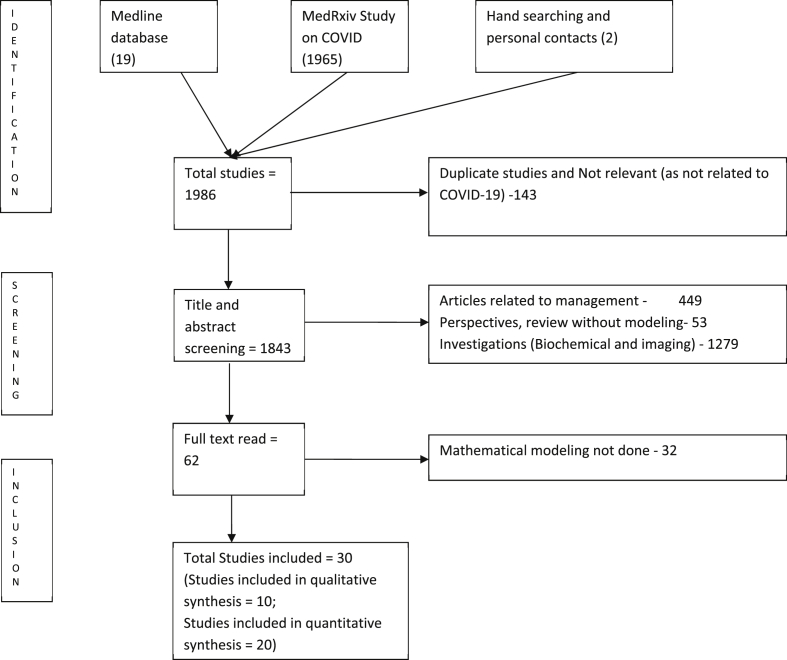
A comprehensive, two-step search strategy was adopted, wherein the databases such as Medline, google scholar, MedRxiv, and BioRxiv were searched. Later, hand searching for the articles and contacting known modelers for unpublished models was resorted. The data from the included studies were extracted by the two investigators independently and checked by third researcher.
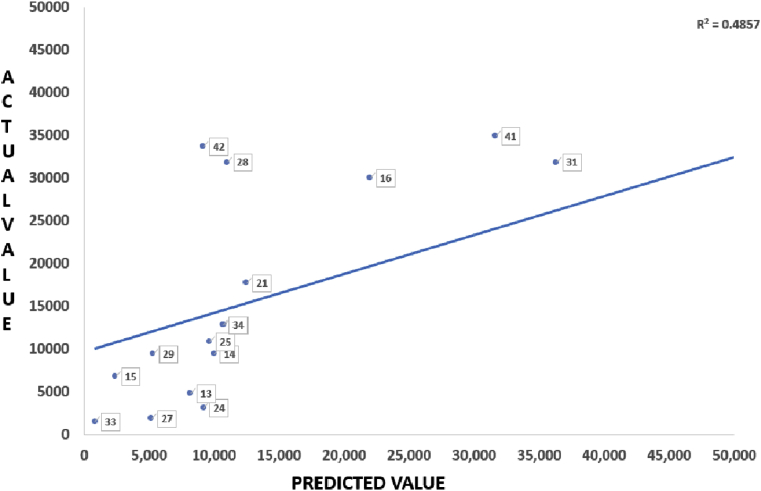
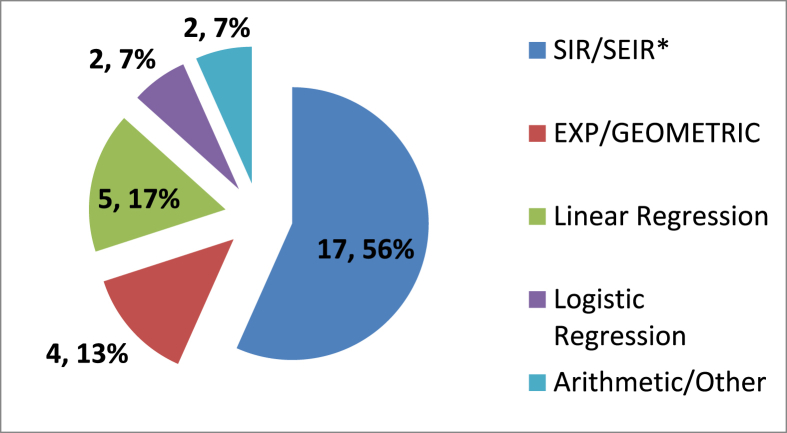
Based on the literature search, 30 articles were included in this review. As narrative synthesis, data from the studies were summarized in terms of assumptions, model used, predictions, main recommendations, and findings. The Pearson's correlation coefficient (r) between predicted and actual values (n = 20) was 0.7 (p = 0.002) with R2 = 0.49. For Susceptible, Infected, Recovered (SIR) and its variant models (n = 16) 'r' was 0.65 (p = 0.02). The correlation for long-term predictions could not be assessed due to paucity of information.
Review has shown the importance of assumptions and strong correlation between short-term projections but uncertainties for long-term predictions. Thus, short-term predictions may be revised as more and more data become available. The assumptions too need to expand and firm up as the pandemic evolves.
自印度出现新冠疫情病例之初,众多研究人员就已尝试对2019冠状病毒病(COVID - 19)大流行进行数学建模。对现有模型的初步分析显示,在范围、假设、预测、病程、干预措施的效果、对医疗服务的影响等方面存在很大差异。因此,开展了一项快速综述,以进行叙述性综合分析,并评估印度病例预测值与实际值之间的相关性。
采用了全面的两步搜索策略,即搜索Medline、谷歌学术、MedRxiv和BioRxiv等数据库。随后,通过手工检索文章并联系已知的建模人员以获取未发表的模型。纳入研究的数据由两名研究人员独立提取,并由第三名研究人员进行核对。
基于文献检索,本综述纳入了30篇文章。作为叙述性综合分析,研究数据从假设、使用的模型、预测、主要建议和研究结果等方面进行了总结。预测值与实际值(n = 20)之间的皮尔逊相关系数(r)为0.7(p = 0.002),R² = 0.49。对于易感者、感染者、康复者(SIR)及其变体模型(n = 16),“r”为0.65(p = 0.02)。由于信息匮乏,无法评估长期预测的相关性。
综述表明了假设的重要性以及短期预测之间的强相关性,但长期预测存在不确定性。因此,随着越来越多的数据可用,短期预测可能需要修订。随着疫情的发展,假设也需要扩展和完善。