Wang Luotong, Qu Li, Yang Longshu, Wang Yiying, Zhu Huaiqiu
State Key Laboratory for Turbulence and Complex Systems, Department of Biomedical Engineering, College of Engineering, Peking University, Beijing, China.
Department of Biomedical Engineering, Georgia Institute of Technology and Emory University, Atlanta, GA, United States.
Front Genet. 2020 Aug 12;11:900. doi: 10.3389/fgene.2020.00900. eCollection 2020.
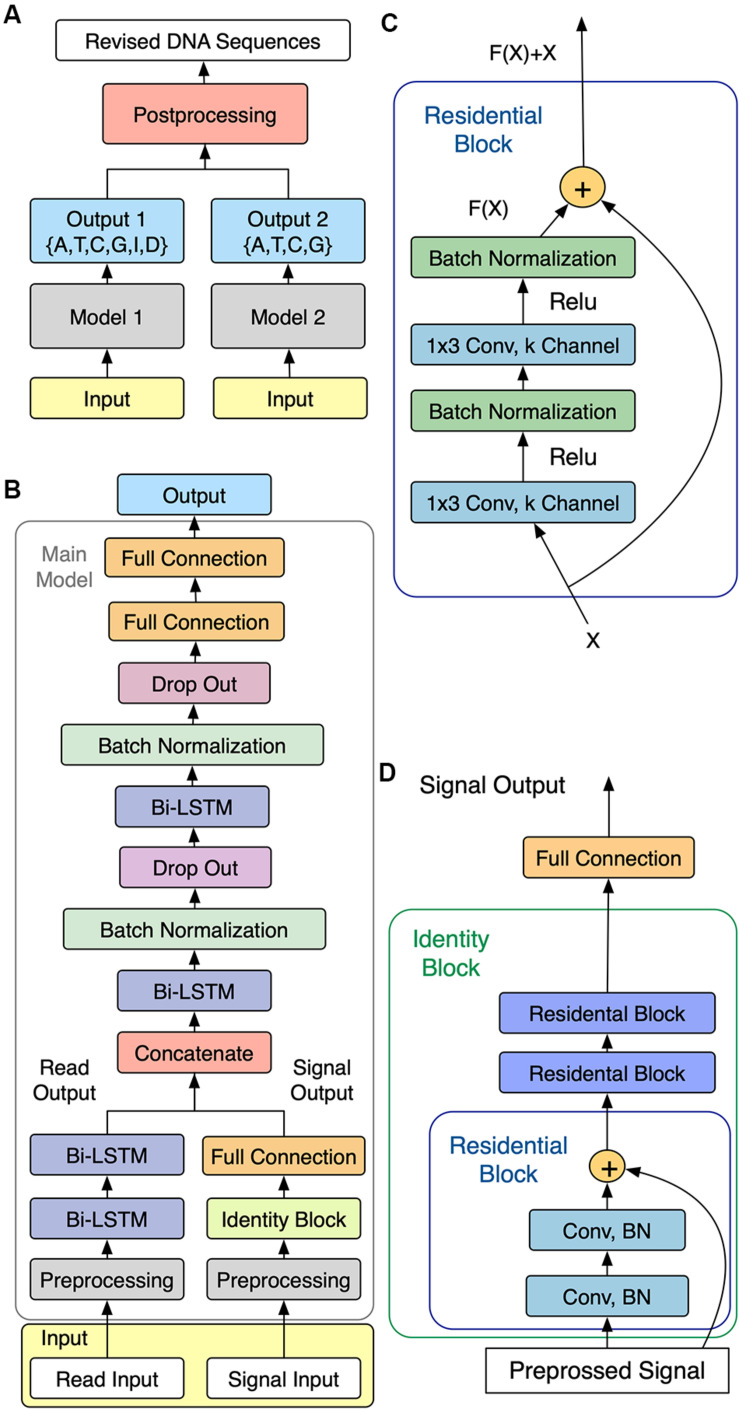
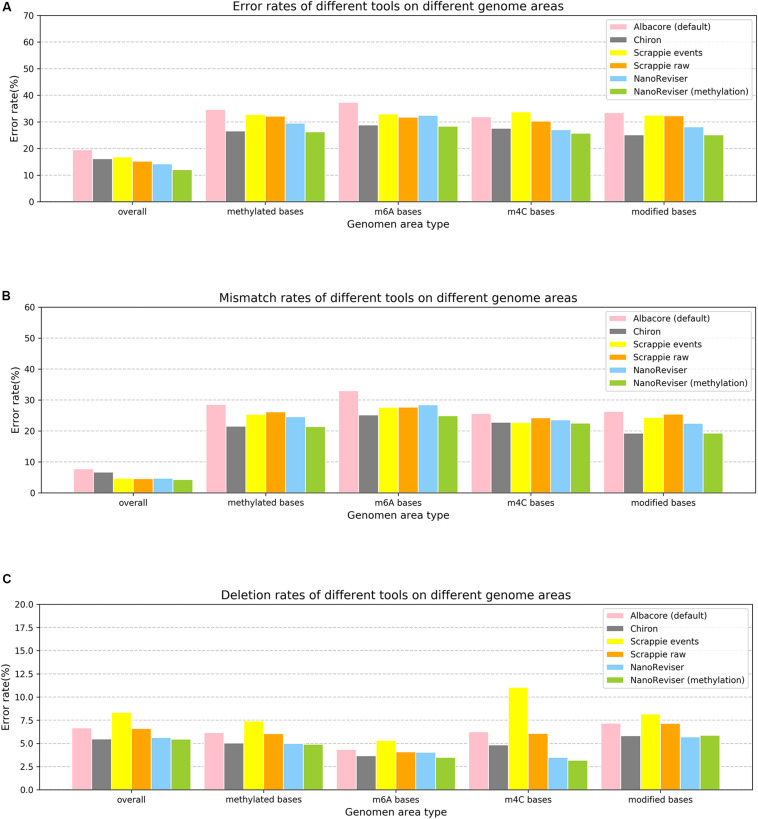
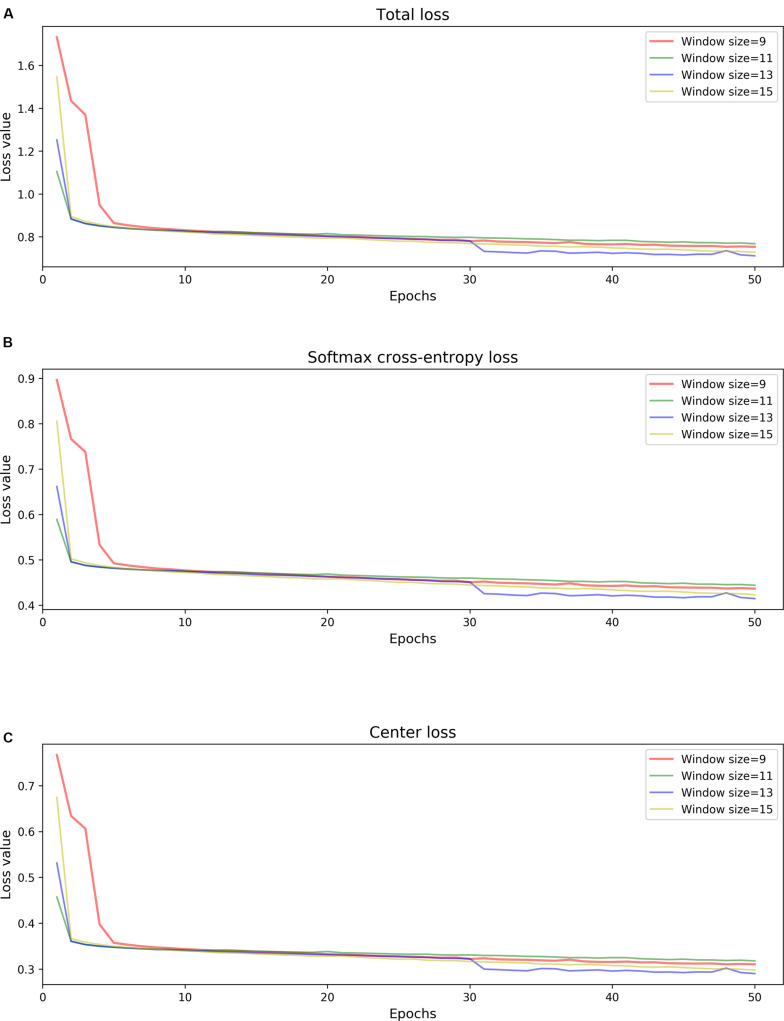
Nanopore sequencing is regarded as one of the most promising third-generation sequencing (TGS) technologies. Since 2014, Oxford Nanopore Technologies (ONT) has developed a series of devices based on nanopore sequencing to produce very long reads, with an expected impact on genomics. However, the nanopore sequencing reads are susceptible to a fairly high error rate owing to the difficulty in identifying the DNA bases from the complex electrical signals. Although several basecalling tools have been developed for nanopore sequencing over the past years, it is still challenging to correct the sequences after applying the basecalling procedure. In this study, we developed an open-source DNA basecalling reviser, NanoReviser, based on a deep learning algorithm to correct the basecalling errors introduced by current basecallers provided by default. In our module, we re-segmented the raw electrical signals based on the basecalled sequences provided by the default basecallers. By employing convolution neural networks (CNNs) and bidirectional long short-term memory (Bi-LSTM) networks, we took advantage of the information from the raw electrical signals and the basecalled sequences from the basecallers. Our results showed NanoReviser, as a post-basecalling reviser, significantly improving the basecalling quality. After being trained on standard ONT sequencing reads from public and human NA12878 datasets, NanoReviser reduced the sequencing error rate by over 5% for both the dataset and the human dataset. The performance of NanoReviser was found to be better than those of all current basecalling tools. Furthermore, we analyzed the modified bases of the dataset and added the methylation information to train our module. With the methylation annotation, NanoReviser reduced the error rate by 7% for the dataset and specifically reduced the error rate by over 10% for the regions of the sequence rich in methylated bases. To the best of our knowledge, NanoReviser is the first post-processing tool after basecalling to accurately correct the nanopore sequences without the time-consuming procedure of building the consensus sequence. The NanoReviser package is freely available at https://github.com/pkubioinformatics/NanoReviser.
纳米孔测序被视为最具前景的第三代测序(TGS)技术之一。自2014年以来,牛津纳米孔技术公司(ONT)已开发出一系列基于纳米孔测序的设备,以产生非常长的读段,有望对基因组学产生影响。然而,由于难以从复杂的电信号中识别DNA碱基,纳米孔测序读段容易出现相当高的错误率。尽管在过去几年中已经为纳米孔测序开发了几种碱基识别工具,但在应用碱基识别程序后校正序列仍然具有挑战性。在本研究中,我们基于深度学习算法开发了一个开源的DNA碱基识别校正器NanoReviser,以校正默认提供的当前碱基识别器引入的碱基识别错误。在我们的模块中,我们根据默认碱基识别器提供的碱基识别序列对原始电信号进行重新分割。通过使用卷积神经网络(CNN)和双向长短期记忆(Bi-LSTM)网络,我们利用了原始电信号和碱基识别器的碱基识别序列中的信息。我们的结果表明,作为一种碱基识别后校正器,NanoReviser显著提高了碱基识别质量。在使用来自公共和人类NA12878数据集的标准ONT测序读段进行训练后,NanoReviser将数据集和人类数据集的测序错误率均降低了5%以上。发现NanoReviser的性能优于所有当前的碱基识别工具。此外,我们分析了数据集的修饰碱基,并添加甲基化信息来训练我们的模块。通过甲基化注释,NanoReviser将数据集的错误率降低了7%,并特别将富含甲基化碱基的序列区域的错误率降低了10%以上。据我们所知,NanoReviser是碱基识别后的第一个后处理工具,无需构建一致序列的耗时过程即可准确校正纳米孔序列。NanoReviser软件包可在https://github.com/pkubioinformatics/NanoReviser上免费获取。