Advanced Analytics Institute, Faculty of Engineering and Information Technology, University of Technology Sydney, PO Box 123, Broadway, Sydney, NSW 2007, Australia.
Data Science Institute, University of Technology Sydney, PO Box 123, Broadway, Sydney, NSW 2007, Australia.
BMC Genomics. 2020 Sep 11;21(1):627. doi: 10.1186/s12864-020-07033-8.
DNA N4-methylcytosine (4mC) is a critical epigenetic modification and has various roles in the restriction-modification system. Due to the high cost of experimental laboratory detection, computational methods using sequence characteristics and machine learning algorithms have been explored to identify 4mC sites from DNA sequences. However, state-of-the-art methods have limited performance because of the lack of effective sequence features and the ad hoc choice of learning algorithms to cope with this problem. This paper is aimed to propose new sequence feature space and a machine learning algorithm with feature selection scheme to address the problem.
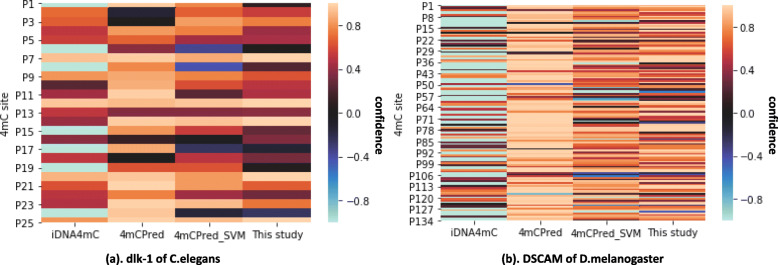
The feature importance score distributions in datasets of six species are firstly reported and analyzed. Then the impact of the feature selection on model performance is evaluated by independent testing on benchmark datasets, where ACC and MCC measurements on the performance after feature selection increase by 2.3% to 9.7% and 0.05 to 0.19, respectively. The proposed method is compared with three state-of-the-art predictors using independent test and 10-fold cross-validations, and our method outperforms in all datasets, especially improving the ACC by 3.02% to 7.89% and MCC by 0.06 to 0.15 in the independent test. Two detailed case studies by the proposed method have confirmed the excellent overall performance and correctly identified 24 of 26 4mC sites from the C.elegans gene, and 126 out of 137 4mC sites from the D.melanogaster gene.
The results show that the proposed feature space and learning algorithm with feature selection can improve the performance of DNA 4mC prediction on the benchmark datasets. The two case studies prove the effectiveness of our method in practical situations.
DNA N4-甲基胞嘧啶(4mC)是一种关键的表观遗传修饰,在限制修饰系统中具有多种功能。由于实验实验室检测成本高昂,因此已经探索了使用序列特征和机器学习算法的计算方法,以便从 DNA 序列中识别 4mC 位点。然而,由于缺乏有效的序列特征和专门选择的学习算法来应对这个问题,最先进的方法的性能受到限制。本文旨在提出新的序列特征空间和机器学习算法以及特征选择方案来解决这个问题。
首先报告和分析了六个物种数据集的特征重要性得分分布。然后,通过在基准数据集上进行独立测试来评估特征选择对模型性能的影响,其中选择特征后的 ACC 和 MCC 测量值分别提高了 2.3%至 9.7%和 0.05 至 0.19。通过独立测试和 10 折交叉验证,将所提出的方法与三种最先进的预测器进行了比较,在所有数据集上都表现出色,特别是在独立测试中,ACC 提高了 3.02%至 7.89%,MCC 提高了 0.06 至 0.15。通过所提出的方法进行的两个详细案例研究证实了其出色的整体性能,并正确识别了来自 C.elegans 基因的 26 个 4mC 位点中的 24 个,以及来自 D.melanogaster 基因的 137 个 4mC 位点中的 126 个。
结果表明,所提出的特征空间和具有特征选择的学习算法可以提高基准数据集上的 DNA 4mC 预测性能。两个案例研究证明了我们的方法在实际情况下的有效性。