Department of Computer Sciences, Bahria University Lahore Campus, Lahore, 25000, Pakistan.
University of Management and Technology, Lahore, 25000, Pakistan.
Sci Rep. 2020 Oct 9;10(1):16913. doi: 10.1038/s41598-020-73107-y.
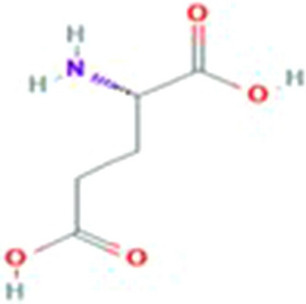
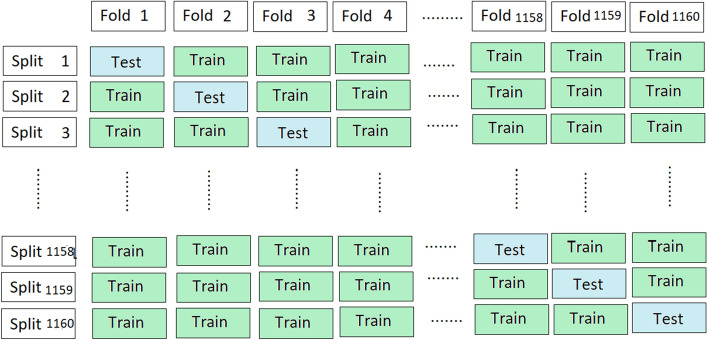
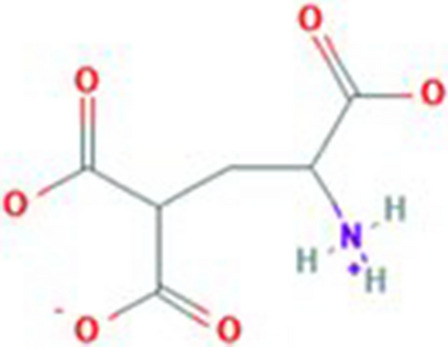
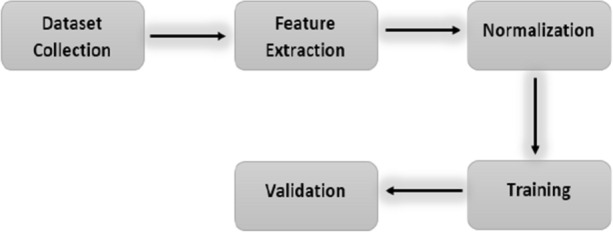
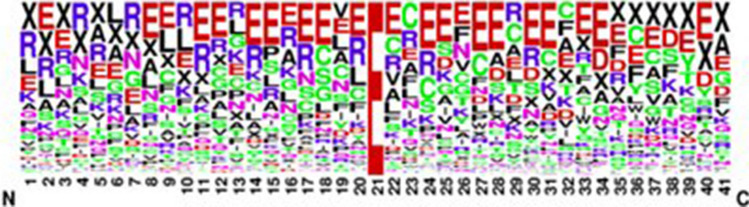
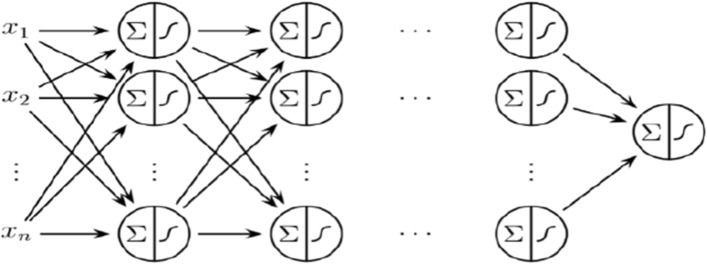
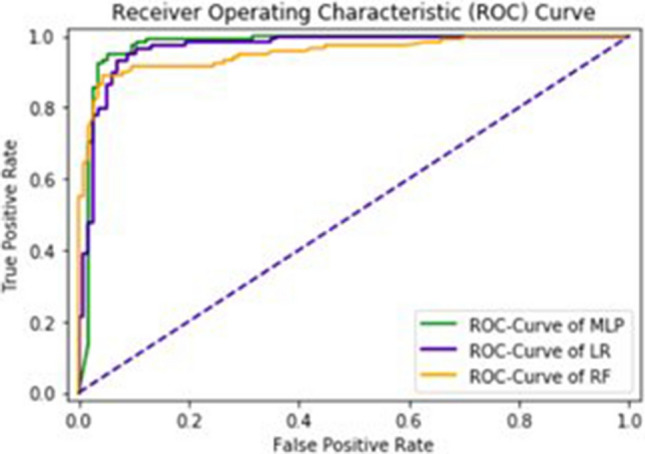
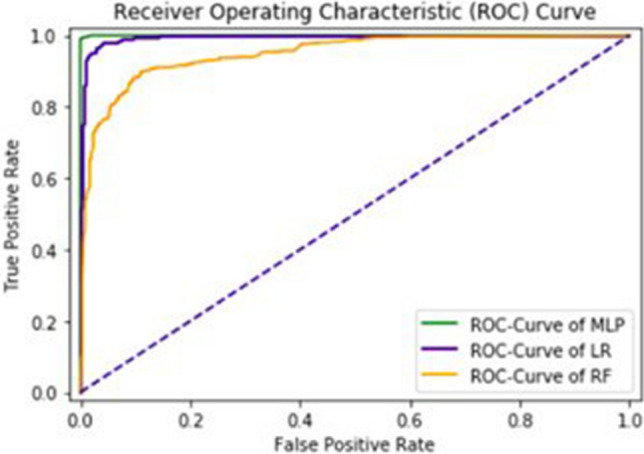
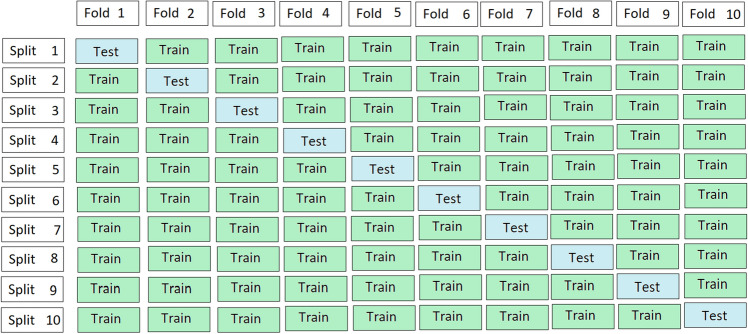
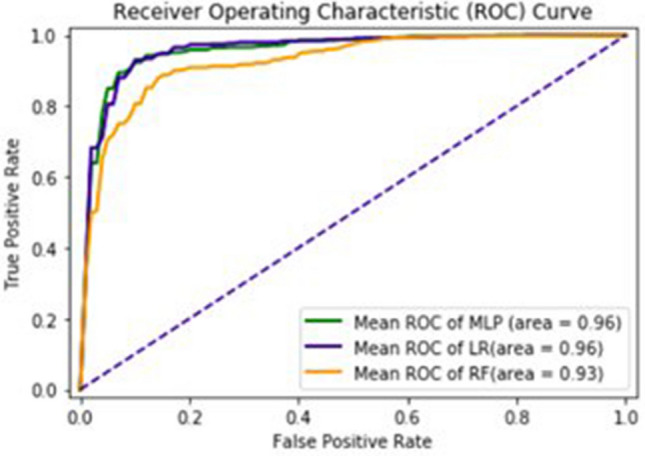
Glutamic acid is an alpha-amino acid used by all living beings in protein biosynthesis. One of the important glutamic acid modifications is post-translationally modified 4-carboxyglutamate. It has a significant role in blood coagulation. 4-carboxyglumates are required for the binding of calcium ions. On the contrary, this modification can also cause different diseases such as bone resorption, osteoporosis, papilloma, and plaque atherosclerosis. Considering its importance, it is necessary to predict the occurrence of glutamic acid carboxylation in amino acid stretches. As there is no computational based prediction model available to identify 4-carboxyglutamate modification, this study is, therefore, designed to predict 4-carboxyglutamate sites with a less computational cost. A machine learning model is devised with a Multilayered Perceptron (MLP) classifier using Chou's 5-step rule. It may help in learning statistical moments and based on this learning, the prediction is to be made accurately either it is 4-carboxyglutamate residue site or detected residue site having no 4-carboxyglutamate. Prediction accuracy of the proposed model is 94% using an independent set test, while obtained prediction accuracy is 99% by self-consistency tests.
谷氨酸是一种在蛋白质生物合成中被所有生物使用的α-氨基酸。谷氨酸的一个重要修饰是翻译后修饰的 4-羧基谷氨酸。它在血液凝固中起着重要作用。4-羧基谷氨酸是结合钙离子所必需的。相反,这种修饰也会导致不同的疾病,如骨吸收、骨质疏松症、乳头瘤和斑块动脉粥样硬化。考虑到它的重要性,有必要预测氨基酸序列中谷氨酸的羧化发生情况。由于目前还没有基于计算的预测模型来识别 4-羧基谷氨酸的修饰,因此本研究旨在设计一种计算成本较低的预测 4-羧基谷氨酸位点的方法。该研究使用多层感知器(MLP)分类器设计了一个机器学习模型,该模型使用了 Chou 的 5 步规则。它可以帮助学习统计矩,并在此基础上进行准确的预测,无论是 4-羧基谷氨酸残基位点还是检测到的没有 4-羧基谷氨酸的残基位点。使用独立数据集测试,所提出的模型的预测准确性为 94%,而通过自一致性测试获得的预测准确性为 99%。