Laboratory of Epidemiology and Biostatistics, National Institute of Gastroenterology, "S de Bellis" Research Hospital, Castellana Grotte, Bari, Italy.
Laboratory of Nutritional Biochemistry, National Institute of Gastroenterology, "S de Bellis" Research Hospital, Castellana Grotte, Bari, Italy.
PLoS One. 2020 Oct 20;15(10):e0240867. doi: 10.1371/journal.pone.0240867. eCollection 2020.
BACKGROUND & AIMS: Liver ultrasound scan (US) use in diagnosing Non-Alcoholic Fatty Liver Disease (NAFLD) causes costs and waiting lists overloads. We aimed to compare various Machine learning algorithms with a Meta learner approach to find the best of these as a predictor of NAFLD.
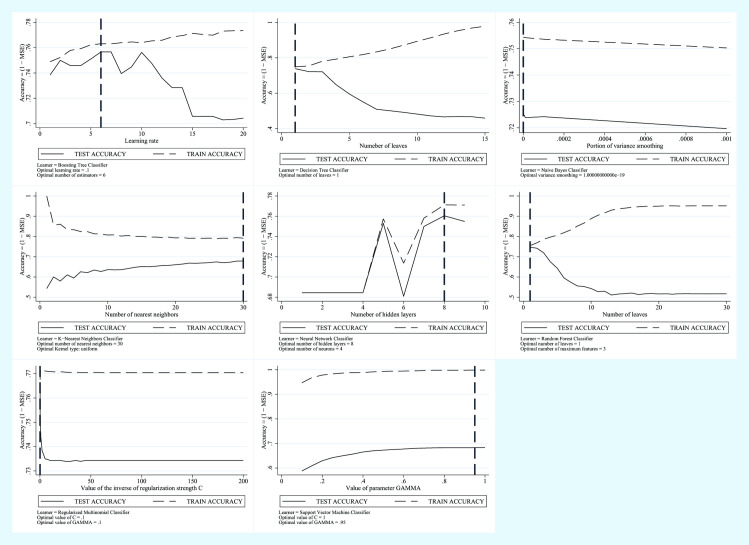
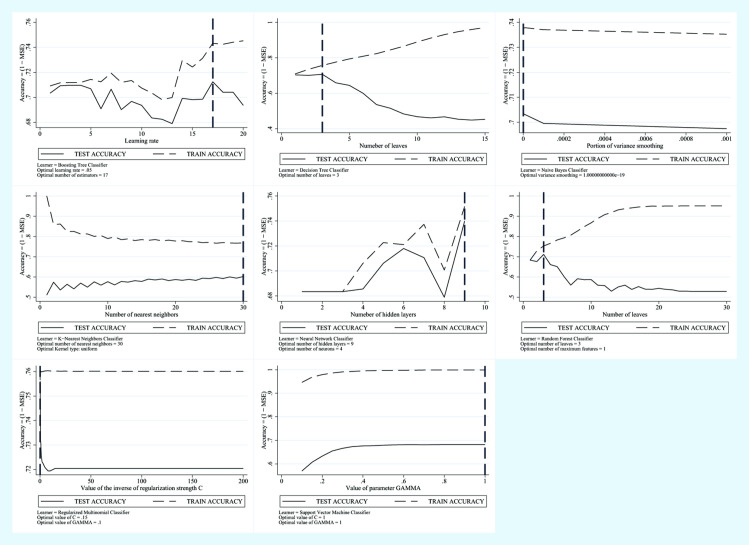
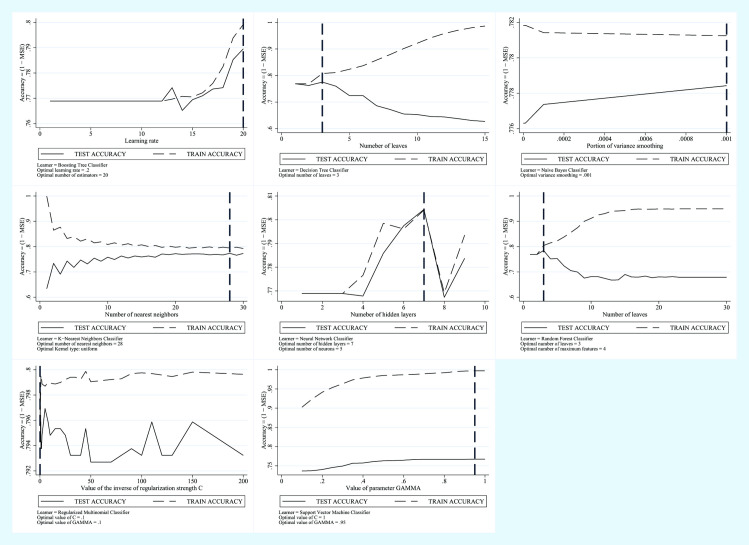
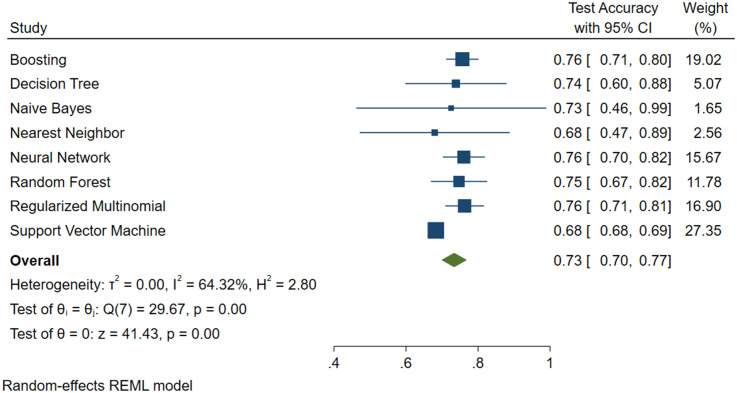
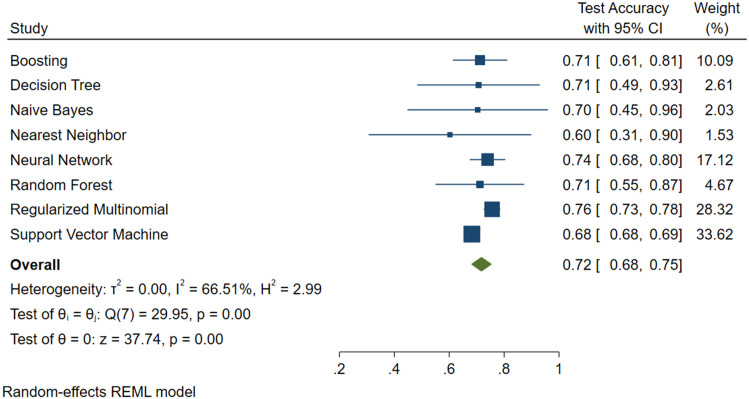
The study included 2970 subjects, 2920 constituting the training set and 50, randomly selected, used in the test phase, performing cross-validation. The best predictors were combined to create three models: 1) FLI plus GLUCOSE plus SEX plus AGE, 2) AVI plus GLUCOSE plus GGT plus SEX plus AGE, 3) BRI plus GLUCOSE plus GGT plus SEX plus AGE. Eight machine learning algorithms were trained with the predictors of each of the three models created. For these algorithms, the percent accuracy, variance and percent weight were compared.
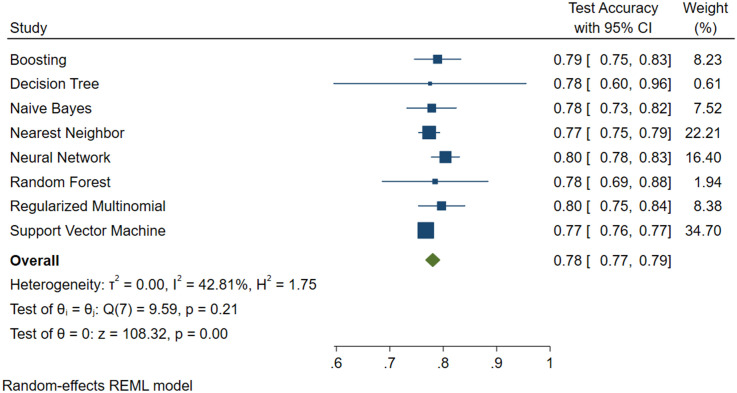
The SVM algorithm performed better with all models. Model 1 had 68% accuracy, with 1% variance and an algorithm weight of 27.35; Model 2 had 68% accuracy, with 1% variance and an algorithm weight of 33.62 and Model 3 had 77% accuracy, with 1% variance and an algorithm weight of 34.70. Model 2 was the most performing, composed of AVI plus GLUCOSE plus GGT plus SEX plus AGE, despite a lower percentage of accuracy.
A Machine Learning approach can support NAFLD diagnosis and reduce health costs. The SVM algorithm is easy to apply and the necessary parameters are easily retrieved in databases.
肝脏超声扫描(US)用于诊断非酒精性脂肪性肝病(NAFLD)会导致成本增加和候诊名单过载。我们旨在比较各种机器学习算法与元学习方法,以找到最佳方法作为 NAFLD 的预测指标。
该研究纳入了 2970 名受试者,其中 2920 名构成训练集,50 名随机选择的受试者用于测试阶段,进行交叉验证。最佳预测因子被组合成三个模型:1)FLI 加 GLUCOSE 加 SEX 加 AGE,2)AVI 加 GLUCOSE 加 GGT 加 SEX 加 AGE,3)BRI 加 GLUCOSE 加 GGT 加 SEX 加 AGE。八种机器学习算法分别使用三个模型中的预测因子进行训练。对于这些算法,比较了准确率、方差和权重百分比。
SVM 算法在所有模型中表现更好。模型 1 的准确率为 68%,方差为 1%,算法权重为 27.35;模型 2 的准确率为 68%,方差为 1%,算法权重为 33.62;模型 3 的准确率为 77%,方差为 1%,算法权重为 34.70。尽管模型 2 的准确率略低,但它由 AVI 加 GLUCOSE 加 GGT 加 SEX 加 AGE 组成,是表现最佳的模型。
机器学习方法可以支持 NAFLD 的诊断并降低医疗成本。SVM 算法易于应用,所需参数在数据库中易于检索。