Kang Hongyu, Li Jiao, Wu Meng, Shen Liu, Hou Li
Institute of Medical Information &Library, Chinese Academy of Medical Sciences/Peking Union Medical College, Beijing, China.
Department of Biomedical Engineering, School of Life Science, Beijing Institute of Technology, Beijing, China.
JMIR Med Inform. 2020 Oct 21;8(10):e20291. doi: 10.2196/20291.
Many drugs do not work the same way for everyone owing to distinctions in their genes. Pharmacogenomics (PGx) aims to understand how genetic variants influence drug efficacy and toxicity. It is often considered one of the most actionable areas of the personalized medicine paradigm. However, little prior work has included in-depth explorations and descriptions of drug usage, dosage adjustment, and so on.
We present a pharmacogenomics knowledge model to discover the hidden relationships between PGx entities such as drugs, genes, and diseases, especially details in precise medication.
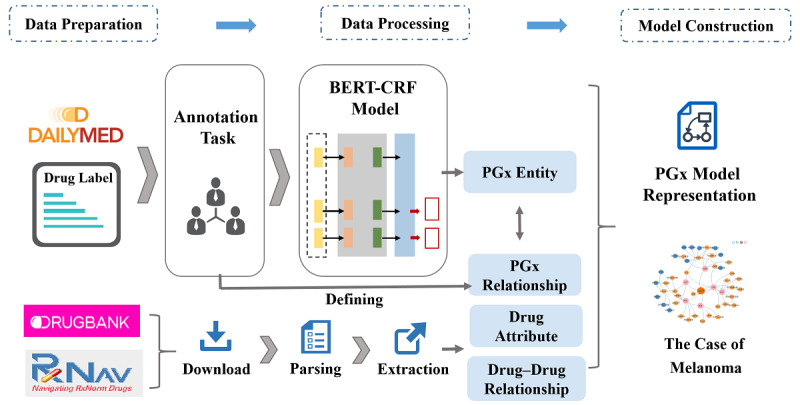
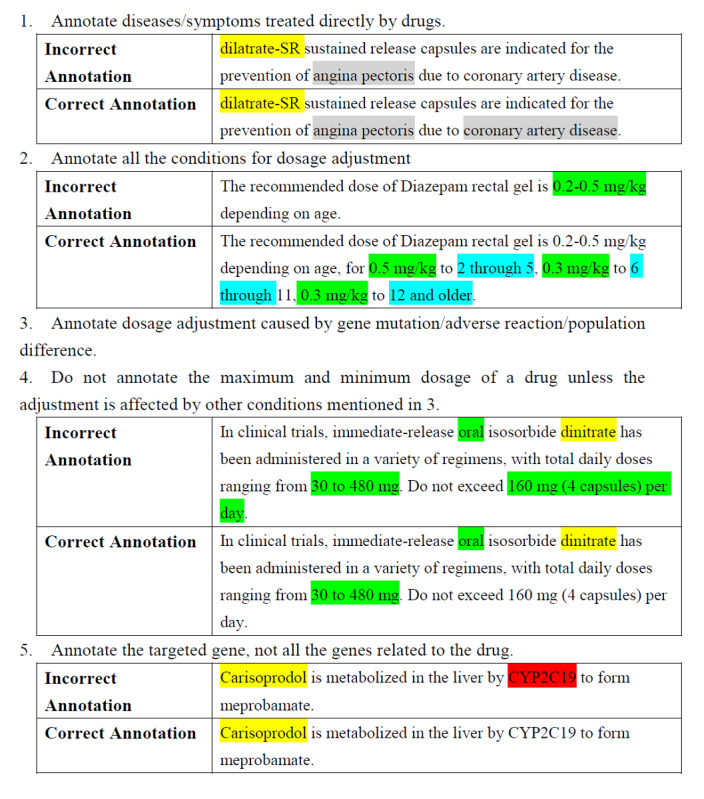
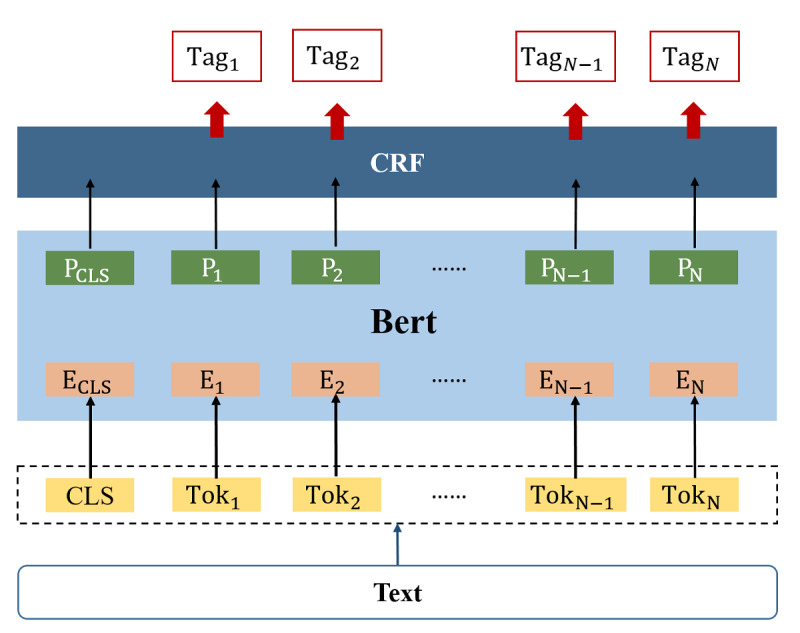
PGx open data such as DrugBank and RxNorm were integrated in this study, as well as drug labels published by the US Food and Drug Administration. We annotated 190 drug labels manually for entities and relationships. Based on the annotation results, we trained 3 different natural language processing models to complete entity recognition. Finally, the pharmacogenomics knowledge model was described in detail.
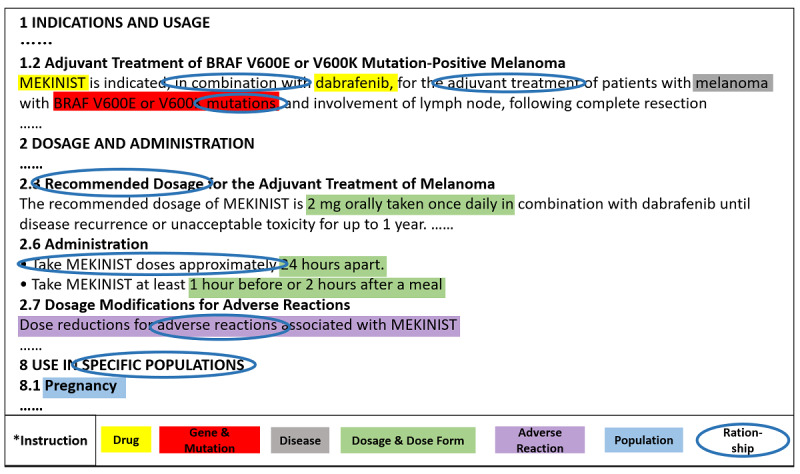
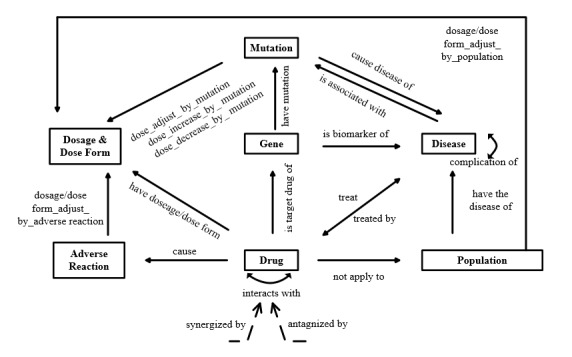
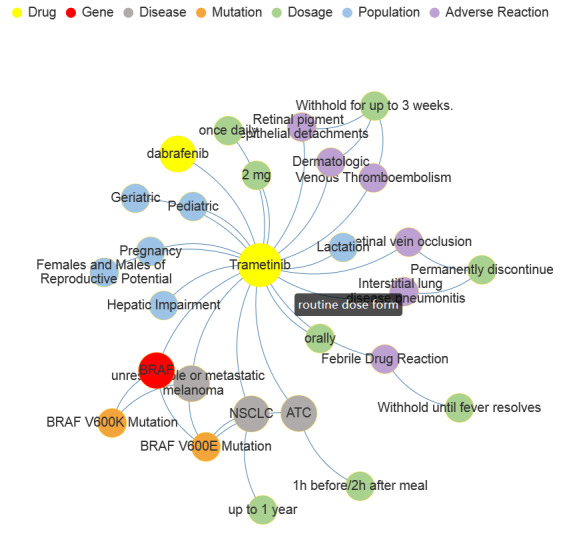
In entity recognition tasks, the Bidirectional Encoder Representations from Transformers-conditional random field model achieved better performance with micro-F1 score of 85.12%. The pharmacogenomics knowledge model in our study included 5 semantic types: drug, gene, disease, precise medication (population, daily dose, dose form, frequency, etc), and adverse reaction. Meanwhile, 26 semantic relationships were defined in detail. Taking melanoma caused by a BRAF gene mutation into consideration, the pharmacogenomics knowledge model covered 7 related drugs and 4846 triples were established in this case. All the corpora, relationship definitions, and triples were made publically available.
We highlighted the pharmacogenomics knowledge model as a scalable framework for clinicians and clinical pharmacists to adjust drug dosage according to patient-specific genetic variation, and for pharmaceutical researchers to develop new drugs. In the future, a series of other antitumor drugs and automatic relation extractions will be taken into consideration to further enhance our framework with more PGx linked data.
由于基因差异,许多药物对每个人的作用方式并不相同。药物基因组学(PGx)旨在了解基因变异如何影响药物疗效和毒性。它通常被认为是个性化医疗范式中最具可操作性的领域之一。然而,此前很少有研究对药物使用、剂量调整等进行深入探索和描述。
我们提出一种药物基因组学知识模型,以发现药物、基因和疾病等PGx实体之间隐藏的关系,特别是精准用药方面的细节。
本研究整合了DrugBank和RxNorm等PGx开放数据,以及美国食品药品监督管理局发布的药品标签。我们手动为190个药品标签标注了实体和关系。基于标注结果,我们训练了3种不同的自然语言处理模型来完成实体识别。最后,详细描述了药物基因组学知识模型。
在实体识别任务中,基于变换器的双向编码器表征-条件随机场模型表现更佳,微F1分数达到85.12%。我们研究中的药物基因组学知识模型包括5种语义类型:药物、基因、疾病、精准用药(人群、每日剂量、剂型、用药频率等)和不良反应。同时,详细定义了26种语义关系。以BRAF基因突变引起的黑色素瘤为例,药物基因组学知识模型涵盖了7种相关药物,并在此案例中建立了4846个三元组。所有语料库、关系定义和三元组均已公开。
我们强调药物基因组学知识模型是一个可扩展的框架,可供临床医生和临床药剂师根据患者特定的基因变异调整药物剂量,也可供药物研究人员开发新药。未来,将考虑一系列其他抗肿瘤药物和自动关系提取,以利用更多PGx链接数据进一步增强我们的框架。