Department of Mathematics, Washington State University, Vancouver, WA, 98686.
Department of Otolaryngology, Oregon Health and Science University, Portland, OR, 97239
eNeuro. 2020 Nov 13;7(6). doi: 10.1523/ENEURO.0205-20.2020. Print 2020 Nov/Dec.
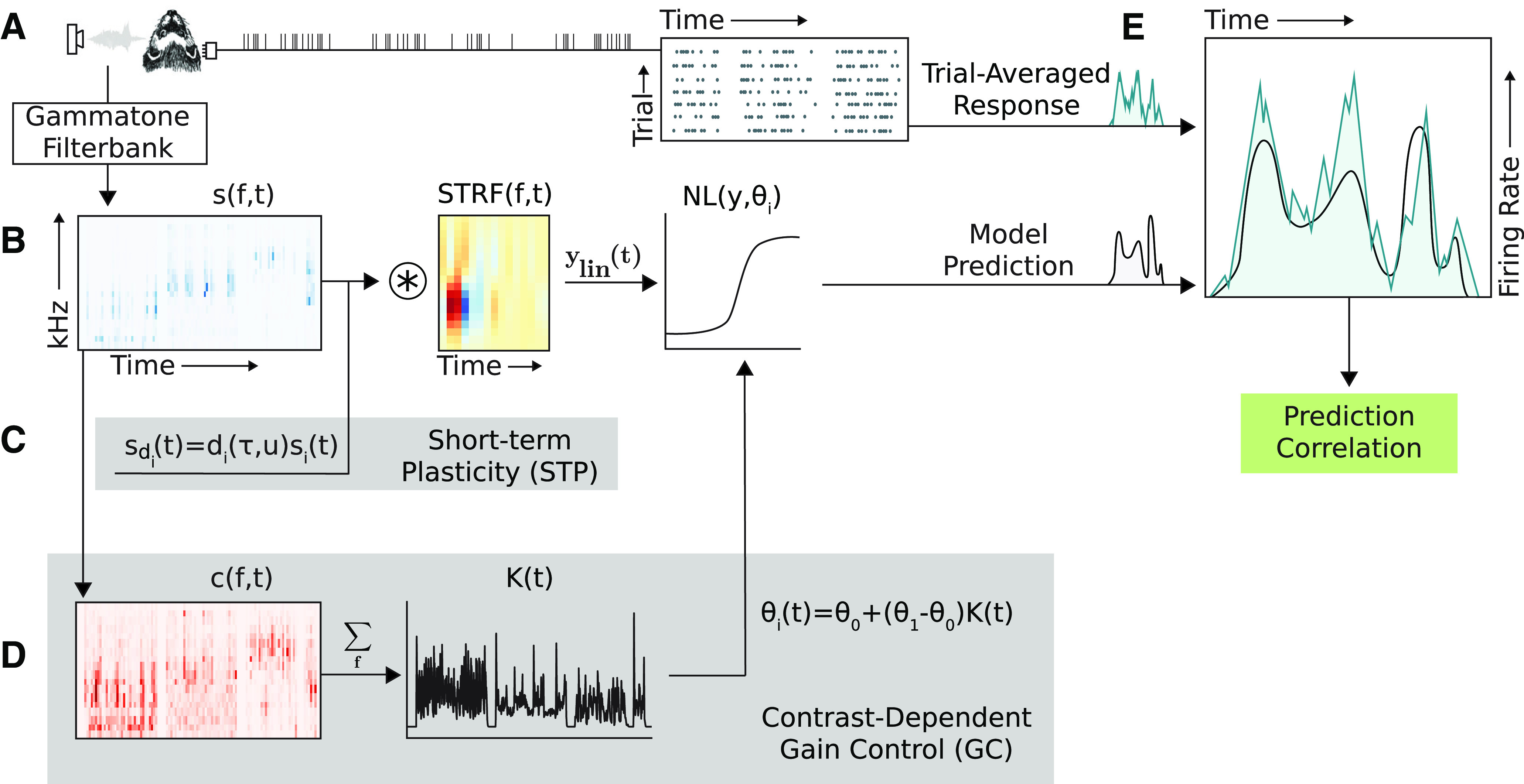
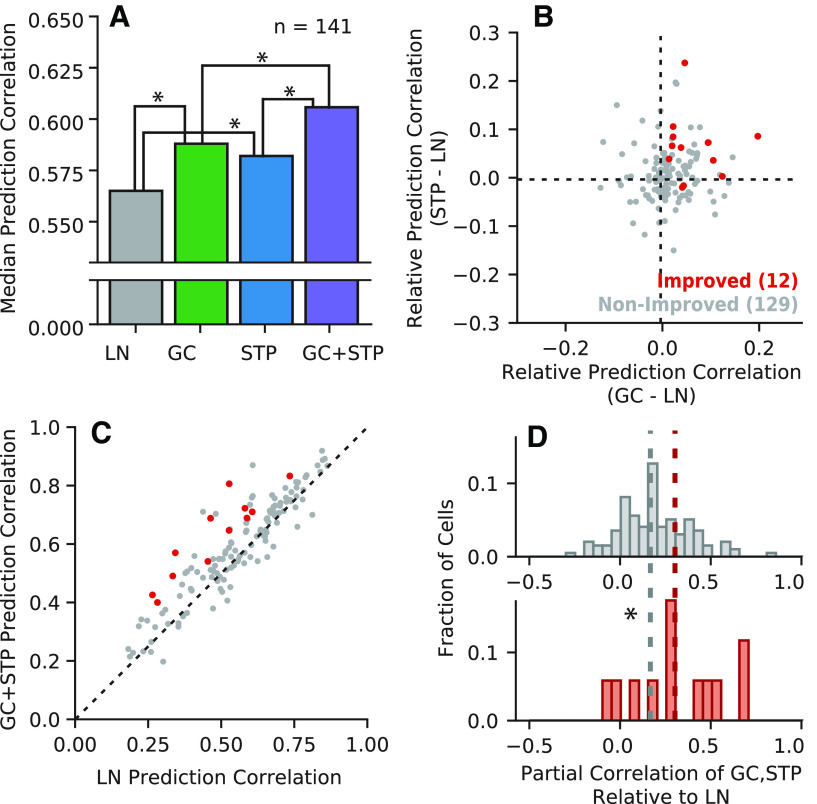
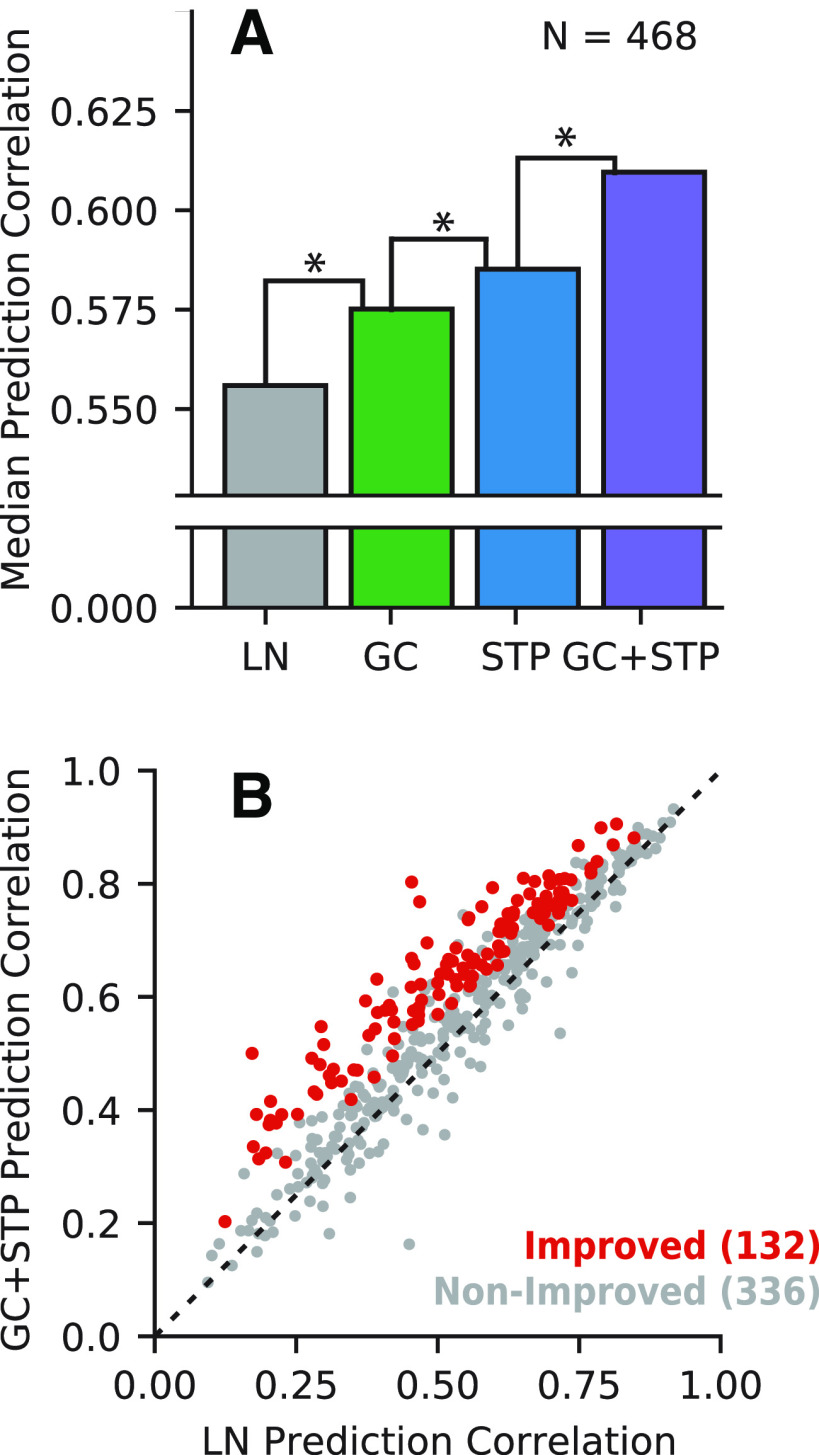
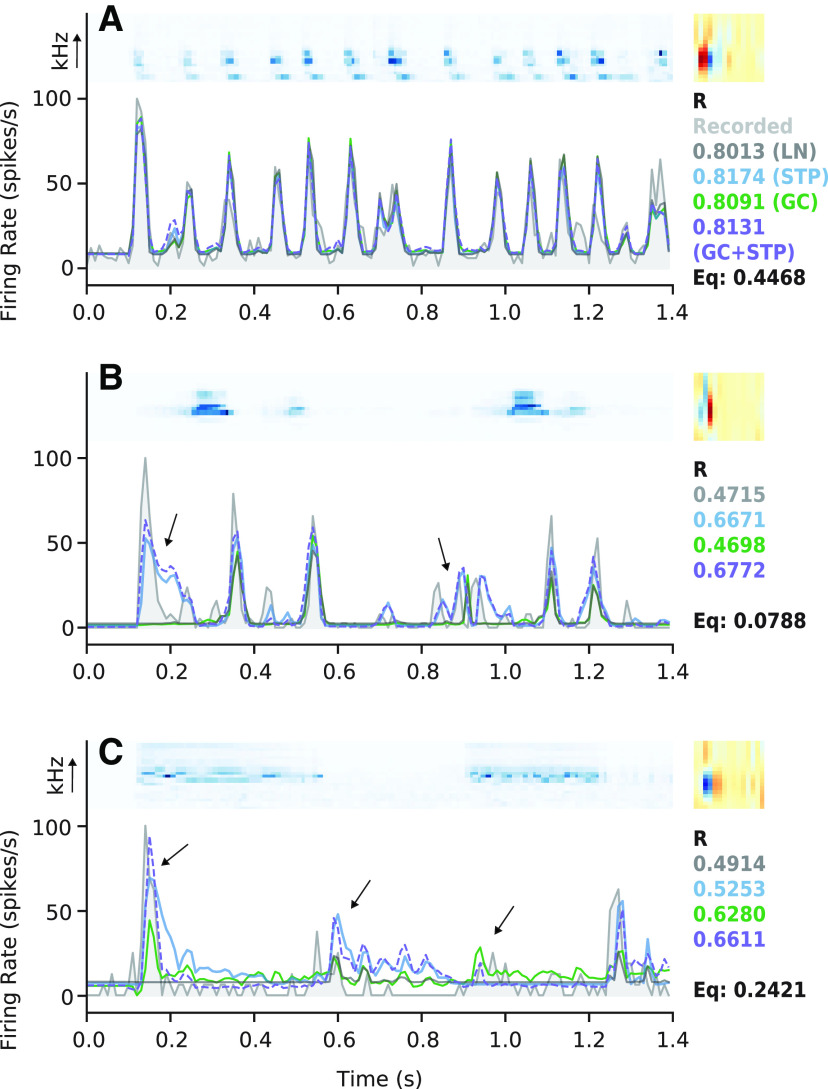
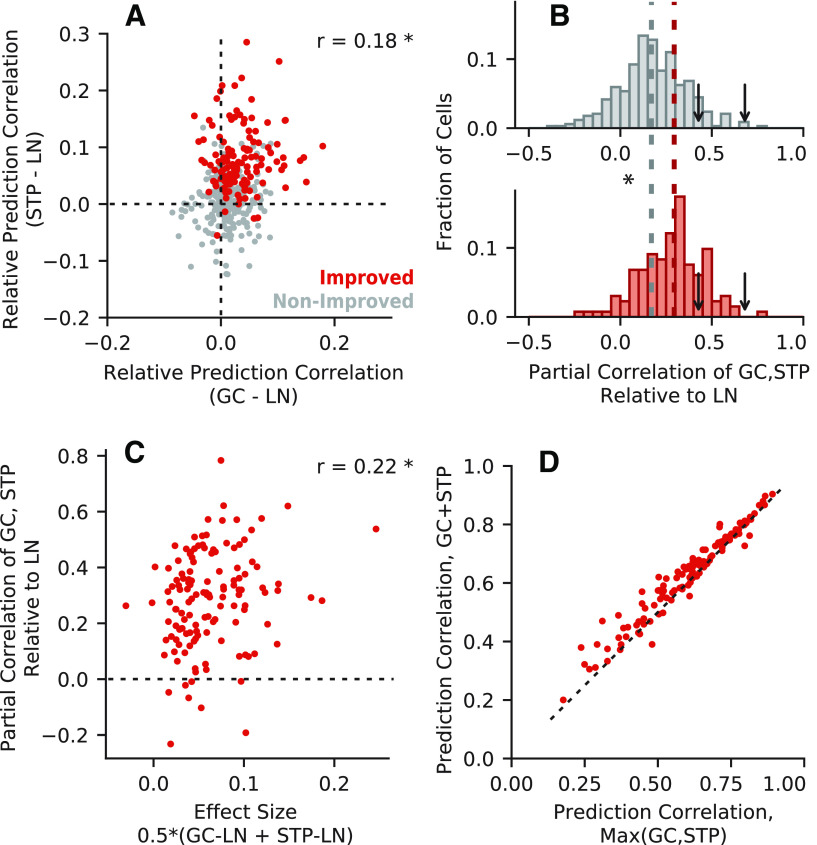
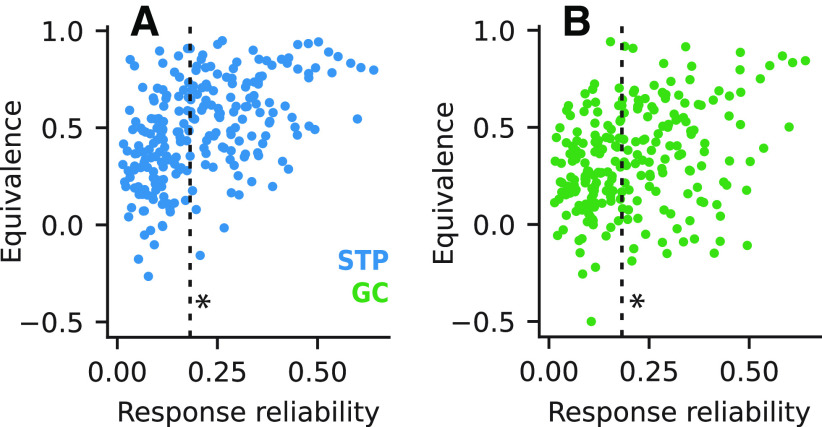
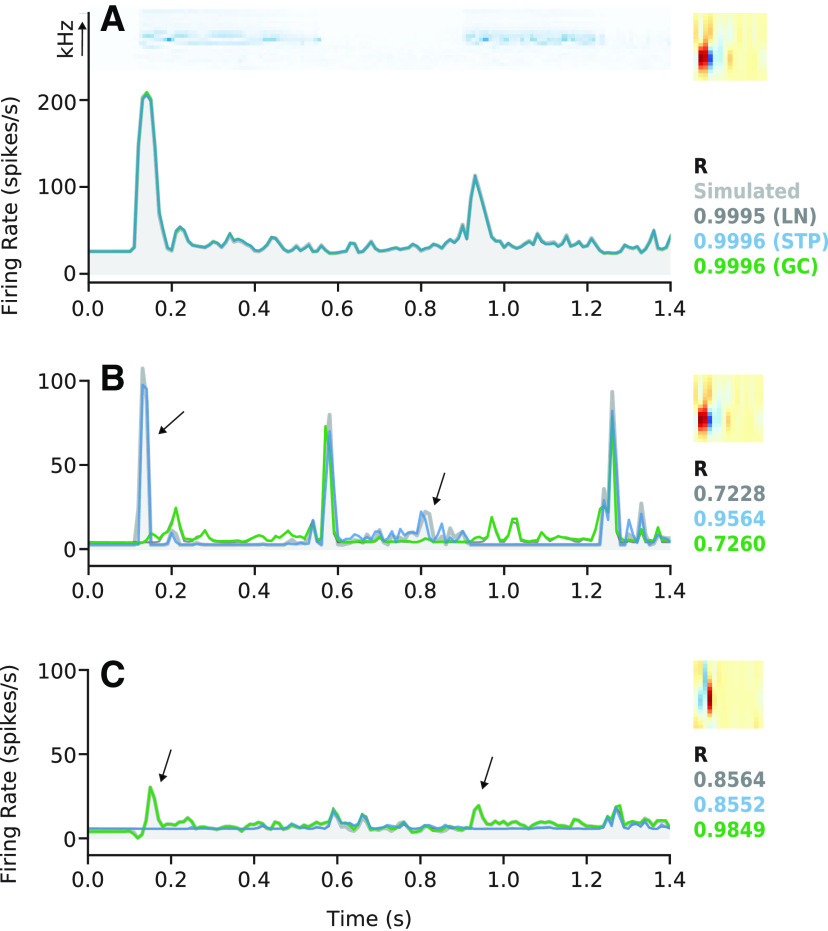
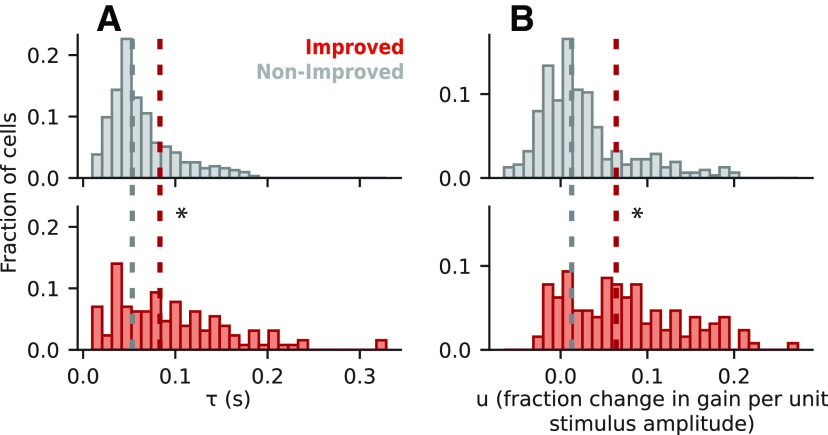
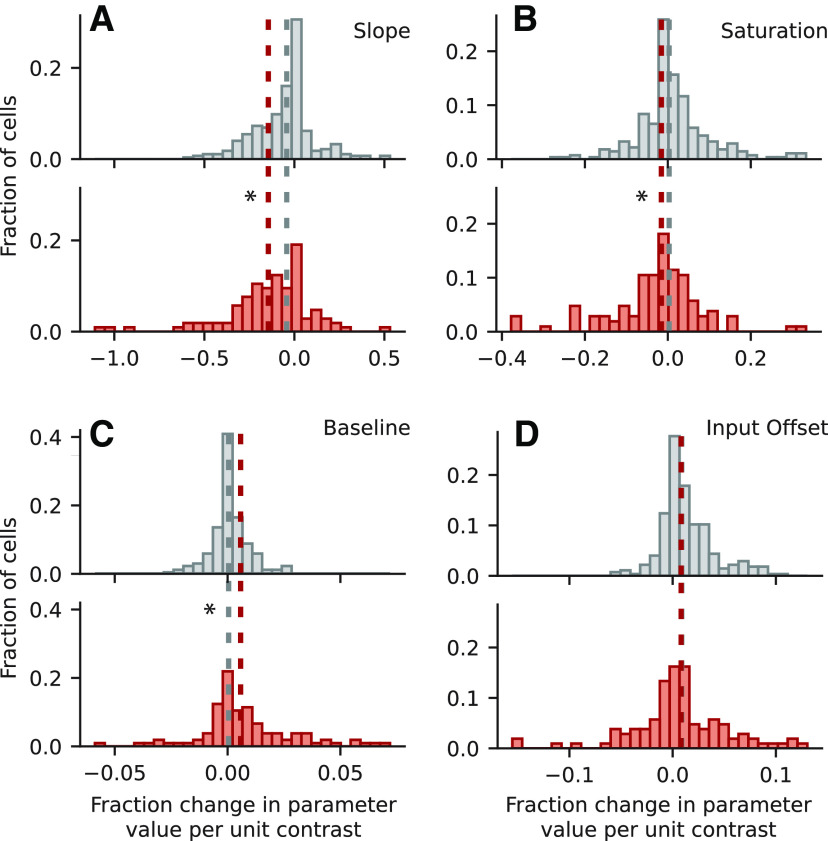
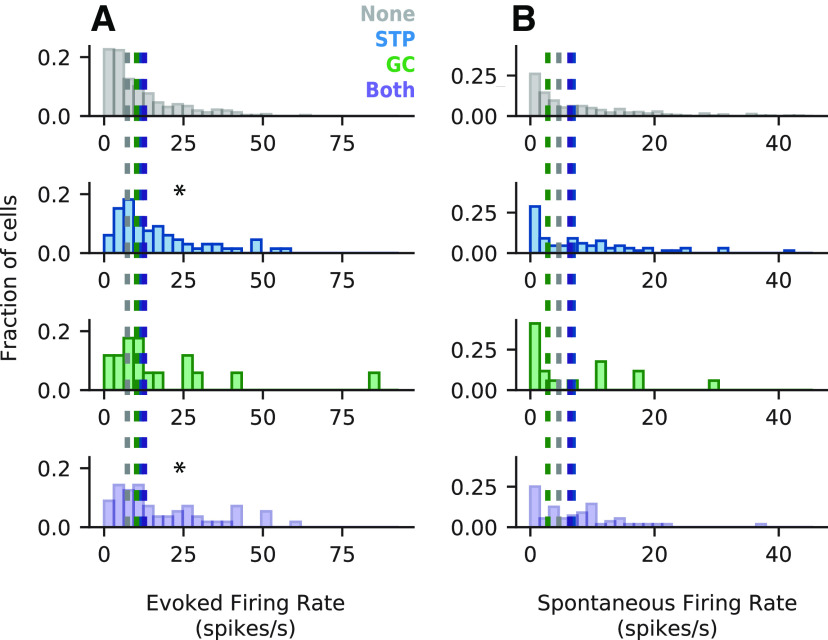
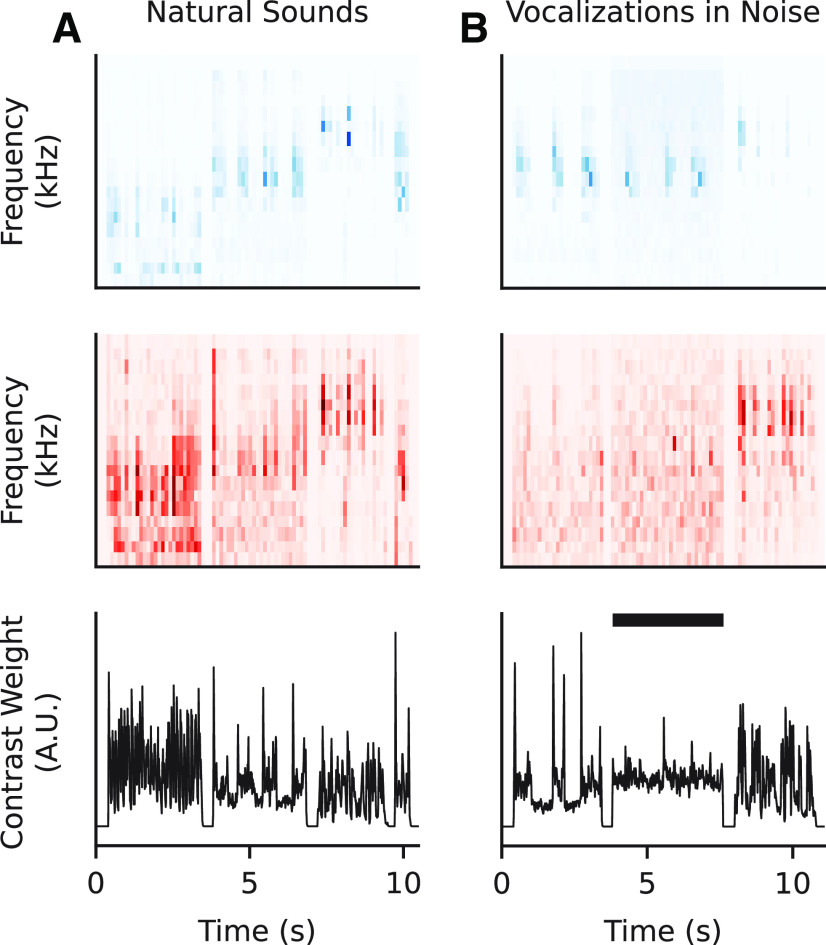
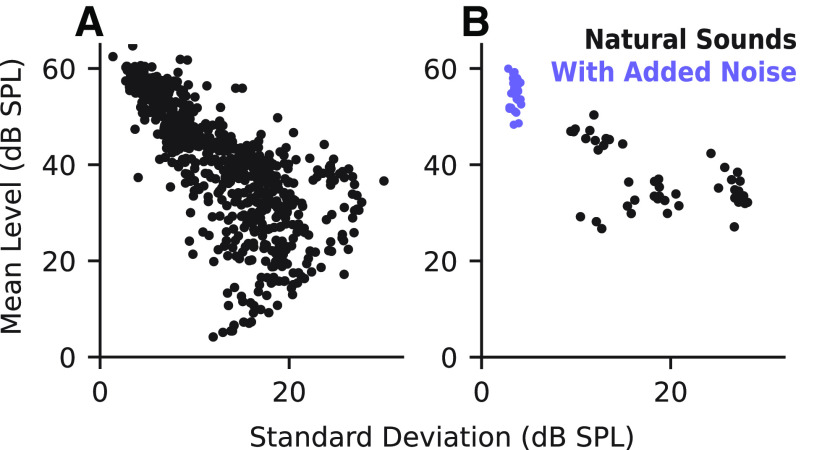
An important step toward understanding how the brain represents complex natural sounds is to develop accurate models of auditory coding by single neurons. A commonly used model is the linear-nonlinear spectro-temporal receptive field (STRF; LN model). The LN model accounts for many features of auditory tuning, but it cannot account for long-lasting effects of sensory context on sound-evoked activity. Two mechanisms that may support these contextual effects are short-term plasticity (STP) and contrast-dependent gain control (GC), which have inspired expanded versions of the LN model. Both models improve performance over the LN model, but they have never been compared directly. Thus, it is unclear whether they account for distinct processes or describe one phenomenon in different ways. To address this question, we recorded activity of neurons in primary auditory cortex (A1) of awake ferrets during presentation of natural sounds. We then fit models incorporating one nonlinear mechanism (GC or STP) or both (GC+STP) using this single dataset, and measured the correlation between the models' predictions and the recorded neural activity. Both the STP and GC models performed significantly better than the LN model, but the GC+STP model outperformed both individual models. We also quantified the equivalence of STP and GC model predictions and found only modest similarity. Consistent results were observed for a dataset collected in clean and noisy acoustic contexts. These results establish general methods for evaluating the equivalence of arbitrarily complex encoding models and suggest that the STP and GC models describe complementary processes in the auditory system.
理解大脑如何表示复杂的自然声音的一个重要步骤是通过单个神经元开发精确的听觉编码模型。一个常用的模型是线性-非线性谱时接收域(STRF;LN 模型)。LN 模型解释了听觉调谐的许多特征,但它不能解释感觉上下文对声音诱发活动的持久影响。两种可能支持这些上下文效应的机制是短期可塑性(STP)和对比依赖增益控制(GC),这两种机制激发了 LN 模型的扩展版本。这两种模型都比 LN 模型的性能有所提高,但它们从未被直接比较过。因此,不清楚它们是否解释了不同的过程,或者以不同的方式描述了一种现象。为了解决这个问题,我们在清醒的雪貂的初级听觉皮层(A1)记录自然声音呈现期间神经元的活动。然后,我们使用这个单一数据集拟合包含一个非线性机制(GC 或 STP)或两者(GC+STP)的模型,并测量模型预测与记录的神经活动之间的相关性。STP 和 GC 模型的性能都明显优于 LN 模型,但 GC+STP 模型优于两个单独的模型。我们还量化了 STP 和 GC 模型预测的等价性,发现只有适度的相似性。在清洁和嘈杂的声学环境中收集的数据集上观察到了一致的结果。这些结果为评估任意复杂编码模型的等价性建立了一般方法,并表明 STP 和 GC 模型描述了听觉系统中的互补过程。