Faculty of Medicine, University of Southampton, Southampton, UK.
Present Address: Department of Pathology and Data Analytics, University of Leeds, Leeds, UK.
BMC Med Res Methodol. 2020 Oct 30;20(1):269. doi: 10.1186/s12874-020-01092-x.
Meta-analyses of studies evaluating survival (time-to-event) outcomes are a powerful technique to assess the strength of evidence for a given disease or treatment. However, these studies rely on the adequate reporting of summary statistics in the source articles to facilitate further analysis. Unfortunately, many studies, especially within the field of prognostic research do not report such statistics, making secondary analyses challenging. Consequently, methods have been developed to infer missing statistics from the commonly published Kaplan-Meier (KM) plots but are liable to error especially when the published number at risk is not included.
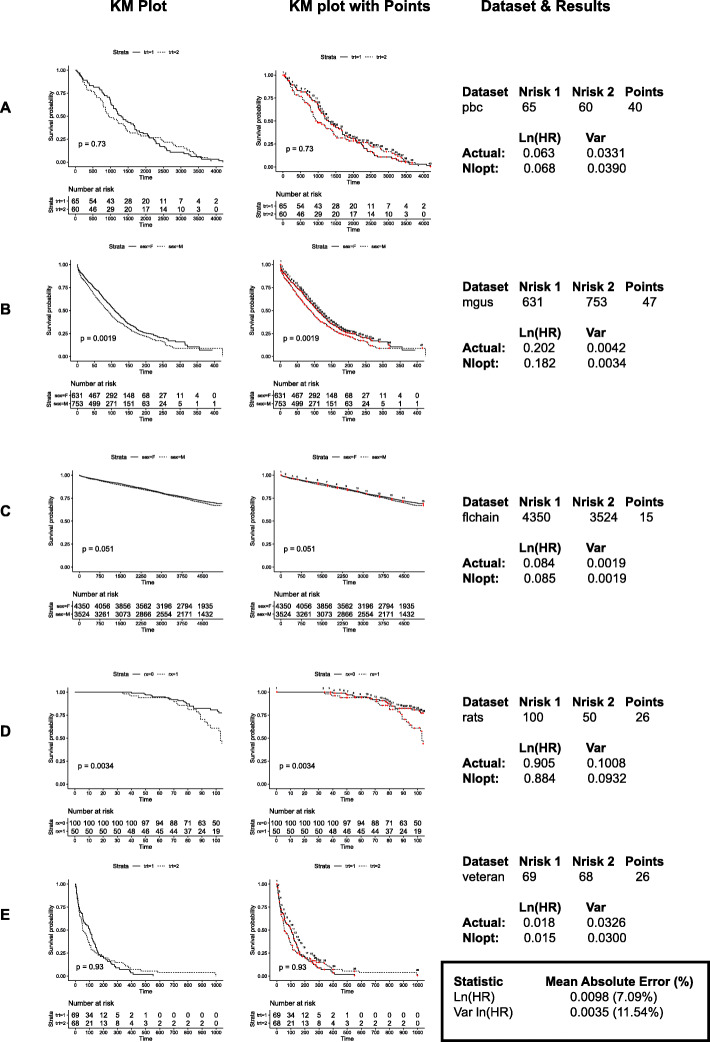
We therefore developed a method using non-linear optimisation (nlopt) that only requires the KM plot and the commonly published P value to better estimate the underlying censoring pattern. We use this information to then calculate the natural logarithm of the hazard ratio (ln (HR)) and its variance (var) ln (HR), statistics important for meta-analyses.
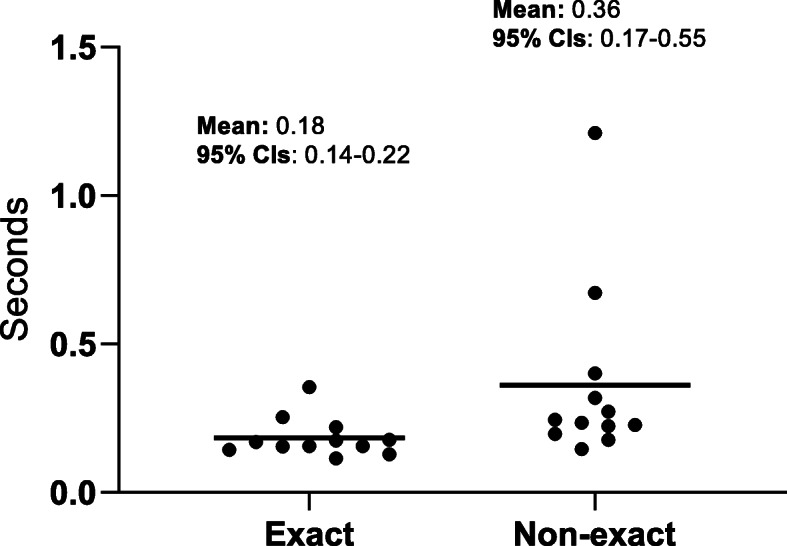
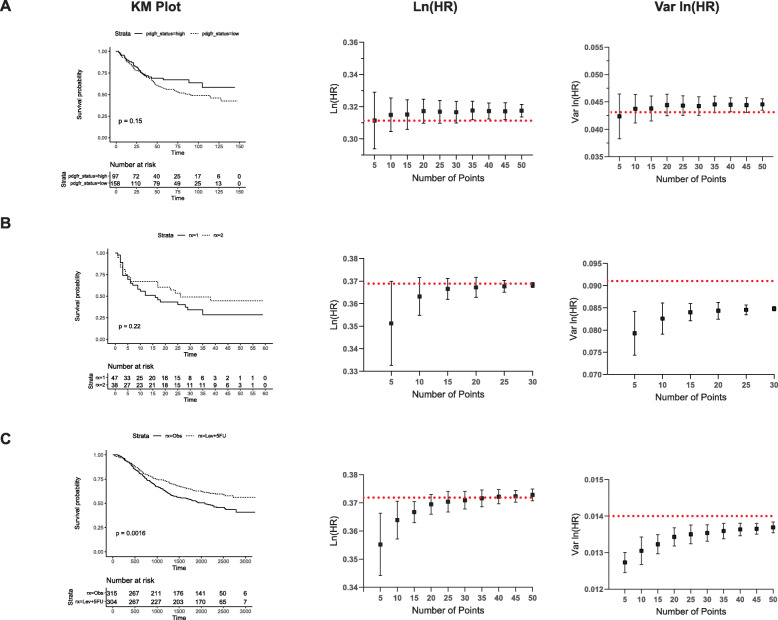
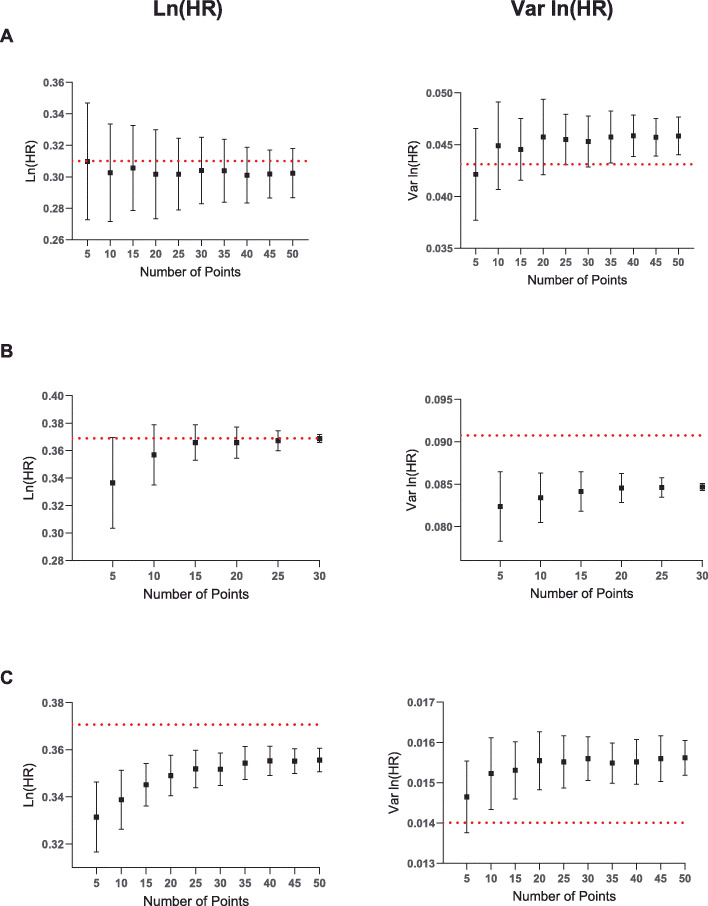
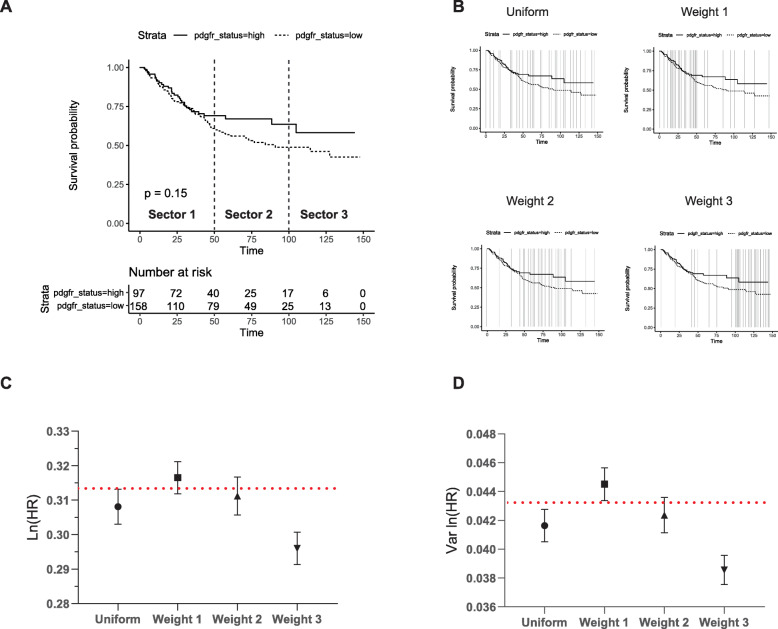
We compared this method to the Parmar method which also does not require the number at risk to be published. In a validation set consisting of 13 KM studies, a statistically significant improvement in calculating ln (HR) when using an exact P value was obtained (mean absolute error 0.014 vs 0.077, P = 0.003). Thus, when the true HR has a value of 1.5, inference of the HR using the proposed method would set limits between 1.49/1.52, an improvement of the 1.39/1.62 limits obtained using the Parmar method. We also used Monte Carlo simulations to establish recommendations for the number and positioning of points required for the method.
The proposed non-linear optimisation method is an improvement on the existing method when only a KM plot and P value are included and as such will enhance the accuracy of meta-analyses performed for studies analysing time-to-event outcomes. The nlopt source code is available, as is a simple-to-use web implementation of the method.
评估生存(时间事件)结局的荟萃分析是评估特定疾病或治疗方法证据强度的有力技术。然而,这些研究依赖于源文章中充分报告汇总统计数据,以方便进一步分析。不幸的是,许多研究,尤其是预后研究领域的研究,没有报告这些统计数据,使得二次分析具有挑战性。因此,已经开发了一些方法从常见的发表的 Kaplan-Meier(KM)图中推断缺失的统计数据,但这些方法容易出错,特别是当发表的风险人数不包括在内时。
因此,我们开发了一种使用非线性优化(nlopt)的方法,该方法仅需要 KM 图和常见的发表的 P 值,以更好地估计潜在的删失模式。我们利用这些信息来计算对数风险比(ln(HR))及其方差(var)ln(HR),这些统计数据对于荟萃分析很重要。
我们将这种方法与 Parmar 方法进行了比较,Parmar 方法也不需要发表风险人数。在一个由 13 项 KM 研究组成的验证集中,当使用精确的 P 值时,计算 ln(HR)的统计学显著改善(平均绝对误差 0.014 与 0.077,P = 0.003)。因此,当真实的 HR 值为 1.5 时,使用建议方法推断 HR 的值将在 1.49/1.52 之间设置限制,这比使用 Parmar 方法获得的 1.39/1.62 限制有所改善。我们还使用蒙特卡罗模拟来确定方法所需的点数和位置的建议。
当仅包含 KM 图和 P 值时,所提出的非线性优化方法是现有方法的改进,因此将提高对分析时间事件结局的研究进行荟萃分析的准确性。nlopt 源代码和方法的简单易用的网络实现都可用。