Visual Neuroscience Group, School of Psychology, University of Nottingham, NG7 2RD Nottingham, United Kingdom;
Experimental Psychology, University College London, WC1H 0AP London, United Kingdom.
Proc Natl Acad Sci U S A. 2020 Dec 22;117(51):32791-32798. doi: 10.1073/pnas.2006192117. Epub 2020 Dec 8.
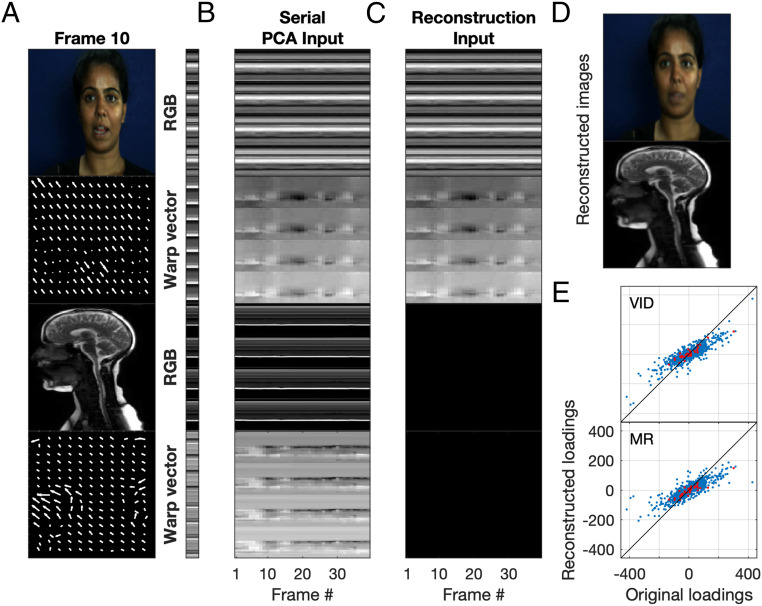
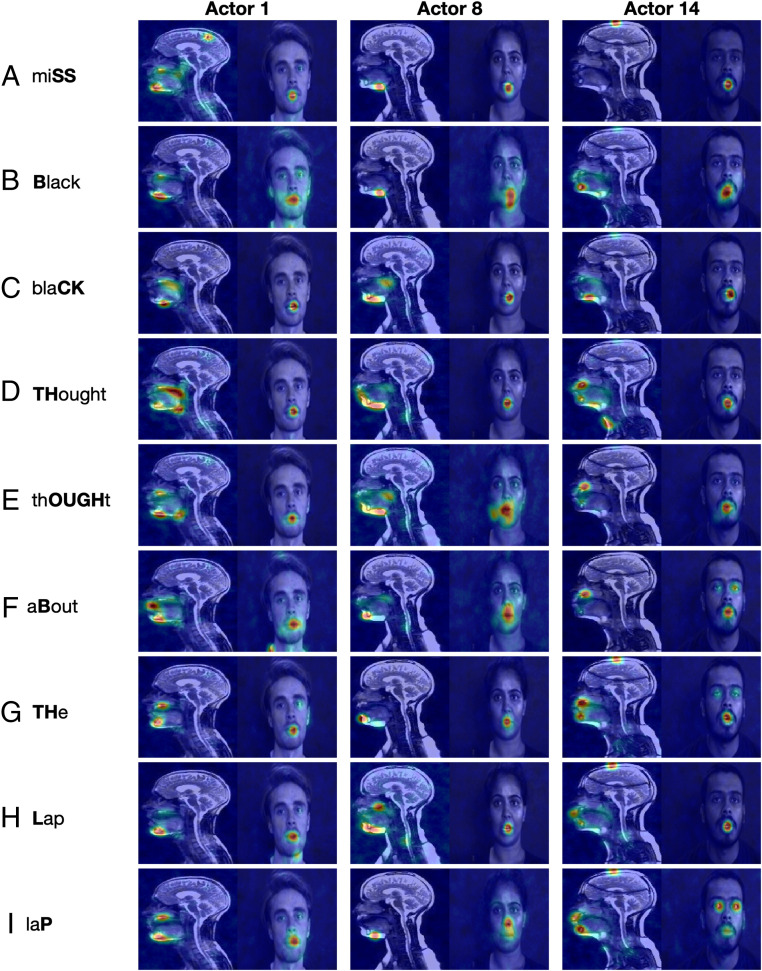
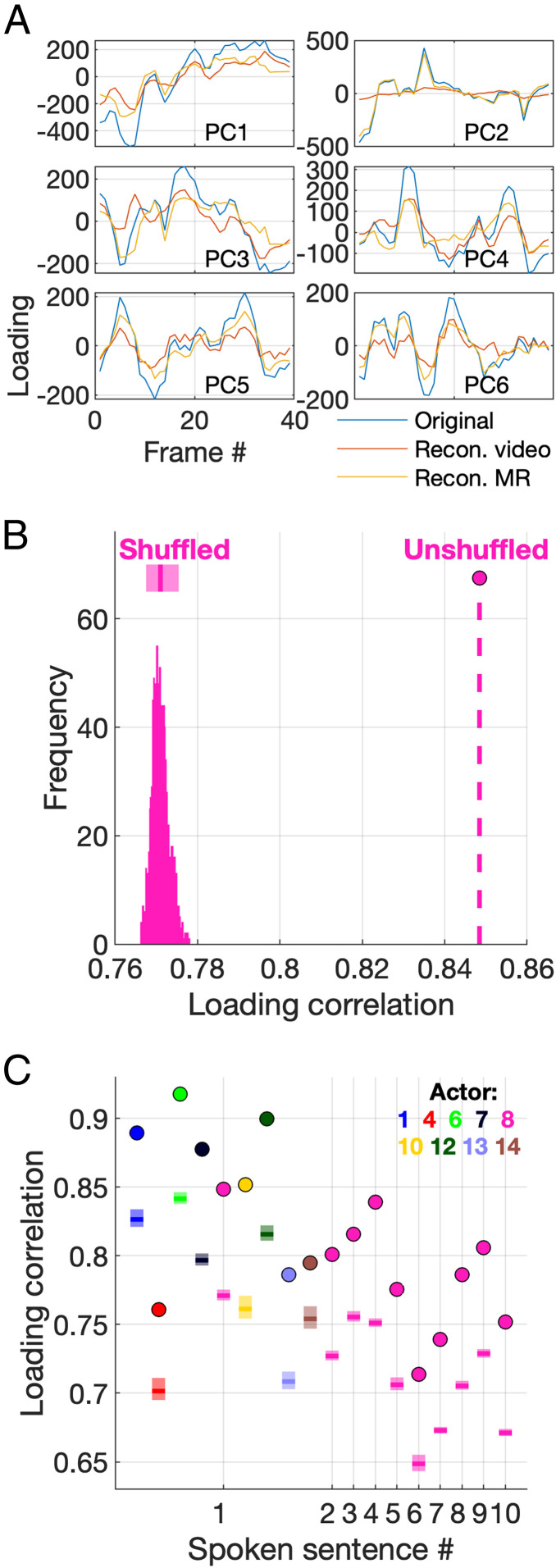
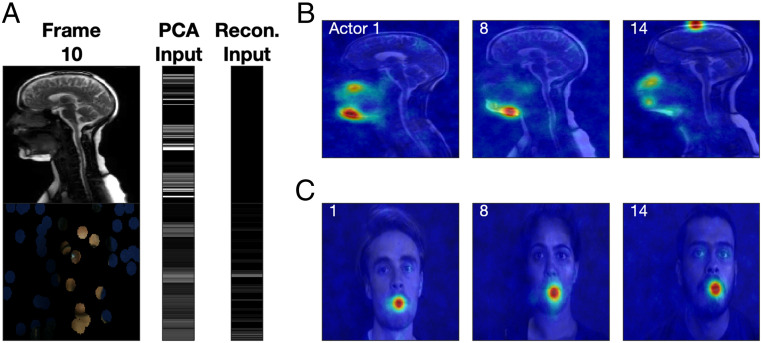
It is well established that speech perception is improved when we are able to see the speaker talking along with hearing their voice, especially when the speech is noisy. While we have a good understanding of where speech integration occurs in the brain, it is unclear how visual and auditory cues are combined to improve speech perception. One suggestion is that integration can occur as both visual and auditory cues arise from a common generator: the vocal tract. Here, we investigate whether facial and vocal tract movements are linked during speech production by comparing videos of the face and fast magnetic resonance (MR) image sequences of the vocal tract. The joint variation in the face and vocal tract was extracted using an application of principal components analysis (PCA), and we demonstrate that MR image sequences can be reconstructed with high fidelity using only the facial video and PCA. Reconstruction fidelity was significantly higher when images from the two sequences corresponded in time, and including implicit temporal information by combining contiguous frames also led to a significant increase in fidelity. A "Bubbles" technique was used to identify which areas of the face were important for recovering information about the vocal tract, and vice versa on a frame-by-frame basis. Our data reveal that there is sufficient information in the face to recover vocal tract shape during speech. In addition, the facial and vocal tract regions that are important for reconstruction are those that are used to generate the acoustic speech signal.
已经证实,当我们能够看到说话者说话的同时听到他们的声音时,尤其是在语音嘈杂的情况下,语音感知会得到改善。虽然我们很清楚语音整合发生在大脑的哪个部位,但不清楚视觉和听觉线索是如何结合起来提高语音感知的。一种说法是,整合可以发生在视觉和听觉线索都来自于一个共同的发生器:声道。在这里,我们通过比较面部视频和快速磁共振(MR)声道图像序列,研究在言语产生过程中面部和声道运动是否相关。使用主成分分析(PCA)的应用程序提取了面部和声道的联合变化,我们证明仅使用面部视频和 PCA 就可以非常准确地重建 MR 图像序列。当两个序列中的图像在时间上对应时,重建保真度显著提高,并且通过组合连续帧来包含隐含的时间信息也会导致保真度显著提高。使用“Bubbles”技术来识别在逐帧基础上对面部哪些区域对恢复声道信息重要,反之亦然。我们的数据表明,在说话过程中,面部有足够的信息来恢复声道形状。此外,对面部和声道进行重建的重要区域是那些用于生成声学语音信号的区域。